python生成器和迭代器详解
文章目录
- 前言
- 一、迭代器--从一个简单例子入手
-
- 1.1 实现__iter__成为迭代对象
- 1.2 通过实现__next__方法成为迭代器
- 二、生成器 -- 更加简单的迭代器
-
- 2.1来个简单例子
- 2.2 生成器函数yeild
- 2.3 生成器推导式
- 参考文献
前言
python中迭代器和生成器比较抽象,尽量做到通俗易懂。
一、迭代器–从一个简单例子入手
首先,创建一个基础类Dogs,并实例化一个对象,该类希望输出我家有多少条狗。此处我相信大家都能理解。
# 首先创建一个类,实例化一个普通的对象。
class Dogs(object):
def __init__(self,nums): # 我家有nums条狗
self.nums = nums
if __name__ == '__main__':
dogs = Dogs(10)
print(dir(dogs)) # 通过dir查看下对象dogs拥有的方法以及属性,发现没有 __iter__ 方法
通过dir()方法可以看出,dogs类并没有__iter__方法,因此并不是一个迭代对象。在python中,只有实现__iter__方法的才是叫迭代对象。
1.1 实现__iter__成为迭代对象
# 首先创建一个类,实例化一个普通的对象。
class Dogs(object):
def __init__(self,nums): # 我家有nums条狗
self.nums = nums
def __iter__(self): # 通过实现__iter__方法,则对象就成了迭代对象
return self
if __name__ == '__main__':
dogs = Dogs(10)
print(dir(dogs)) # 通过dir查看下对象dogs拥有的方法以及属性,发现没有 __iter__ 方法
此时,通过dir()方法就可以看见dogs有了__iter__方法了,因此,此时已经是迭代对象了。
1.2 通过实现__next__方法成为迭代器
上述仅仅只是一个迭代对象,并不是迭代器;因此,要想成为迭代器,还需要实现迭代器协议:即实现next方法,要么返回下一个元素,要么引起终止迭代。
'''
python中的迭代器和生成器:
迭代器对象 ---实现了迭代器协议的对象;
迭代器协议----
'''
# 首先创建一个类,实例化一个普通的对象。
class Dogs(object):
def __init__(self,nums): # 我家有nums条狗
self.nums = nums
self.start = -1
def __iter__(self): # 通过实现__iter__方法,则对象就成了迭代对象
return self
def __next__(self): # 实现next方法,即迭代器协议;每一次for循环都调用该方法
self.start +=1
if self.start >= self.nums:# 若超出,则停止迭代
raise StopIteration()
return self.start
if __name__ == '__main__':
dogs = Dogs(10)
for dog in dogs:
print(dog)
此时,我们就成功封装出一个迭代器,那么,for就可以根据迭代器协议遍历类中元素。
而dogs就被称之为 实现了迭代器协议的可迭代对象。
现在回头看一下经常用到的list:
for i in [1,2,3]:
print(i)
之所以能够利用for进行遍历,是因为list本身就是一个可迭代对象,内部实质上已经实现了__iter__方法。
二、生成器 – 更加简单的迭代器
生成器实质上依旧是迭代器,只不过python自动让生成器实现了迭代器协议。具体来看生成器的两种用法:yeild 和 生成器表达式。
2.1来个简单例子
假如现在让你实现一个代码:给定一个N,求取N以内的元素的平方。
你会这样写:
def gensquares(N):
res = []
for i in range(N):
print('当前迭代元素为:',i)
res.append(i*i)
return res
for item in gensquares(5):
print(item)
输出的结果为:

可以看出:首先执行了gensquare函数之后,才用for循环输出结果。倘若N足够大,势必会占据大量内存。这时候,你该yeild了。
2.2 生成器函数yeild
def gensquaresv2(N):
for i in range(N):
print('当前的元素为',i)
yield i*i
for item in gensquaresv2(5):
print(item)
代码简单了,在看看输出结果:

很明显,yeild自动实现了迭代,且一次加载一个元素,然后输出;而不是一次性加载,因此,内存占用少,而且代码量少。
为什么说生成器自动实现了迭代器协议?
可以打印一下:
def gensquaresv2(N):
for i in range(N):
print('当前的元素为',i)
yield i*i
print(type(gensquaresv2(5)))
print(dir(gensquaresv2(5)))
for item in gensquaresv2(5):
print(item)
首先gensquaresv2(5)是一个生成器对象。观察他内部实现了__iter__和__next__方法,因此,实质上gensquaresv2(5)实际上就是一个可迭代对象。而for可以依据迭代器协议遍历gensquaresv2(5)中的每个元素。
2.3 生成器推导式
先看一个常见的列表推导式:
squares = [x*x for x in range(5)]
print(squares)
现在将[]变成()就是生成器推导式了:
squares = (x*x for x in range(5))
print(type(squares))
print(next(squares)) # 通过next方法调用生成器一个元素,调用5次next后后会报stopIteration。
print(list(squares)) # 调用过的就不遍历了。
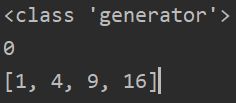
总的来说:生成器自动实现了迭代器协议,而且将输出状态挂起,有延时输出效果。
还有值得注意细节:生成器只能遍历一次,因为遍历完一次后,最终输出状态已经没了。
squares = (x*x for x in range(5))
print(type(squares))
print(next(squares)) # 通过next方法调用生成器一个元素,调用5次next后后会报stopIteration。
print(list(squares)) # 调用过的就不遍历了。已经遍历完全
print(next(squares)) # 由于已经遍历完成,故会输出 stopiteration
参考文献
https://www.zhihu.com/question/20829330/answer/133606850