YOLOv4 darknet windows10版本训练自己的数据教程
转自:[https://blog.csdn.net/ly_twt/article/details/105761312]
https://blog.csdn.net/weixin_40841247/article/details/105742022
https://blog.csdn.net/weixin_44868057/article/details/106498413
https://blog.csdn.net/weixin_38107271/article/details/106478275
YOLOv4 darknet windows10版本训练自己的数据教程
之前看了几篇文章都是用的linux搭建yolov4的darknet,几乎没有看到过windows版本的,在摸索了一个下午之后终于搭建好了并且能够训练自己的数据集。因此作者在这里想写一下自己搭建yolov4的darknet-master的整个过程并训练自己的数据集。
一、windows10环境配置
在搭建yolov4的darknet-master之前,我们需要在windows环境下搭建好VS(2015或2017皆可,作者的是2017)、opencv(4.0),CUDA10.0及对应版本的cudnn,作者在这里只做安装简介,具体请自行csdn查找相关教程。只有保证环境正确才能进行下一步操作。
- VS2017安装 ,百度直接搜索msdn我告诉你;进入后选择开发人员工具里的VS2017下载即可,安装时秩序安装基本的C++库和windows SDK即可。

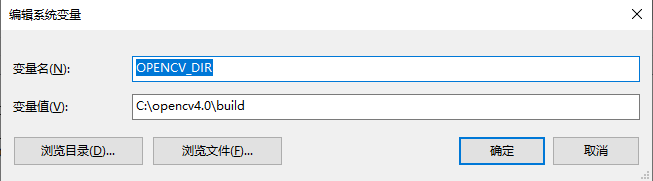
- opencv安装 点击这里进入opencv下载;选择4.0版本下载后得到opencv,双击打开,解压到一个目录得到opencv文件夹,在系统变量中添加如下变量:
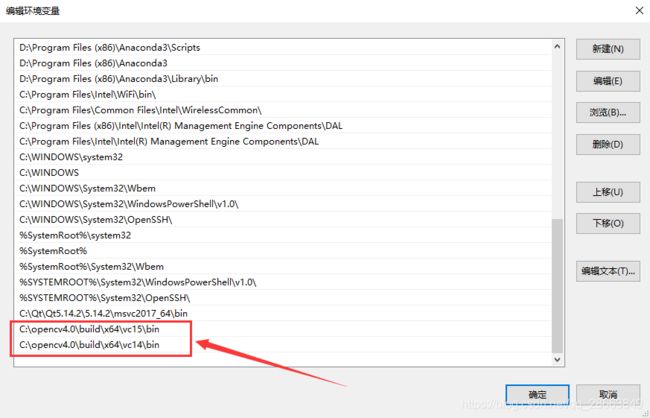
在Path变量中添加如下变量即可:
- CUDA及CUDNN安装 点击这里找到CUDA10.0并下载local(.exe文件),下载后直接双击安装,全部默认设置。点击这里注册并下载对应cuda版本的cudnn压缩包。待cuda安装完成后解压下载的cudnn.zip文件,将解压后文件夹下的文件复制到cuda安装目录相应的文件夹下,如bin-bin,行x64-x64等。cuda的安装会自动添加环境变量。
二、获取yolov4-darknet-master源码
windows建议直接github获取zip文件
点击这里下载darknet的源码压缩文件
源码链接:https://github.com/AlexeyAB/darknet
其实源码的readme.md文件也有具体的编译教程,包括不同的操作系统编译教程。
下载完zip后直接解压到相应文件夹即可,下图是解压后的所有文件:

以文本文件方式打开Makefile文件,修改如下:
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
DEBUG=1
OPENMP=1
LIBSO=1
ZED_CAMERA=1
保存即可
三、使用VS2017编译darknet-master
- 打开vs2017选择daknet.sln并打开
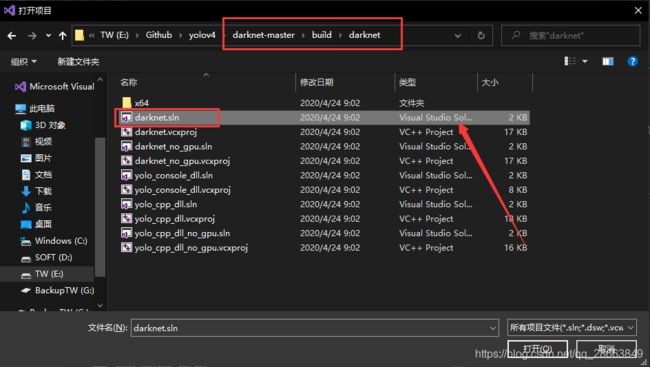
直接点击确定

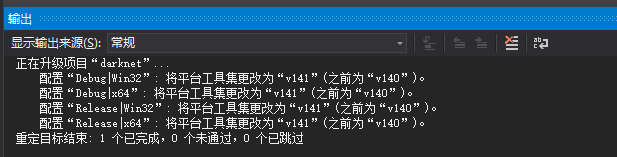
环境没问题会输出这些:
选择release x64模式
右键darknet——生成
如果没有问题则会输出如下信息:
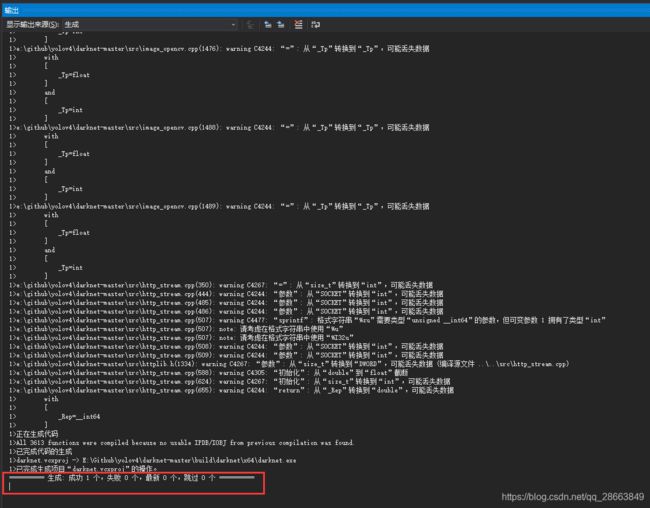
有报错的小伙伴可以邮件([email protected])问我哈,一般都是cuda版本问题,之前我也遇到过。warning不要紧,问题不大,只要能生成就可以。
然后再依次打开相同文件夹下yolo_cpp_dll.sln和yolo_console_dll.sln并且以相同的方式生成即可。
四、测试yolov4的demo
首先你需要yolov4.weight和yolov4.conv.137文件,请自行百度领取:
链接:https://pan.baidu.com/s/1leFA14UQQVStEBKlFnRzVw 提取码:u7k1
将yolov4.weight放入\darknet-master\build\darknet\x64\backup文件夹,yolov4.conv.137直接放在\darknet-master\build\darknet\x64文件夹下
打开cmd进入\darknet-master\build\darknet\x64目录
输入以下命令:darknet.exe detector test data/coco.data cfg/yolov4.cfg backup/yolov4.weights
cmd会输出网络
然后输入图像路径及名称即可得到检测结果:
至此,yolov4已经搭建好了,接下来就是训练自己的数据集了。
五、数据集准备
首先你需要将自己的数据集准备成VOC格式,如下图所示,在darknet-master\build\darknet\x64\data\voc文件夹下建立VOCdevkit/VOC2007文件夹,并且将JPEGImages、Annotations和ImageSets放入VOC2007文件夹下

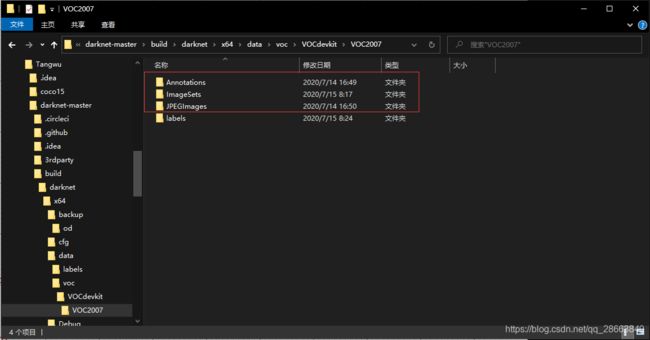
JPEGImages – 储存所有的图片
Annotations – 储存所有的标注 [.xml] 文件
ImageSets – 存储train、test、val
接下来可以按照这片文章走:YOLOv4训练自定义数据集
不过我还是讲解一下过程,感觉上面这篇讲的不太详细。
使用data/voc文件夹下的voc_label.py文件可以将图片和注释文件转换为训练需要的txt文件,步骤如下:
打开voc_label,py修改如下代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]#都改成2007
classes = ["你的类别名称"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('D:/Tangwu/darknet-master/build/darknet/x64/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id), encoding='utf-8')#Annotations的绝对路径
out_file = open('D:/Tangwu/darknet-master/build/darknet/x64/VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')#添加前缀,会在相应文件夹下建立labels文件夹,这是输出labels的路径
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('D:/Tangwu/darknet-master/build/darknet/x64/VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('D:/Tangwu/darknet-master/build/darknet/x64/VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('D:/Tangwu/darknet-master/build/darknet/x64/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
运行上述代码在文件夹下会生成voc_train和voc_test文件(只有图像的绝对路径)和labels文件夹,然后再将/ImageSets/Main/下的train.txt和test.txt复制到darknet-master\build\darknet\x64目录下。
打开notepad++软件,将voc_train.txt和voc_test.txt文件转换为Unix文件,操作如下:
打开文件后,选择编辑——文档格式转换——转换为Unix,然后点击视图——显示符号——显示所有字符,确保每一行结尾都是只有一个LF即可。
![]()
六、建立训练文件和修改相关训练参数
新建xxx.names文件
在darknet-master\build\darknet\x64目录下新建xxx.names(train.names)文件,格式如下:
person
car
truck
bicycle
...
...
新建xxx.data文件
在darknet-master\build\darknet\x64目录下新建xxx.data(obj.data)文件,格式如下:
classes= 15#你的类别数,不加背景
train = #voc_train.txt的绝对路径
valid = #voc_test.txt的绝对路径
names =#train.names的绝对路径
backup = #训练模型保存路径 ./backup
修改cfg文件
在darknet-master\build\darknet\x64\cfg文件夹下找到yolov4-custom.cfg文件并打开修改:
batch=32 或者64
subdivisions=64 (根据你的GPU性能可调整为 32 or 64
max_batches=类别数*2000 但是不少于训练图像的数和6000,类别少于3,写6000
steps=max_batches的80%-90% 假如max_batches=6000,则steps=4800, 5400
width=416 32的倍数
height=416 32的倍数
classes= 你的类别数,不加背景,三处:970行,1058行,1146行
filters=(类别数 + 5)x3 三处:963行,1051行,1139行
接下来就可以在cmd运行训练了
打开cmd进入x64目录运行以下代码:
单GPU:
darknet.exe detector train ./obj.data ./cfg/yolov4-custom.cfg ./yolov4.conv.137 -map
即可开始训练,如果报错CUDA显存不足,则需要调小batch或者图像高和宽尺寸,我目前用的GTX2080TI,设置的batch=32 ,subdivisions=64 图像高宽都是416可以运行。

由于我还没训练完,所以没出检测结果,大家如果还有什么问题可以邮箱[email protected]或者留言,我们一起讨论讨论。
转载请注明出处,如涉及版权问题请联系删除,谢谢!