python科学计算_python科学计算Numpy包使用
Numpy包是一个用于科学计算的第三方python包,使用Numpy包可以实现Python几乎所有的数据操作,此外有些更新的工具包(如pandas等)都是围绕NumPy数组构建的。本节将提供一些使用NumPy数组操作来访问数据和子数组,以及分割、重新塑造和连接数组的示例。
首先是调用Numpy包及查看版本
import numpynumpy.__version__另外常用简写命令调用
import numpy as np一、构建数组
1.1 从python列表中创建数组
与python list不同,Numpy要求数组中的数据格式必须保持一致,否则将会自动转换。下面是一些例子
np.array([3.14, 4, 2, 3])out: array([ 3.14, 4. , 2. , 3. ])np.array([1,"2",3,4])out: array(['1', '2', '3', '4'], dtype=')可以通过dtype定义
np.array([1, 2, 3, 4], dtype='float32')另外,不同于python list,Numpy数组可以是多维数据。

1.1 Numpy常用命令创建数组
np.zeros() 创建含0数组

np.ones() 创建 含1数组

np.full() 创建包含同样元素的数组

np.arange()及np.linspace()构建等差数列的数组


np.random.random() 、np.random.normal()、np.random.randint()创建由随机数构成数组。
NumPy标准数据类型

二、Numpy数组基础操作
基础的数组操作包括:
Attributes of arrays(数组属性):决定了数组大小、形状、内存好用及数据类型等
Indexing of arrays(数组索引):可获取或设置单个数组元素的值
Slicing of arrays(数组切片):在大数组中获取或设置小数组
Reshaping of arrays(数组重构): 改变数组形状(shape)
Joining and splitting of arrays(合并及分割数组):合并多个数组,或将数据拆分成多个
2.1 数组常见属性
ndim (the number of dimensions), shape (the size of each dimension), size (the total size of the array), and dtype(the data type of the array).

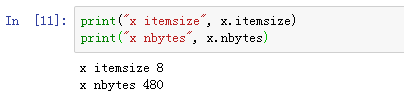
其他常见属性还包含itemsize(lists the size (in bytes) of each array element), 以及nbytes(lists the total size (in bytes) of the array).
2.2 数组索引--访问数组元素

针对多维数组

可以通过数组索引改变元素值,要注意修改后的数据属性要与原数据保持一致,否则会报错或数据自动调整至与原数组元素属性一致。

2.3 数组切片--访问子数组
运行模式:x[start:stop:step]
一维数组

多维数组

直接赋值给新数组 x=y, 改变其中一个数组的元素,另一个数组也会相应进行变化。用x=y.copy(),改变一个数组元素不会引起另一个数组的变化。
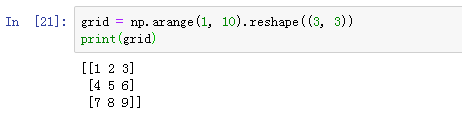
2.4 数组重构
数据重构可通过reshape命令实现,具体参照如下示例:
2.5 数组合并及拆分
2.5.1数组合并常用函数
np.concatenate, np.vstack, and (vertical stack)np.hstack(horizontal stack) , np.concatenate(数组维度必须一致)

np.vstack()、np.hstack()、np.dstack()

2.5.2 数组拆分常用函数
np.split, np.hsplit, and np.vsplit,示例如下:

如上面示例,split会依据所给的N个分割点,产生N+1个子数组。np.hsplit、np.vsplit使用方法类似,np.hsplit案列进行切割,np.vsplit暗行进行切割。

三、Numpy函数
3.1 常用算数函数
如下表格中列出了一些常用的算术函数

求绝对值:np.absolute() or np.abs()
求对数计算:np.log()、np.log2()、np.log10()
下文中以一些例子来说明这些函数的使用
1)指数计算

2)对数计算
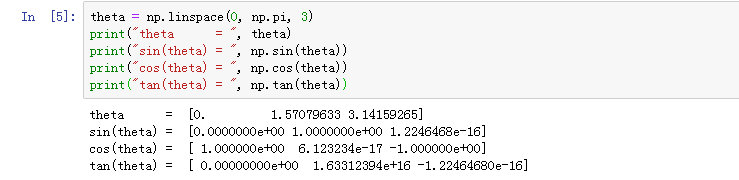
3.2 三角函数
3.3 总计(Aggregations)
1)reduce方法 reduce方法对数组的元素进行给定的重复操作,直到得到一个结果。

上图中例子分别实现x中元素累加或累乘。
2) accumulate方法 accumulate方法与reduce方法类似,但可以保留每个中间结果。

*以上方法的替代函数:np.sum, np.prod, np.cumsum, np.cumprod
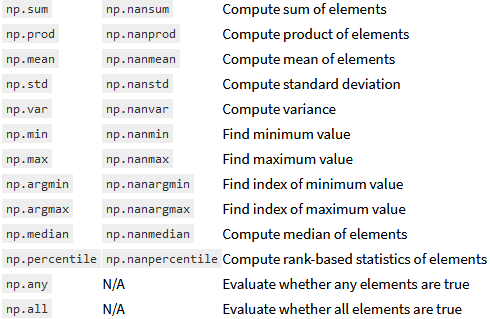
3)其他常用统计函数
四、Numpy Broadcasting
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。如果计算中的两个数组 a 和 b 形状相同,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。如果2 个数组的形状不同时,numpy 将自动触发广播机制。下面是几个例子:
例1)

例2)

例3)

以上示例的图示原理如下:

根据以上例子,我们可以总结出Numpy 广播所遵循的规则如下:
让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
输出数组的形状是输入数组形状的各个维度上的最大值。
如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
六、Numpy 比较与布尔逻辑
6.1 比较操作符
第四部分中我们介绍了Numpy常用的加减计算。除了常规的算术运算外,Numpy同时还能实现比较操作,如(大于)等,这些比较运算通常会得到是一个布尔数据类型的数组。


常用的6项比较操作符如下:

下面是一个二维数组运算示例
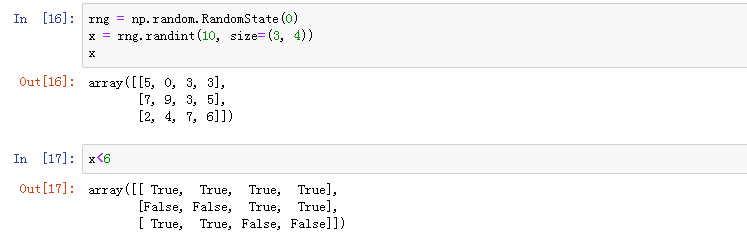
6.2 布尔数组操作
6.2.1 统计布尔数组中真值
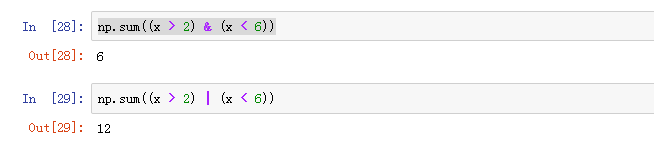
np.count_nonzero()、np.sum()计算布尔数据组“True”值的数目

还可以按照行或列进行统计

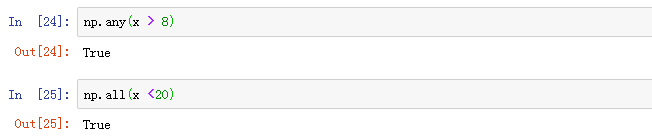
np.any()可用于快速检测是否有值为真;np.all()可以分别用于判断是否所有值都为真
6.2.2 布尔数组操作

6.2.3 布尔数组作为掩码
可以使用布尔数组作为掩码,来筛选数据本身的特定子集。masking操作返回的是一个一维数组,其中包含满足此条件的所有值,换句话说,掩码数组包含True的位置上的所有值。示例如下:

6.2.4 and /or与&/| 的区别
有一个比较容易混淆的点是and和or与操作符&和|之间的区别,两类的区别在于and和or对整个对象执行一个布尔值计算,而&和|对对象的内容(单个位或字节)执行多个布尔值计算。
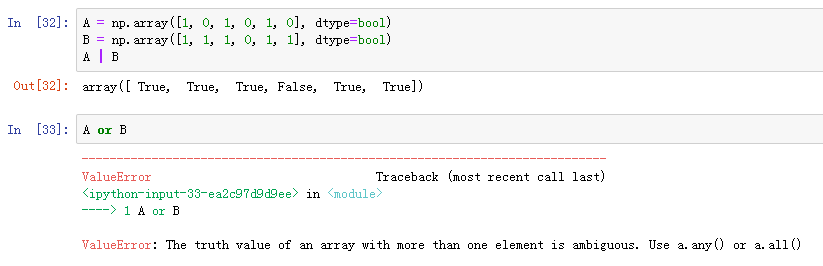
类似地,当对给定数组执行布尔表达式时,应该使用| 或 &而不是or或 and。
七、复杂索引(Fancy Indexing)
7.1 复杂索引介绍
复杂索引的概念很简单:它意味着利用索引数组来同时访问多个数组元素。花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行,如下图示例。

7.2 组合索引

我们还可以将花式索引与切片结合起来使用

7.3 利用花式索引改变数值
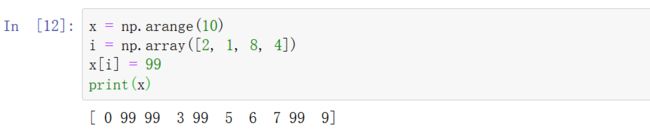
八、数组排序
8.1 利用np.sort 及 np.argsort进行快速排序
Numpy 数据排序常用两个函数:np.sort & np.argsort。np.sort可在不修改输入的情况下返回数组的排序结果。

如果你希望直接对数组进行排序,可以使用sort方法:
此外argsort反馈排序后的index值,如下示例:

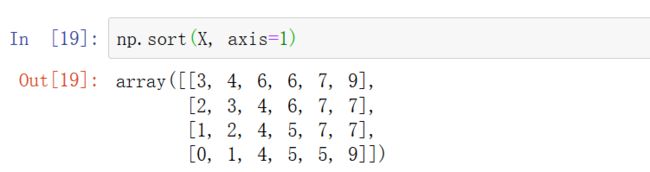
8.2 按照行/列进行数组排序
按列对数组进行排序

按行对数组进行排序
8.3 部分排序
np.partition输入为数组及k(元素数目),会将最小的k个元素放在数组左侧,其余元素放在另一侧。如下示例:

参考资料:
1.Python Data Science Handbook
2.NumPy 教程
欢迎关注生信人
点击以下「关键词」,查看往期内容:
TCGA | 小工具 | 数据库 |组装| 注释 | 基因家族 | Pvalue
基因预测 |bestorf | sci | NAR | 在线工具 | 生存分析 | 热图
生信不死 | 初学者 | circRNA | 一箭画心| 十二生肖 | circos
舞台|基因组 | 黄金测序 | 套路 | 杂谈组装 | 进化 | 测序简史
