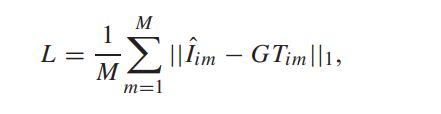【论文笔记(4)】MV-GNN: Multi-View Graph Neural Network for Compression Artifacts Reduction
MV-GNN: Multi-View Graph Neural Network for Compression Artifacts Reduction
- 摘要
- 简介
- 相关工作
-
- 单幅图像压缩伪影的减少
- 多幅图像压缩伪影的减少
- 图卷积神经网络
- 总结
- 方法
-
- 问题描述
- 特征提取网(FENET)
- 基于GNN的动态融合网
- 重构网
摘要
在许多面向交互的3D视觉应用中,多视点视频(MVV)中不可避免的压缩伪影会明显降低体验质量。
在非对称编码的框架下,考虑到不同视点之间的相似性,利用相邻视点的高质量图像对低质量图像进行增强。
然而,压缩伪影和翘曲误差会导致不同序列的横视质量差距不同,本文提出了一种多视点图神经网络(MV-GNN)来减少多视点压缩图像中的压缩伪影。既能利用相邻视点的贡献,又能抑制误导信息。
在我们的方法中,设计了一种基于GNN的融合机制,在GNN的聚合和更新机制下对横视信息进行融合。
实验表明,压缩图像中的分块效应得到明显抑制,受损目标边界得到较好的恢复。
简介
多视点视频(Multi-view video,MVV)[1]已经被许多三维和面向交互的视觉应用采用作为基本的数据表示,它可以提供场景的身临其境的感知观看体验[2]、[3]。
然而,对于那些基于多视点视频的系统来说,大量的冗余数据一直是一个挑战,它们需要有效的压缩技术来传输。
然而,如图1所示,压缩伪影(例如,块伪影、模糊、噪声混叠效果等)。这是不可避免的,可能会对视觉质量和用户体验产生重大影响,特别是当带宽限制是应用程序设计中的主要问题时。
在过去的几十年里,许多工作都集中在对失真图像的压缩伪影的减少上。
我们提出了一种多视点图神经网络(MV-GNN)来解决MVV中压缩伪影减少的挑战。
总结我们的工作,我们首先自适应地利用多视图先验知识,通过设计端到端的残差网络来减少压缩后的MVV图像中的压缩伪影。
该网络采用多尺度残差块检测HEVC压缩图像在不同尺度下的特征映射,为后续的特征融合提供更具代表性的信息。
在自适应的基础上,提出了一种基于GNN的融合机制,以更好地重建MVV中的多视点先验。
在该机制中,在多视图融合特征图上构造K-近邻图。
然后利用GNN的聚集和更新机制,自适应地从压缩的MVV中挖掘有用的先验,同时抑制误导先验。
相关工作
压缩伪影的减少方法可以分为两类:单图像方法和多图像方法。
单幅图像方法,所设计的模型只涉及重建图像本身。
多幅图像方法利用了多个先验知识,可以考虑视点内或视点间的相似性。
单幅图像压缩伪影的减少
在这些方法中,早期的工作主要是针对传统的特殊设计的滤波器。
例如,Liew等人。[21]使用基于小波的去块方法减少了块效应和振铃效应。
FOI等人。[6]设计了一种形状自适应离散余弦变换(DCT)模型,以减小JPEG压缩引起的块效应。
后来,Jancsary et al.。[22]提出了一种基于回归树域(RTF)的非参数图像恢复框架。
此外,利用稀疏编码去除JPEG伪影[9]-[11]。
例如,Chang等人。[10]提出了一种基于字典学习的JPEG图像两步解压缩算法。
近年来,基于CNN的算法在减少失真图像的压缩伪影方面表现出了优异的性能。
例如,董等人。[12]首先提出了一种针对JPEG压缩图像的去伪影CNN(ARCNN)算法。
作为推广,Dai et al.。[13]提出了一种变滤波器大小残差学习细胞神经网络(VRCNN)来代替H.265/HEVC帧内编码中的环内滤波器。
另外,Yang等人还提出了一种解码器侧可伸缩的CNN方法(DSCNN)。[23]其中使用两个子网分别减少帧内编码和帧间编码的伪影。
他们扩展了他们在[24]中的工作,引入了一种时间受限的质量增强优化方案来控制计算时间。
在文献[25]中,Wang et al.。提出了一种基于深度CNN的自动解码器(DCAD)来去除HEVC压缩图像中的伪影。
DnCNN在[26]中是一种用于图像恢复的去噪卷积神经网络,包括JPEG压缩还原任务。
此外,一些方法还考虑了来自编码技术的压缩信息。
例如,张等人。[27]提出了一种双域多尺度细胞神经网络JPEG伪影去除算法,该算法同时利用像素域和DCT域的信息。
在[28]中,他等人。利用编码器产生的CU分区信息来指导质量增强过程。此外,生成性对抗性网络(GAN)[29]已被广泛用于预测视觉上令人愉悦的纹理和减少压缩伪影。
设计了一种生成式网络,以产生对抗性网络难以与原始网络区分的增强结果[30]-[32]。
虽然上述方法对降低单幅压缩图像的压缩伪影是有效的,但在没有利用视点间相似性的情况下,它们对压缩多视点视频的增强性能是有限的
多幅图像压缩伪影的减少
对于这些方法,基于多视图或多帧的相关性,多幅图像可以提供更多的先验信息来提高压缩视频的质量。
不同的多图像融合方法有不同的特征融合机制。
一方面,首先将多幅图像拼接在一起,然后发送到卷积网络。
例如,谢等人。[14]提出了一种全卷积神经网络对3D视频中低分辨率图像进行上采样。
在他们的工作中,他们使用来自相邻高分辨率图像的投影图像信息重建低分辨率图像。
在[15]中,将相邻视点的图像和当前视点的合成图像直接拼接成一个四层CNN,以提高合成视图的质量。
另一方面,特征地图被单独提取,然后由CNN进行融合。
在[16]中,Yang et al.。提出了一种压缩视频的多帧质量增强(MFQE)方法。
此外,他们还提出了一种具有双向递归结构的质量门控卷积长短期记忆(QG-ConvLSTM)[33]网络,以利用大范围帧中的有利信息。
在[34]中,Lu et al.。发展了一种质量增强网络(QENet),该网络在空间上利用各自多尺度卷积产生的空间和时间先验,并在时间上以递归机制扭曲时间预测。
在[35]中,Xu et al.。提出了一种减少视频压缩伪影的非局部ConvLSTM算法,该算法引入了一种近似的非局部策略来捕获全局运动模式,并跟踪视频序列中的时空相关性。
这些多图像方法主要是针对利用N幅高质量图像来改善一幅低质量图像,也有一些工作是通过引入另一种或相同的CNN模型来同时增强N幅压缩失真图像[16]、[36],这是压缩视频增强的另一种趋势。
然而,由于压缩伪影和翘曲误差,交叉视点先验并不总是有用的,特别是在不同的编码条件下会产生更多的不可预测性。
现有的MVV压缩方法不能自适应地利用有价值的先验信息,同时不能抑制来自不同失真多视角图像的误导先验信息。
由于GNN具有良好的关系推理和归纳偏差能力,可以在不同的编码条件下进行自适应调整,从而挖掘出更有价值的交叉视图先验知识。
因此,我们提出了一种基于GNN的融合机制来融合多视点特征地图。
图卷积神经网络
GNN的概念首先在[37]中概述,并在[18]中进一步阐述,它使用神经网络来处理图域中的数据。
图神经网络主要利用邻域聚合框架进行表示学习,通过递归聚合和变换邻域节点的特征来更新节点特征。
GNN主要有两类:基于频谱的和基于空间的。对于第一种方法,利用拉普拉斯图[38]-[40],在谱域采用卷积神经网络。
对于第二种方法,这些方法将图卷积表示为聚集来自邻居的特征信息,从而递归地将神经网络应用于图的每个节点[41]-[43]。
在这一部分中,我们将简要介绍基于空间的GNN及其在图像处理中的应用。
GNN中的输入数据被构造为图G={V,E},其中V和E是节点和边的集合。
GNN的目标是学习每个节点p∈V的状态hp,该状态包含相邻节点q的信息。在时间t,htp可以更新为:
 其中M是相邻消息的聚集。
其中M是相邻消息的聚集。
基于聚集和更新函数M和F递归地更新图中所有节点的隐藏表示。
M和F中的参数在传播过程之间共享。
近年来,计算机视觉在[19]、[20]、[44]、[45]等方面有很多应用。
例如,梁等人。[19]提出了一种用于语义对象解析的图LSTM,该方法以超像素地图为基础构建图,并应用LSTM全局传播邻域信息。
在[20]齐等人的研究中。提出了一种基于3DGNN的RGBD语义分割方法,该方法在三维点云之上建立图形。
它们将每个节点的隐藏状态作为输入,经过几个步骤的展开后预测其语义标签。
这些方法验证了广义神经网络对图像处理任务的益处。
总结
如上所述,这些多图像方法可以提供比单图像方法更有用的先验,因为它们可以考虑不同视点之间的相关性。
然而,以往的多图像算法直接避免了MVV的不良先验,这限制了它们的性能。
在增强压缩的MVV时,如何有效地利用横视先验是一个挑战。
由于GNN擅长关系推理,并在许多图像处理任务中取得了较好的性能,因此利用GNN开发有益先验,同时抑制误导先验在MVV压缩伪影消除中具有广阔的应用前景。
方法
问题描述
我们的目标是减少压缩图像I(i)中的压缩伪影,I(i)的维度为:C×W×H,C是输入图像的通道数。W和H代表宽度和高度。假设共有N个视点,
MV-GNN模型如下:
 图描述了MV-GNN的框架,它由三个子网组成:特征提取网(FENET)、基于GNN的动态融合网和重构网。
图描述了MV-GNN的框架,它由三个子网组成:特征提取网(FENET)、基于GNN的动态融合网和重构网。
FENET将不同视点的重建图像作为输入,得到一组特征地图。
然后,基于GNN的消息传播机制,设计了基于GNN的动态融合网络,设计了一种基于GNN的融合机制,以更好地自适应地利用有益的多视角先验信息。
最后,通过重构网络将融合后的特征映射变换回图像空间。各部分的详细内容将在下面几节中介绍。
特征提取网(FENET)
Fenet用于从重构图像中提取空间特征映射,为基于动态GNN的融合网络中的融合部分提供初始的隐含表示向量。
由于多视点深度视频在3DHEVC框架下与MVV一起被编码,因此使用DIBR[46]中的3D扭曲技术将来自相邻N−1个视点的重建图像{I(1),…,I(i−1),I(i+1),…,I(n)}扭曲到当前视图。
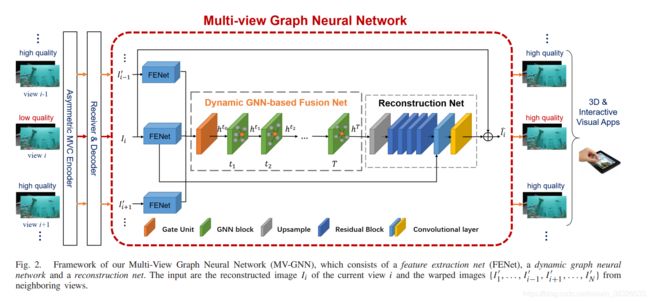
然后将当前视图的N个版本{I(1)’,…,I(i−1)’,I(i+1)’,…,I(n)’}送入FENET以分别获取特征地图,如图3所示。
不同的视点在FENET中共享相同的参数。
如图3所示,设计了两个大小为5×5的卷积层,以获得开始时的浅特征。
然后,考虑到HEVC采用变块大小变换,提出了两个多尺度残差块来提取多尺度特征。
在这些块中设置了3种不同的核大小,包括5×5、3×3和1×1。
PReLU[47]用作激活功能。
另外,由于细节信息在压缩过程中不可避免地会发生失真,我们使用膨胀卷积来扩大特征映射的接受范围。将5×5、3×3和1×1卷积层的膨胀因子分别设为3、2和1。
遵循编解码器网络的概念,采用STRIDE=2的卷积层对特征图进行下采样,既增加了接收范围,又降低了后续处理的计算量。
经过FENET处理后,将其发送到下一小节中描述的后续特征融合部分。
基于GNN的动态融合网
在MV-GNN中,我们提出了一种基于动态GNN的融合网络来从不同的角度递归地挖掘有用的先验。
该特征融合部分采用了门单元和动态GNN块。
1)门单元:由于不同视点之间存在着质量差距,为了融合不同数量的视点,我们首先设计了一个门单元,从这些N视图特征图{fn}nn=1生成1视图特征图。
闸门单元可以表示为:

其中f=[f1,f2,…,fn]表示连接的N视图特征地图。
G由具有64个滤波器数的1×1卷积层和PReLU激活层τ组成。
因此,它接受64N个特征地图并产生64个特征地图。
该单元用于从N个视图学习不同特征映射的自适应权重。这遵循其中权重决定应该保留多少多视图优先的选通机制。
在此初步过程之后,使用动态GNN块来进一步融合多视角先验。
图的构造:在动态GNN块中,为了自适应地评估交叉视点先验的贡献,我们根据f门i中像素的特征相似度构造了图Gf={Vf,Ef}。
在该图中,特征映射f门i中的每个像素p都是图节点。
每个节点之间的连接是基于像素相似性(即相关性)建立的。
在我们的方法中,利用节点p和节点q之间视觉特征空间的差异来评估相关性,其计算公式为||f GATE IP−f GATE IQ||2。
在特征空间中,每个节点只与K个最小距离的节点相连,在后续的实验中,K设为64。
因此,可以将其视为一个在传播过程中动态调整的K邻域图。
这样,在基于CNN的融合方法中,每个节点可以自适应地从动态更新的相邻节点中选择更有用的先验,而不是使用卷积核窗口之间有限的先验。
传播模型:在构建图后,将f门i中每个节点的特征向量作为初始隐含表示H0p。
受[20]、[42]、[45]的启发,该融合部分的传播模型主要包括聚合函数和更新函数两部分,分别定义为。

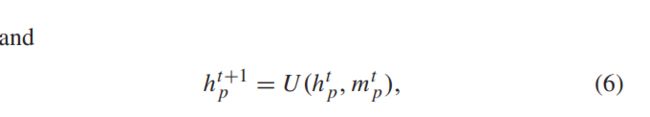
其中p是节点p和节点q∈p的K个邻域节点的集合。
在每个时间步长,每个节点收集来自其相邻相邻节点的聚集消息MTp。
该聚集包括将隐藏状态馈送到多层感知(MLP)g中,然后在邻域上取平均值。
G的输入和输出都是64维向量。
在我们的模型中,MLP由一层PReLU激活组成。
则每个节点使用MTP和其先前的隐藏状态HTP来更新其隐藏状态。
另一个MLP用作更新函数U。
U的输入是128维向量,输出是64维向量。
在图4中总结了动态GNN块中的传播细节。
这样,来自邻居的特征聚合被迭代地执行,并且每个节点的消息被自适应地传播到整个图。
因此,可以在不同的失真条件下自适应地利用多视点先验。
重构网
T次迭代后,
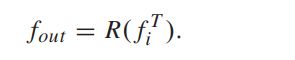
在这一部分中,我们首先使用3×3的反卷积层将fTi向上采样到原始分辨率。
过滤器编号为64,步幅设置为2。
然后进行具有两个3×3卷积层和PReLU激活层的四个剩余块。
残差块的结构如图5所示。
为了防止梯度消失,我们将最后一个残差块的输出与来自FENET的第一卷积层的特征连接起来,这在前面的图3中描述过。
然后将拼接后的特征图送入具有64个滤波数的3×3卷积层。
最后,应用1×1卷积层得到残差图FOUT,然后将残差图Fout与视图I的输入图像相加,得到增强结果ˆII

在训练网络时,采用输出与地面真实数据之间的平均绝对误差(MAE)作为损失函数。