【高级教程】ctypes:从python菜鸟到c大神
众所周知,相比c++/c,python代码的简洁易懂是建立在一定的速度损耗之上。如果既要代码pythonic又要代码高效,或者比较直接地与系统打交道,那么,ctypes非常值得一探。
目录
1、初识ctypes
2、Hello,CALLING
2.1动态链接库(DLL)
2.2函数(FUNCTION)
2.2.1 A还是W
2.2.2 语法通不过却可以很6地跑
2.2.3 DLL函数索引
2.3 RUNNING,Functions
探讨:cdll? windll?
对比1:CDLL、OleDLL、WinDLL、PyDLL
对比2:cdll、windll、oledll、pydll
拓展:_FuncPtr
3、ctypes基本数据类型
3.1 ctypes数据类型
3.2 创建ctypes数据类型对象
探讨:为什么不是c_init(0)?
3.3 更新ctypes数据类型对象
4、函数调用与ctypes参数
4.1 ctypes参数
4.2 自定义参数
4.3 函数原型
拓展:从原型创建函数
4.4 返回类型
4.5 指针参数与引用参数
5、ctypes高级数据类型
5.1 structure(结构)与union(联合)
5.2 structure/union内存对齐与字节次序
5.3 位字段
5.4 array
5.5 pointer
5.6 类型转换
5.7 不完全类型
5.8 回调函数
5.9 DLL导出变量
5.10彩蛋
5.10.1 交错的内部关系
5.10.2 是我非我
6、可变数据类型
1、初识ctypes
在wlanapi.h中,有这样一个声明:
DWORD WlanQueryInterface(
HANDLE hClientHandle,
const GUID *pInterfaceGuid,
WLAN_INTF_OPCODE OpCode,
PVOID pReserved,
PDWORD pdwDataSize,
PVOID *ppData,
PWLAN_OPCODE_VALUE_TYPE pWlanOpcodeValueType
)正如大家所知,python有自己的数据类型,所以即便有DLL入口也无法在代码中直接调用WlanQueryInterface,这个时候就要用到ctypes,以pywifi源码为例:
def __wlan_query_interface(self, handle, iface_guid, opcode, data_size, data, opcode_value_type):
func = native_wifi.WlanQueryInterface
func.argtypes = [HANDLE, POINTER(GUID), DWORD, c_void_p, POINTER(DWORD), POINTER(POINTER(DWORD)), POINTER(DWORD)]
func.restypes = [DWORD]
return func(handle, iface_guid, opcode, None, data_size, data, opcode_value_type)
def status(self, obj):
"""Get the wifi interface status."""
data_size = DWORD()
data = PDWORD()
opcode_value_type = DWORD()
self.__wlan_query_interface(self._handle, obj['guid'], 6, byref(data_size), byref(data), byref(opcode_value_type))
return status_dict[data.contents.value]不管怎样,pywifi提供的无线网卡查询方法(status)极大地弱化原始API(WlanQueryInterface)的查询能力,虽然只要一个简单的xxx.status(obj)就可以启动查询。
什么是ctypes?ctypes是python的一个外部函数库,提供c兼容的数据类型及调用DLL或共享库函数的入口,可用于对DLL/共享库函数的封装,封装之后就可以用“纯python”的形式调用这些函数(如上面的status)。
2、Hello,CALLING
2.1动态链接库(DLL)
动态链接库是一个已编译好、程序运行时可直接导入并使用的数据-函数库。动态链接库必须先载入,为此ctypes提供三个对象:cdll、windll(windows-only)、oledll(windows-only),并使得载入dll就如访问这些对象的属性一样。
cdll:cdll对象载入使用标准cdecl调用约定的函数库。
windll:windll对象载入使用stdcall调用约定的函数库。
oledll:oledll对象载入使用stdcall调用约定的函数库,但它会假定这些函数返回一个windows系统HRESULT错误代码(函数调用失败时自动抛出OSError/WindowsError异常)。
以msvcrt.dll和kernel32.dll为例介绍dll的载入。
msvcrt.dll:包含使用cdecl调用约定声明的MS标准c函数库,通过cdll载入。
kernel32.dll:包含使用stdcall调用约定声明的windows内核级函数库,通过windll载入。
>>> from ctypes import *
>>> cdll.msvcrt
>>> windll.kernel32
>>> windows会自动添加“.dll”为文件后缀。通过cdll.msvcrt访问的标准c函数库可能使用一个过时的版本,该版本与python正在使用的函数版本不兼容。所以,尽可能地使用python自身功能特性,或者用import导入msvcrt模块。
在linux系统中,载入一个函数库时要指定带扩展名的文件名,所以不再是属性访问式载入,而是或者使用dll载入对象的LoadLibrary()方法,或者通过构造函数创建一个CDLL实例来载入(官网示例):
>>> cdll.LoadLibrary("libc.so.6")
>>> libc = CDLL("libc.so.6")
>>> libc
>>> 而在载入之前,要先获取DLL/共享库(本机windows,以user32.dll为例):
>>> from ctypes.util import find_library
>>> from ctypes import *
>>> find_library('user32')
'C:\\Windows\\system32\\user32.dll'
>>> cdll.LoadLibrary('C:\\Windows\\system32\\user32.dll')
>>> 对于用ctypes封装的共享库而言一个更好的习惯是运行时避免使用find_library()定位共享库,而是在开发时确定好库名并固化(hardcode)到库中。
2.2函数(FUNCTION)
如何获取DLL/共享库中的函数?
很简单:还是像访问一个类实例(这里是DLL对象)属性一样来载入。
所访问的函数都将作为dll载入对象的属性。
>>> from ctypes import *
>>> libc=cdll.msvcrt
>>> libc.printf
<_FuncPtr object at 0x00000183D91DFA08>
>>> help(libc.printf)
Help on _FuncPtr in module ctypes object:
printf = class _FuncPtr(_ctypes.PyCFuncPtr)
| Function Pointer
| Method resolution order:
| _FuncPtr
| _ctypes.PyCFuncPtr
| _ctypes._CData
| builtins.object
| __call__(self, /, *args, **kwargs)
>>> windll.kernel32.GetModuleHandleA
<_FuncPtr object at 0x00000183D91DFAD8>
>>> windll.kernel32.MyOwnFunction
AttributeError: function 'MyOwnFunction' not found
>>>2.2.1 A还是W
操作字符串的API在声明时会指定字符集。像kernel32.dll和user32.dll这样的win32 dll通常会导出同一个函数的ANSI版本(函数名末尾有一个A,如GetModuleHandA)和UNICODE版本(函数名末尾有一个W,如GetModuleHandW)。
/* ANSI version */
HMODULE GetModuleHandleA(LPCSTR lpModuleName);
/* UNICODE version */
HMODULE GetModuleHandleW(LPCWSTR lpModuleName);这是win32 API函数GetModuleHandle在c语言中的原型,它根据给定模块名返回一个模块句柄,并根据宏UNICODE是否定义决定GetModuleHandle代表此二版本中的哪一个。
windll不会试着基于魔法去确定GetModuleHandle的实际版本,就像很多事不能无中生有凭空想象,必须显式地指定所访问的是GetModuleHandleA还是GetModuleHandleW,然后用bytes或string对象调用。
2.2.2 语法通不过却可以很6地跑
有时候,从DLL导出的函数名是非法的python标识符(如??2@YAPAXI@Z),这个时候就得用getattr()来获取该函数:
>>> cdll.msvcrt.??0__non_rtti_object@@QEAA@AEBV0@@Z
SyntaxError: invalid syntax
>>> getattr(cdll.msvcrt, "??0__non_rtti_object@@QEAA@AEBV0@@Z")
<_FuncPtr object at 0x00000183D91DFBA8>
>>>2.2.3 DLL函数索引
windows中,一些DLL不是通过名称而是通过次序导出函数,对于这些函数就可以通过索引(数字索引或名称索引)DLL对象来访问:
>>> windll.kernel32[1]
<_FuncPtr object at 0x000002FD3AAD0AD8>
>>> windll.kernel32[0]
AttributeError: function ordinal 0 not found
>>> windll.kernel32['GetModuleHandleA']
<_FuncPtr object at 0x000002FD3AAD0A08>2.3 RUNNING,Functions
python中callable对象是怎么调用的,DLL函数就可以怎么调用。
下面以time()、GetModuleHandleA()为例来说明如何调用DLL函数。
>>> libc=cdll.msvcrt
>>> libc.time(None)
1591282222
>>> hex(windll.kernel32.GetModuleHandleA(None))
'0x1c700000'
>>>如果函数调用之后ctypes检测到传递给函数的参数不合要求则抛出ValueError异常。这种行为是不可靠的,python3.6.2中就被反对使用,而在python3.7已经被移除。
探讨:cdll? windll?
理论上,当一个导出声明为stdcall的函数使用cdecl调用约定时会抛出ValueError异常(反之亦然):
>>> cdll.kernel32.GetModuleHandleA(None)
ValueError: Procedure probably called with not enough arguments (4 bytes missing)
>>>
>>> windll.msvcrt.printf(b"spam")
ValueError: Procedure probably called with too many arguments (4 bytes in excess)上面是来自python官方文档的例子,本机(python 3.6.5 shell)实际操作如下:
>>> from ctypes import *
>>> cdll.kernel32.GetModuleHandleA(None)
477102080
>>> windll.kernel32.GetModuleHandleA(None)
477102080
>>> hex(cdll.kernel32.GetModuleHandleA(None))
'0x1c700000'
>>> windll.msvcrt.printf(b'spam')
4
>>>为什么实际操作时两种调用约定都可以被cdll和windll使用?
直接查看ctypes源码(已去掉无关内容):
class CDLL(object):
"""An instance of this class represents a loaded dll/shared
library, exporting functions using the standard C calling
convention (named 'cdecl' on Windows).
The exported functions can be accessed as attributes, or by
indexing with the function name. Examples:
.qsort -> callable object
['qsort'] -> callable object
Calling the functions releases the Python GIL during the call and
reacquires it afterwards.
"""
_func_flags_ = _FUNCFLAG_CDECL
_func_restype_ = c_int
# default values for repr
_name = ''
_handle = 0
_FuncPtr = None
def __init__(self, name, mode=DEFAULT_MODE, handle=None,
use_errno=False,
use_last_error=False):
self._name = name
flags = self._func_flags_
if use_errno:
flags |= _FUNCFLAG_USE_ERRNO
if use_last_error:
flags |= _FUNCFLAG_USE_LASTERROR
class _FuncPtr(_CFuncPtr):
_flags_ = flags
_restype_ = self._func_restype_
self._FuncPtr = _FuncPtr
if handle is None:
self._handle = _dlopen(self._name, mode)
else:
self._handle = handle
def __repr__(self):
return "<%s '%s', handle %x at %#x>" % \
(self.__class__.__name__, self._name,
(self._handle & (_sys.maxsize*2 + 1)),
id(self) & (_sys.maxsize*2 + 1))
def __getattr__(self, name):
if name.startswith('__') and name.endswith('__'):
raise AttributeError(name)
func = self.__getitem__(name)
setattr(self, name, func)
return func
def __getitem__(self, name_or_ordinal):
func = self._FuncPtr((name_or_ordinal, self))
if not isinstance(name_or_ordinal, int):
func.__name__ = name_or_ordinal
return func
class PyDLL(CDLL):
"""This class represents the Python library itself. It allows
accessing Python API functions. The GIL is not released, and
Python exceptions are handled correctly.
"""
_func_flags_ = _FUNCFLAG_CDECL | _FUNCFLAG_PYTHONAPI
if _os.name == "nt":
class WinDLL(CDLL):
"""This class represents a dll exporting functions using the
Windows stdcall calling convention.
"""
_func_flags_ = _FUNCFLAG_STDCALL
class OleDLL(CDLL):
"""This class represents a dll exporting functions using the
Windows stdcall calling convention, and returning HRESULT.
HRESULT error values are automatically raised as OSError
exceptions.
"""
_func_flags_ = _FUNCFLAG_STDCALL
_func_restype_ = HRESULT
class LibraryLoader(object):
def __init__(self, dlltype):
self._dlltype = dlltype
def __getattr__(self, name):
if name[0] == '_':
raise AttributeError(name)
dll = self._dlltype(name)
setattr(self, name, dll)
return dll
def __getitem__(self, name):
return getattr(self, name)
def LoadLibrary(self, name):
return self._dlltype(name)
cdll = LibraryLoader(CDLL)
pydll = LibraryLoader(PyDLL)
if _os.name == "nt":
windll = LibraryLoader(WinDLL)
oledll = LibraryLoader(OleDLL)
if _os.name == "nt":
GetLastError = windll.kernel32.GetLastError
else:
GetLastError = windll.coredll.GetLastError
from _ctypes import get_last_error, set_last_error
def WinError(code=None, descr=None):
if code is None:
code = GetLastError()
if descr is None:
descr = FormatError(code).strip()
return OSError(None, descr, None, code) 分析上面源码可知,ctypes提供CDLL、PyDLL、 WinDLL、OleDLL四种类型的DLL对象,后三者是CDLL的子类,前二者是通用DLL,后二者专为windows系统定义。此四者主要区别在于_func_flags_的取值:
| CDLL |
WinDLL |
| _FUNCFLAG_CDECL |
_FUNCFLAG_STDCALL |
| OleDLL |
PyDLL |
| _FUNCFLAG_STDCALL |
_FUNCFLAG_CDECL | _FUNCFLAG_PYTHONAPI |
三个子类的方法与属性都继承自CDLL,其中OleDLL还有一个例外的_func_restype_属性。
此外,ctypes提供cdll、windll、pydll、oledll四个LibraryLoader对象用于实际完成dll的载入。
>>> windll=LibraryLoader(WinDLL)
>>> windll.kernel32因为windll.__dict__不存在名称’kernel32’,所以最终将调用LibraryLoader中__getattr__,开始实际上的WinDLL(‘kernell32’)实例化(会用到CDLL中的__init__,载入模块、获取模块句柄),实例对象加入windll的__dict__后被返回;windll.LoadLibrary(‘kernel32’)作用类似(返回新DLL对象);支持名称索引。
>>> windll.kernel32.GetModuleHandleAwindll.kernel32将返回一个WinDLL(‘kernell32’)对象,接着会调用CDLL中
__getattr__,__getitem__来获取GetModuleHandleA 的_FuncPtr对象,通过该对象调用函数。若函数载入方式只有windll.kernel32['GetModuleHandleA'],GetModuleHandleA将不被加入WinDLL(‘kernell32’)对象的__dict__(因为有__getattr__,在使用时感觉不到属性载入和名称索引载入的区别)。
仅基于以上ctypes源码分析还看不到windll和cdll在载入dll及相关函数时的本质差异,而两个关键之处_dlopen、_CFuncPtr来自_ctypes.pyd:
from _ctypes import LoadLibrary as _dlopen
from _ctypes import CFuncPtr as _CFuncPtr所以_func_flags_是如何发挥作用并未得知。如果哪位大神已知晓为什么能混合调用,还望多多指教。
无论怎样,虽然两种方式都可以,但为避免不必要的潜在风险还是请遵循python官方文档的使用指导。
而想要知道一个函数的正确调用约定,就得从相关c头文件或文档中找出函数声明。
windows中,ctypes使用WIN32结构化的异常处理来防止以错误参数调用函数时产生的程序崩溃(如一般性保护故障):
>>> windll.kernel32.GetModuleHandleA(32)
OSError: exception: access violation reading 0x0000000000000020
>>> getattr(cdll.msvcrt, "??0__non_rtti_object@@QEAA@AEBV0@@Z")(123)
OSError: exception: access violation writing 0x000000000000008B
>>>这里有足够多的方式通过ctypes击溃python,所以无论如何要非常小心。faulthandler模块对于调试“python事故”(比如错误的c库函数调用产生的段故障)非常有帮助。
对比1:CDLL、OleDLL、WinDLL、PyDLL
class ctypes.CDLL(name, mode=DEFAULT_MODE, handle=None, use_errno=False, use_last_error=False)
DLL类型:cdecl调用约定
返回值类型:int
class ctypes.OleDLL(name, mode=DEFAULT_MODE, handle=None, use_errno=False, use_last_error=False)
DLL类型:stdcall调用约定
返回值类型:HRESULT(指示函数调用失败时,已自动抛出异常)
class ctypes.WinDLL(name, mode=DEFAULT_MODE, handle=None, use_errno=False, use_last_error=False)
DLL类型:stdcall调用约定
返回值类型:int
以上DLL导出函数在调用前释放GIL,调用结束后请求GIL。
class ctypes.PyDLL(name, mode=DEFAULT_MODE, handle=None)
DLL类型:cdecl调用约定
返回值类型:int
PyDLL导出函数调用前无需释放GIL,且在调用结束后执行python错误标记检查,如有错误则抛出异常。PyDLL对直接调用python C API函数非常有用。以上所有类都可以用至少带一个参数(此时为DLL/共享库路径名)的自身工厂函数来实例化。如果已经获取DLL/共享库句柄,则可以作为参数传给handle,否则将会用到底层平台dlopen或LoadLibrary函数将DLL/共享库载入进程,并取得相应句柄。
mode参数指定如何载入DLL/共享库,详情请参考dlopen(3)手册页。windows中mode参数被忽略。posix系统中,mode总要被加入RTLD_NOW,且不可配置。常用于mode的标志有:
ctypes.RTLD_GLOBAL:在该标志不可用的平台上其值被定义为0。
ctypes.RTLD_LOCAL:在该标志不可用的平台上其值同RTLD_GLOBAL。
ctypes.DEFAULT_MODE:默认的mode,用于载入DLL/共享库。在OS X 10.3该标志同RTLD_GLOBAL,其他平台同RTLD_LOCAL。
use_errno参数被置为True时,ctypes机制将以一种安全的方式访问系统errno错误代码。ctypes维持一份系统变量errno的本地线程副本。如果调用创建自带use_errno=True的DLL外部函数,ctypes会在函数调用前以自身副本errno和系统errno交换,而在调用之后又立即交换回来。
ctypes.get_errno()函数返回ctypes私有副本errno的值,ctypes_set_errno()函数设置ctypes私有副本errno值并返回设置前的值。
use_last_error参数被置为True时,将使Windows API GetLastError()和SetLastError()管理的windows错误代码有着相同机制。ctypes.get_last_error()和ctypes.set_last_error()用于获取和改变ctypes的windows错误代码私有副本。
这些类实例没有公共方法。DLL/共享库导出的函数既可以作为属性访问也可以通过索引来访问。但要注意通过属性访问函数会缓存访问结果,因此重复访问时每次都返回相同对象。而通过索引访问每次会返回新的对象。
>>> libc=cdll.msvcrt
>>> libc.time==libc.time
True
>>> libc['time']==libc['time']
False
>>>对比2:cdll、windll、oledll、pydll
ctypes.LibraryLoader(dlltype):这个类用于载入函数库,dlltype为DLL类型(CDLL、PyDLL、WinDLL、OleDLL之一),允许以访问属性的方式载入函数库(将会缓存载入结果,重复访问时返回的函数库相同),或者通过LoadLibrary(name)方法载入(返回新对象)。注意区别于DLL对象的函数访问。
ctypes.cdll:创建CDLL实例;
ctypes.windll:创建WinDLL实例;
ctypes.olddll:创建OleDLL实例;
ctypes.pydll:创建PyDLL实例;
ctypes.pythonapi:创建以python C API为属性PyDLL实例,用于直接访问c python api,是一个只读的python共享函数库。导出的函数都假定返回c语言int值,但实际上并不总是返回int值,所以得为这类函数设置正确的restype属性。
拓展:_FuncPtr
如前所说,外部函数可以作为已载共享库的属性来访问。函数对象创建时默认接受任意数量参数(任意ctypes数据类型实例),并返回dll载入对象(如cdll、windll等)指定的默认类型返回值。函数对象其实是一个私有类的实例:
class ctypes._FuncPtr,用(服务)于c外部可调用函数的基类。
函数对象实例也是c兼容数据类型,代表c函数指针。这种(代表)行为(函数指针的实际定义)可通过赋予外部函数对象特殊属性来自行定义。
restype:设置函数返回值类型。如果函数无返回值则为None。
可以为restype设置一个非ctypes类型的python可调用对象,但这种情况下的外部函数必须是被假定为返回c语言int型值的,且该值被传递给python可调用对象作进一步处理或错误检测。这种用法是不被提倡的,以ctypes数据类型为restype并设置errcheck属性为一个可调用对象的后置处理或错误检测要合适得多。
argtypes:一个指定外部函数参数类型的ctypes类型元组(也可以是列表)。对于stdcall调用约定的函数,只有当函数参数的个数、类型与元组元素一一对应时才能被调用,而对于cdecl调用约定的函数则还可以接受额外的、(元组中)未指定的参数。
在调用外部函数时,实际参数传给argtypes元组中各类型的from_param()类方法,该方法将实际参数调配成函数能接受的对象。例如,argtypes元组中的c_char_p能使用ctypes转换规则将传递来的字符串参数转换成字节串对象。
新特性:现在已经可以把项目放入非ctypes类型的argtypes(即argtypes的元素不再仅限于ctypes类型),但是各项必须提供from_param()方法返回一个值(整数实例、字符串实例、ctypes实例等)作为调配后的参数。这种特性允许定义一个将自定义对象转换成能适应函数参数类型的“调配器”。
一个外部函数在调用时若无法转换任意一个传递给它的参数将抛出ctypes.ArgumentsError异常。
errcheck:该属性只能赋值python函数或其他可调用对象。可调用对象在被调用时带有三个或更多参数:callable(result,func,arguments)。
result是外部函数返回值,由restype属性指定。
func是外部函数对象自身,这就允许再次使用同一可调用对象来对若干函数返回结果进行错误检测或后续处理。
arguments是传递给函数调用的原始参数元组,这可以定制参数的使用。
errcheck的返回结果将从外部函数调用返回,但它也能检查(外部函数)返回值,如果函数调用失败还能抛出异常。
以上属性只对ctypes._FuncPtr实例(即DLL外部函数对象)有效。
3、ctypes基本数据类型
在调用DLL函数时,None、int、bytes、str是python中仅有的可直接作为函数参数的原生对象。当函数参数为NULL指针时,可以传递None为参数;当函数参数是一个包含数据的内存块指针(char*或wchar_t*)时,可以传递bytes或str为参数;当函数参数为系统平台默认int类型时,可以传递int为参数(为适应c数据类型其值将被部分屏蔽)。
>>> import sys
>>> sys.maxsize
9223372036854775807那么,对于其他类型参数,应该怎样传递?
3.1 ctypes数据类型
ctypes定义了大量原始的c兼容数据类型,以满足函数调用时的各种参数传递需要。
| c基本数据类型 |
||
| 类型 |
32位平台(B) |
64位平台(B) |
| char |
1 |
1 |
| short |
2 |
2 |
| int |
4 |
4 |
| long |
4 |
(≥4) 8 |
| long long |
8 |
8 |
| float |
4 |
4 |
| double |
8 |
8 |
| size_t |
4 |
8 |
| ssize_t |
4 |
8 |
| ctypes基本数据类型与对应关系 |
||
| ctypes type |
C type |
Python type |
| c_bool |
_Bool |
bool (1) |
| c_char |
char |
1-character bytes object |
| c_wchar |
wchar_t |
1-character str |
| c_byte |
char |
int |
| c_ubyte |
unsigned char |
int |
| c_short |
short |
int |
| c_ushort |
unsigned short |
int |
| c_int |
int |
int |
| c_uint |
unsigned int |
int |
| c_long |
long |
int |
| c_ulong |
unsigned long |
int |
| c_longlong |
__int64 or long long |
int |
| c_ulonglong |
unsigned __int64 or unsigned long long |
int |
| c_size_t |
size_t |
int |
| c_ssize_t |
ssize_t or Py_ssize_t |
int |
| c_float |
float |
float |
| c_double |
double |
float |
| c_longdouble |
long double |
float |
| c_char_p |
char * (NUL terminated) |
bytes or None |
| c_wchar_p |
wchar_t * (NUL terminated) |
str or None |
| c_void_p |
void * |
int or None |
3.2 创建ctypes数据类型对象
ctypes type这一列的类型名都可以作为工厂函数,通过接受一个正确的可选“类型-值”来创建ctypes对象:
>>> from ctypes import *
>>> c_int()
c_long(0)
>>> c_wchar_p("Hello,World")
c_wchar_p(2731200093040)
>>> c_ushort(-3)
c_ushort(65533)
>>> c_float(6)
c_float(6.0)
>>> c_float('a')
TypeError: must be real number, not strctypes对象的初始化值必须与Python type对应,而决定要用到什么类型的ctypes对象,则根据C type而定。
探讨:为什么不是c_init(0)?
>>> c_int()
c_long(0)为什么不是c_int(0)?不妨找一找蛛丝马迹:
>>> import sys
>>> sys.version
'3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)]'
>>> sys.platform
'win32'
>>> sys.maxsize
9223372036854775807
>>> 2**63-1
9223372036854775807
>>> sys.maxsize.bit_length()
63
>>> import struct
>>> bit=struct.calcsize('P')*8
>>> bit
64
>>> import platform
>>> platform.architecture()
('64bit', 'WindowsPE')
>>> import ctypes
>>> c_long==c_int
True
>>>或者,更直接些(c代码):
#include
#include
int main()
{
printf("size of int %d,sizeof long %d\n", sizeof(int), sizeof(long));
system("pause");
}
size of int 4,sizeof long 4
请按任意键继续. . . ctypes源码(片段):
if _calcsize("i") == _calcsize("l"):
# if int and long have the same size, make c_int an alias for c_long
c_int = c_long
c_uint = c_ulong
else:
class c_int(_SimpleCData):
_type_ = "i"
_check_size(c_int)
class c_uint(_SimpleCData):
_type_ = "I"
_check_size(c_uint)通过多种方式得知(这里要感谢网络上各位大神提供平台查询方法参考),CPU、windows系统和python都是64位,应用程序平台win32,然而之所以“c_long==c_int”结果为True,主要还是因为无论windows系统是32位还是64位,sizeof(int)=sizeof(long)=4,这是一种编译器在具体定义int和long时的内在规定(这里要感谢群中大神指点)。“long与int:标准只规定long不小于int的长度,int不小于short的长度”(《C和指针》)。
总之,c_int是c_long的别名,它们实际上是同一类型。
3.3 更新ctypes数据类型对象
>>> i=c_int(42)
>>> i
c_long(42)
>>> i.value
42
>>> i.value=-99
>>> i
c_long(-99)
>>>只要改变obj.value,就可以更新对象的值。
对指针类型(如c_char_p、c_wchar_p、c_void_p)实例赋一个新value,更新的是指针所指向的内存块而不是内存块的内容(因为python的bytes对象是不可变的)。
>>> s='Hello,World'
>>> c_s=c_wchar_p(s)
>>> c_s
c_wchar_p(2126155553624)
>>> c_s.value
'Hello,World'
>>> c_s.value='Hi,there'
>>> c_s
c_wchar_p(2126155553672)
>>> c_s.value
'Hi,there'
>>> s
'Hello,World'
>>>调用函数时要非常小心,不要把它们传给需要指针指向可变内存的函数。如果需要一个可写内存块,则要用ctypes的create_string_buffer()函数,它将以不同方式创建可变内存块。
通过raw属性访问或修改buffer对象当前内存块内容。
>>> p=create_string_buffer(3) #创建一个3字节buffer并初始化为NUL
>>> print(sizeof(p),repr(p.raw))
3 b'\x00\x00\x00'
>>> p=create_string_buffer(b'Hello')#创建包含NUL字符串的buffer
>>> print(sizeof(p),repr(p.raw))
6 b'Hello\x00'NUL是一个1字节的字符b’\x00’。NUL字符串是末尾有NUL的字符串。
通过value属性把buffer对象当作NUL字符串访问。
>>> p.value
b'Hello'raw与value的区别:raw所见即所得,value所见即NUL串
| >>> p=create_string_buffer(b'Hello',10) >>> print(sizeof(p),repr(p.raw)) 10 b'Hello\x00\x00\x00\x00\x00' >>> p.value=b'Hi' >>> print(sizeof(p),repr(p.raw)) 10 b'Hi\x00lo\x00\x00\x00\x00\x00'
|
>>> p=create_string_buffer(b'Hello',10) >>> print(sizeof(p),repr(p.raw)) 10 b'Hello\x00\x00\x00\x00\x00' >>> p.raw=b'Hi' >>> print(sizeof(p),repr(p.raw)) 10 b'Hillo\x00\x00\x00\x00\x00' |
create_string_buffer()函数已经替换掉ctypes早期发行版的c_buffer()(仍可作为别名使用)和c_string()。若要创建包含unicode字符(国标,一字符二字节,c语言的wchar_t类型)的可变内存块,请使用create_unicode_buffer()函数。
>>> p=create_unicode_buffer(u'Hello',10)
>>> print(sizeof(p),repr(p.value))
20 'Hello'
>>> p.value=u'123'
>>> print(sizeof(p),repr(p.value))
20 '123'4、函数调用与ctypes参数
4.1 ctypes参数
函数printf将内容输出到实际的标准输出设备,而不是sys.stdout,所以下面这个例子只能运行在控制台命令提示符下,而不是IDLE或PythonWin:
>>> libc=cdll.msvcrt
>>> printf=libc.printf
>>> printf(b"Hello,%s\n",b"World!")
13
>>> p=c_char_p(b'Hello,%s\n')
>>> p2=c_char_p(b'World!')
>>> printf(p,p2)
13
>>> printf(b'%d bottles of beer\n',42)
19
>>> printf(b'%f bottles of beer\n',42.5)
ctypes.ArgumentError: argument 2: : Don't know how to convert parameter 2 在IDLE中执行上述语句无实际输出,将其保存到文件console.py并在控制台(Git Bash)下运行:
$ python console.py
ctypes.ArgumentError: argument 2: : Don't know how to convert parameter 2
Hello,World!
Hello,World!
42 bottles of beer 正如之前所说,所有整数、字符串str、字节串bytes之外的python类型对象都要被对应ctypes封装才能转换成所需的c数据类型传递给函数(控制台下python):
>>> printf(b"An int %d, a double %f\n", 1234, c_double(3.14))
An int 1234, a double 3.140000
31
>>> printf(b'%f bottles of beer\n',c_double(42.5))
42.500000 bottles of beer
26
为什么一个42.5要用到c_double而不是c_float呢?
>>> printf(b'%f bottles of beer\n',c_float(42.5))
0.000000 bottles of beer
25这里给大家留道课后作业,自行探索。
4.2 自定义参数
_as_parameter_:定义ctypes参数转换以允许自定义类型实例作为函数参数。调用函数的时候,ctypes会查找_as_parameter_属性并以之为函数参数。
_as_parameter_只能为整数、字符串或字节串:
>>> class Bottles:
... def __init__(self, number):
... self._as_parameter_=number
...
>>> bottles = Bottles(42)
>>> printf(b"%d bottles of beer\n", bottles)
42 bottles of beer
19
>>>如果不想在实例属性_as_parameter_中存放数据,那么可以定义一个property,只有在查询_as_parameter_的请求中该属性才可用。
>>> class Bottles:
... def __init__(self,number):
... self.number=number
... @property
... def _as_parameter_(self):
... return self.number
...
>>> bottles=Bottles(42)
>>> printf(b"%d bottles of beer\n", bottles)
42 bottles of beer
19
>>>4.3 函数原型
这里的函数原型主要指函数的参数类型。
argtypes:argtypes属性指定DLL导出函数所要求的参数类型。argtypes必须是一个c数据类型(对应的ctypes)序列(printf可能不是一个介绍函数原型的好例子,因为它参数数量不固定,并且参数的类型取决于格式化字符串,但是从另一个方面说,printf又非常便于体验函数原型的特性):
>>> printf.argtypes = [c_char_p, c_char_p, c_int, c_double]
>>> printf(b"String '%s', Int %d, Double %f\n", b"Hi", 10, 2.2)
String 'Hi', Int 10, Double 2.200000
37
>>>argstypes相当于定义一个格式保护来防止不兼容的参数类型(就好像一个c函数的原型),并试着进行兼容类型转换:
>>> printf(b"%d %d %d", 1, 2, 3)
ctypes.ArgumentError: argument 2: : wrong type
>>> printf(b"%s %d %f\n", b"X", 2, 3)
X 2 3.000000
13
>>> 如果要将自定义的类型(类)作为参数传递给函数,那么得在类中实现类方法from_param(),才能用于argtypes序列。from_param()类方法接收实际传递给函数的python对象并做类型检查,无论怎样要确保这个对象是可接受的,然后返回对象自身,或它的_as_parameter_属性,或该情况下任何想要作为参数传递给函数的对象。再次重申,返回结果应该是整数、字符串、字节串、ctypes实例,或者是具有_as_parameter_属性的对象。
文件console.py:
from ctypes import *
libc=cdll.msvcrt
printf=libc.printf
class Bottles:
def __init__(self,number):
self.number=number
@property
def _as_parameter_(self):
return self.number
@classmethod
def from_param(cls,obj):
if obj.__class__!=cls:
raise AttributeError('Not a Bottles.')
return obj
bottles=Bottles(42)
printf.argtypes=[c_char_p,c_char_p,Bottles,c_int]
printf(b'Hi,%s,I have %d bottles.%d ?',b'James',bottles,100)命令行运行:
$ python console.py
Hi,James,I have 42 bottles.100 ?
如果console.py中的Bottles类为
class Bottles:
def __init__(self,number):
self.number=number
@classmethod
def from_param(cls,obj):
if obj.__class__!=cls:
raise AttributeError('Not a Bottles.')
return obj.number也是可以的,输出结果相同。若是文件最后增加:
printf(b'Hi,%s,I have %d bottles.%d ?',b'James',2,100)则输出为:
ctypes.ArgumentError: argument 3: : Not a Bottles.
Hi,James,I have 42 bottles.100 ? 拓展:从原型创建函数
外部函数也可能创建自一个实例化的函数原型。函数原型类似于c语言中的函数原型,不带执行定义地描述一个函数(返回类型,参数类型,调用约定)。工厂函数必须以外部函数要求的返回类型和参数类型来调用。
ctypes.CFUNCTYPE(restype, *argtypes, use_errno=False, use_last_error=False):返回的函数原型创建cdecl调用约定函数。函数调用期间将释放GIL。如果use_errno为True,ctypes私有的系统errno副本在函数调用前后将和真正的系统errno变量交换值。use_last_error同windows错误代码。
ctypes.WINFUNCTYPE(restype, *argtypes, use_errno=False, use_last_error=False):返回的函数原型创建stdcall调用约定函数。windows CE应用平台是一个例外,该平台WINFUNCTYPE()作用同CFUNCTYPE()。函数调用期间将释放GIL。 use_errno和 use_last_error意义同上。
ctypes.PYFUNCTYPE(restype, *argtypes):返回的函数原型创建python调用约定函数。函数调用期间不会释放GIL。
函数原型被以上工厂函数创建并以不同方式实例化,这取决于调用时的参数类型和数量:
prototype(address):返回一个由整数地址指定的外部函数。
prototype(callable):从一个python对象 callable创建c可调用函数(一个回调函数)。
prototype(func_spec[, paramflags]):返回一个从共享库导出的外部函数。func_spec必须是二元组(name_or_ordinal, library),第一项是字符串(导出函数名),或者是一个小整数(-32768到+32767,导出函数序号),第二项是共享库实例。
prototype(vtbl_index, name[, paramflags[, iid]]):返回一个调用COM方法的外部函数。vtbl_index是一个非负小整数(虚拟函数表函数索引),name是COM方法名,iid是一个指向扩展错误报告中接口标识符的可选指针。
COM方法使用一种特殊调用约定:它要求一个指向COM接口的指针为第一个参数,除此之外这些参数都由argtypes元组指定。
可选参数paramflags创建的外部函数wrapper比上述特性功用性更强。paramflags必须是一个和argtypes长度相同的元组,元组中每一项都包含更多的参数信息,必须是一个包含1到3项的元组:
第一项是一个包含参数方向标志组合的整数:1输入参数;2输出参数,由外部函数填入一个值;4输入参数,默认值为整数0。
第二项可选,是一个字符串(参数名)。如果指定该参数,外部函数可用命名参数调用。
第三项也可选,代表对应参数的默认值。
这个例子展示如何封装windows的MessageBoxW函数,以让它支持默认参数和命名参数。它在windows头文件中声明如下:
WINUSERAPI int WINAPI
MessageBoxW(
HWND hWnd,
LPCWSTR lpText,
LPCWSTR lpCaption,
UINT uType);用ctypes封装:
>>> from ctypes import c_int,WINFUNCTYPE,windll
>>> from ctypes.wintypes import HWND,LPCWSTR,UINT
>>> prototype=WINFUNCTYPE(c_int,HWND,LPCWSTR,LPCWSTR,UINT)
>>> paramflags=(1,'hWnd',0),(1,'lpText','Hi'),(1,'lpCaption','Hello from ctypes'),(1,'uType',0)
>>> paramflags
((1, 'hWnd', 0), (1, 'lpText', 'Hi'), (1, 'lpCaption', 'Hello from ctypes'), (1, 'uType', 0))
>>> MessageBox=prototype(('MessageBoxW',windll.user32),paramflags)
>>>现在,外部函数MessageBox能够用多种方式调用:
>>> MessageBox()
1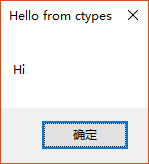
>>> MessageBox(lpText="Spam,spam,spam")
1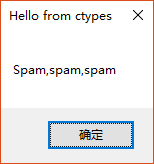
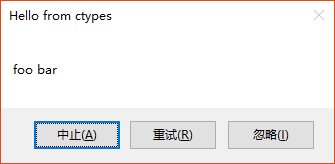
>>> MessageBox(uType=2,lpText="foo bar")
3
>>> MessageBox(uType=2,lpText="foo bar")
4
>>> MessageBox(uType=2,lpText="foo bar")
5
>>>
第二个例子展示输出参数的使用。Win32 API GetWindowRect函数会接受一个通过复制到调用者必须提供的RECT结构而得到的特定窗口大小参数。c声明如下:
WINUSERAPI BOOL WINAPI
GetWindowRect(
HWND hWnd,
LPRECT lpRect);用ctypes封装:
>>> from ctypes import POINTER,WINFUNCTYPE,windll,WinError
>>> from ctypes.wintypes import BOOL,HWND,RECT
>>> prototype=WINFUNCTYPE(BOOL,HWND,POINTER(RECT))
>>> paramflags=(1,'hWnd'),(2,'lpRect')
>>> GetWindowRect=prototype(('GetWindowRect',windll.user32),paramflags)具有输出参数的函数将返回输出参数值(如果只有一个输出参数),或一个输出参数元组(二个或二个以上输出参数),所以现在GetWindowRect将在调用时返回一个RECT实例。
>>> r=GetWindowRect(0x00010310)
>>> r
>>> print(r.left,r.top,r.right,r.bottom)
69 25 674 628
>>> 输出参数与errcheck机制组合可做更多输出处理和错误检测。Win32 GetWindowRect api函数返回一个BOOL值以示调用成功或失败,因此可对其进行错误检测并在调用失败时抛出异常:
>>> def errcheck(result, func, args):
if not result:
raise WinError()
return args
>>> GetWindowRect.errcheck=errcheck为便于观察,已以return args前加入print(result,func,args,sep='\n'):
>>> r=GetWindowRect(None)
OSError: [WinError 1400] 无效的窗口句柄。
>>> r=GetWindowRect(0x00010310)
1
(66320, )
>>> r
>>> 如果errcheck函数原样返回所接收到的参数元组,ctypes便继续其对输出参数的正常处理。如果想要返回一个窗口坐标元组而不是RECT实例,那么可以在函数中获取RECT字段并返回所要求的结果,而ctypes的正常处理将不再进行:
>>> def errcheck(result, func, args):
if not result:
raise WinError()
rc = args[1]
return rc.left, rc.top, rc.bottom, rc.right
>>> GetWindowRect.errcheck = errcheck
>>>4.4 返回类型
restype:默认情况下函数被假定返回c语言int型数据,如果返回数据为其他类型则要为函数对象设置restype属性。
下面是一个更高级的例子,例中用到的strchr函数需要一个字符串指针和一个字符作为参数,返回一个字符串指针。
>>> strchr=cdll.msvcrt.strchr
>>> strchr(b'abcdef',ord('d'))
-1860239533
>>> strchr.restype=c_char_p
>>> strchr(b'abcdef',ord('d'))
b'def'
>>> strchr(b'abcdef',ord('x'))
>>>如果想避免上例中ord(‘x’)的调用,可以为函数设置argtypes属性,那么第二个参数将从python单字符bytes转换为c语言char:
>> strchr.restype = c_char_p
>>> strchr.argtypes = [c_char_p, c_char]
>>> strchr(b'abcdef',b'd')
b'def'
>>> strchr(b'abcdef',b'def')
ctypes.ArgumentError: argument 2: : wrong type
>>> strchr(b'abcdef',b'x')
>>> strchr(b'abcdef',b'd')
b'def'
>>> 如果外部函数返回整数,那么还可以用一个python可调用对象(callable对象,例如函数或类)作为restype属性(值)。callable对象将以外部函数返回的整数为参数被调用,其返回结果将作为函数的最终结果。这对于返回值的错误检查和自动抛出异常非常有帮助。
>>> GetModuleHandle = windll.kernel32.GetModuleHandleA
>>> def ValidHandle(value):
if value==0:
raise WinError()
return value
>>> GetModuleHandle.restype=ValidHandle
>>> GetModuleHandle(None)
480444416
>>> GetModuleHandle('something silly')
OSError: [WinError 126] 找不到指定的模块。
>>>WinError()函数将调用Windows API FormatMessage()获取错误代码对应的字符串,并返回一个异常。WinError()带有一个可选的错误代码参数,如果没有,则它会通过GetLastError()来获取错误代码。
此外,通过为函数设置errcheck属性可以使用功能更为强大的错误检查机制,详情请参考相关使用手册。
argtypes和restype只对ctypes导出的DLL函数有效:
>>> def func(a,b,c):
return a.value+b.value+c.contents.value
>>> func.argtypes=[c_int,c_int,POINTER(c_int)]
>>> func.restype=[c_int]
>>> a1=c_int(9)
>>> a2=c_int(10)
>>> a3=c_int(11)
>>> ap3=POINTER(c_int)(c_int(11))
>>> r1=func(a1,a2,ap3)
>>> r1
30
>>> type(r1)
>>> r2=func(a1,a2,a3)
AttributeError: 'c_long' object has no attribute 'contents' 4.5 指针参数与引用参数
有时候一个c API函数要求一个指向某种数据类型的指针作为参数,这可能是函数要在相应内存位置进行写操作,也可能数据太大而不能作为值传递。这就是所谓引用传参。
ctypes导出的byref()函数用于引用传参,与该函数等效的函数是pointer(),但pointer()会因为真实构建一个指针对象而做更多工作,所以,如果不需要python指针对象,那么使用byref()速度更快:
>>> i=c_int()
>>> f=c_float()
>>> s=create_string_buffer(b'\000'*32)
>>> print(i.value,f.value,repr(s.value))
0 0.0 b''
>>> cdll.msvcrt.sscanf(b'1 3.14 Hello',b'%d %f %s',byref(i),byref(f),s)
3
>>> print(i.value,f.value,repr(s.value))
1 3.140000104904175 b'Hello'
>>>cdll.msvcrt.sscanf(b'1 3.14 Hello',b'%d %f %s',pointer(i),pointer(f),s)结果同上。
5、ctypes高级数据类型
5.1 structure(结构)与union(联合)
与c语言structure、union对应的python类型必须派生自定义在ctypes模块的Structure和Union基类。每种子类必须定义_fields_属性,该属性是一个二元元组列表,各元组包含一个field(c语言结构体或联合体的属性/字段)的名称及其类型。field类型必须是ctypes类型,比如c_int,或其它任意派生自ctypes的类型:structure,union,array,pointer。
下面是POINT结构的一个简单例子,包含两个整数属性x和y,并介绍如何初始化一个结构:
>>> class POINT(Structure):
_fields_ = [("x", c_int),
("y", c_int)]
>>> point=POINT(10,20)
>>> print(point.x,point.y)
10 20
>>> point=POINT(y=5)
>>> print(point.x,point.y)
0 5
>>> point=POINT(1,2,3)
TypeError: too many initializers
>>>可以定义一个比POINT复杂得多的结构,还可以通过将其他结构作为一个field类型来包含该结构。
下面是一个RECT结构例子,它有两个POINT,一个是upperleft,一个是lowerright:
>>> class RECT(Structure):
_fields_ = [("upperleft", POINT),
("lowerright", POINT)]
>>> rc = RECT(point)
>>> print(rc.upperleft.x,rc.upperleft.y)
0 5
>>> print(rc.lowerright.x,rc.lowerright.y)
0 0
>>>除上述之外,像RECT这种结构中包含其他结构的复合结构(嵌套结构)有多种实例化方式:
>>> r = RECT(POINT(1, 2), POINT(3, 4))
>>> r = RECT((1, 2), (3, 4))
>>>从类中获取的field描述能够提供非常有用的信息,这对调试非常有帮助:
>>> print(POINT.x)
>>> print(POINT.y)
>>> 警告:ctypes不支持以传值的形式将带有bit-field(位域/位字段)的union或structure传给函数作参数。而这在32位的x86系统上可能行得通,但不被运作在一般情况下的函数库所保证。带有bit-field的union或structure应该一直以传指针的形式传给函数作参数。
5.2 structure/union内存对齐与字节次序
默认地,structure和union字段(field)在内存中的对齐方式与c编译器的对齐处理方式是一致的。可以通过在子类定义中指定类属性_pack_来覆盖默认对齐方式。_pack_必须是一个正整数,指明字段最大对齐方式。这也是MSVC中#pragma pack(n)指令在做的事。
默认对齐方式:
>>> class POINT(Structure):
_fields_ = [("x", c_int),
("xbit",c_int64,33),
("y", c_int),
("ybit",c_int64,33),
("z",c_longlong)]
>>> print(POINT.x)
>>> print(POINT.xbit)
>>> print(POINT.y)
>>> print(POINT.ybit)
>>> print(POINT.z)
指定对齐方式:
>>> class POINT(Structure):
_fields_ = [("x", c_int),
("xbit",c_int64,33),
("y", c_int),
("ybit",c_int64,33),
("z",c_longlong)]
_pack_=4
>>> print(POINT.x)
>>> print(POINT.xbit)
>>> print(POINT.y)
>>> print(POINT.ybit)
>>> print(POINT.z)
对于structure和union,ctypes使用本地字节次序。要构建一个非本地字节次序结构,就得用到BigEndianStructure,LittleEndianStructure,BigEndianUnion,LittleEndianUnion基类之一进行派生。派生类不能包含指针字段。
注:BigEndianUnion,LittleEndianUnion在ctypes中未实际定义。
大端序、小端序分别指从存储单元低位地址开始的高位字节优先存放方式、低位字节优先存放方式(字节串类型无区别)。
>>> import sys
>>> sys.byteorder
'little'
>>> class union(Union):
_fields_=[('x',c_uint32),('x1',c_uint32,8),('pad',c_ulong),
('x2',c_uint32,16),('x3',c_uint32,24),
('x4',c_uint32,32)
]
>>> y=union()
>>> y.x=0xaabbccdd
>>> hex(y.x1)
'0xdd'
>>> hex(y.x2)
'0xccdd'
>>> hex(y.x3)
'0xbbccdd'
>>> hex(y.x4)
'0xaabbccdd'
>>> from struct import *
>>> n=0xaabbccdd
>>> pack('>> pack('>> pack('@I',n)
b'\xdd\xcc\xbb\xaa'
>>> pack('>I',n)
b'\xaa\xbb\xcc\xdd'
>>> pack('!I',n)
b'\xaa\xbb\xcc\xdd'
>>> 现有两个文件,一个是server.py:
import struct,socket,pickle
from ctypes import *
class D(BigEndianStructure):
_fields_=[('x',c_uint)]
BUFSIZE=1024
ADDR=("localhost",2046)
recvsocket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
recvsocket.bind(ADDR)
while True:
print('waiting for the data...')
data,addr=recvsocket.recvfrom(BUFSIZE)
print(repr(data))
dlen=len(data)
if dlen==58:
(data1,)=struct.unpack('!58s',data)
print(repr(data1))
obj=pickle.loads(data1)
print(hex(obj.x))
(data2,)=struct.unpack('@58s',data)
print(repr(data2))
obj=pickle.loads(data2)
print(hex(obj.x))
if dlen==4:
(data1,)=struct.unpack('!I',data)
print(hex(data1))
(data2,)=struct.unpack('@I',data)
print(hex(data2))
break
print('closing...')
recvsocket.close()另一个是client.py:
import struct,socket
from ctypes import *
import pickle
class D(BigEndianStructure):
_fields_=[('x',c_uint)]
sdata=D()
sdata.x=0xaabbccdd
BUFSIZE=1024
ADDR=("localhost",2046)
sendsocket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
pdata=pickle.dumps(sdata)
print(repr(pdata))
sendsocket.sendto(pdata,ADDR)
sendsocket.sendto(struct.pack('!I',sdata.x),ADDR)
sendsocket.close()先运行server,再运行client,服务器端输出结果如下:
waiting for the data...
b'\x80\x03c_ctypes\n_unpickle\nq\x00c__main__\nD\nq\x01}q\x02C\x04\xaa\xbb\xcc\xddq\x03\x86q\x04\x86q\x05Rq\x06.'
b'\x80\x03c_ctypes\n_unpickle\nq\x00c__main__\nD\nq\x01}q\x02C\x04\xaa\xbb\xcc\xddq\x03\x86q\x04\x86q\x05Rq\x06.'
0xaabbccdd
b'\x80\x03c_ctypes\n_unpickle\nq\x00c__main__\nD\nq\x01}q\x02C\x04\xaa\xbb\xcc\xddq\x03\x86q\x04\x86q\x05Rq\x06.'
0xaabbccdd
waiting for the data...
b'\xaa\xbb\xcc\xdd'
0xaabbccdd
0xddccbbaa
closing...本例主要考查客户端sdata.x=0xaabbccdd在服务器端的输出来理解大端序和小端序的区别,考查依据是只有当服务器端的unpack次序和客户端数据实际存放次序一致时才能输出正确结果。再次重申,大、小端序只对多字节类型的数据有效。客户端实例对象sdata被序列化成字节串后发住服务器,所以,服务器端原始data,以及分别解析为大端序、小端序的data1、data2输出结果都相同,data1和data2通过pickle.loads还原的obj.x也相同。客户端第二次将sdata.x pack为网络序(一般为大端序)的c类型unsigned int后发送给服务器,很容易看到解析为大端序的结果0xaabbccdd与客户端sdata.x一致。
5.3 位字段
前面在介绍structure/union对齐的时候_fields_中出现过("xbit",c_int64,33)这样的元组。这实际上在定义一个位字段。可以创建带位字段(bit field,位域)的structure/union,只有整型字段才有位字段,由_fields_中元组第三项指定位宽:
>>> class Int(Structure):
_fields_ = [("first_16", c_int, 16),
("second_16", c_int, 16)]
>>> print(Int.first_16)
>>> print(Int.second_16)
>>> obj=Int(0xaa,0xbb)
>>> sizeof(obj)
4
>>> class Int(Structure):
_fields_ = [("first_16", c_int, 16),
("second_16", c_int64, 16)]
>>> print(Int.first_16)
>>> print(Int.second_16)
>>> 5.4 array
array是一种序列,包含固定数量的同一类型实例对象。强烈建议用带一个正整数的 “类型繁衍”的方式创建array类型:
>>> class POINT(Structure):
_fields_ = [("x", c_int),
("y", c_int)]
>>> TenPointsArrayType = POINT * 10
>>> class MyStruct(Structure):
_fields_ = [("a", c_int),
("b", c_float),
("point_array", POINT * 4)]
>>> print(len(MyStruct().point_array))
4
>>>如果TenPointsArrayType可视为一种显式数组类型,那么“POINT * 4”则是一种匿名数组类型。array实例化也很简单:
>>> arr=TenPointsArrayType()
>>> for pt in arr:
print(pt.x,pt.y)因为TenPointsArrayType初始化时内容为0,所以输出结果全为0。初始化时可以指定相应类型的初始化对象:
>>> TenIntegers = c_int * 10
>>> ii = TenIntegers(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
>>> ii
<__main__.c_long_Array_10 object at 0x00000146DBC08BC8>
>>> for i in ii:print(i,end=' ')
1 2 3 4 5 6 7 8 9 10
>>>5.5 pointer
调用ctypes的pointer()可以创建一个pointer实例对象:
>>> i = c_int(42)
>>> pi=pointer(i)
>>>pointer实例对象有一个contents属性,它返回一个pointer所指向的对象,上面这个例子就是i:
>>> pi.contents
c_long(42)
>>>注意,ctypes没有OOR(原始对象返回,机制),每次从contents属性获取一个新构建的等价对象:
>>> pi.contents is i
False
>>> pi.contents is pi.contents
False
>>>为pointer对象的contents赋另一个c_int实例将导致pointer对象指向新实例所在的内存位置:
>>> i = c_int(99)
>>> pi.contents=i
>>> pi.contents
c_long(99)
>>>pointer实例还可以被整数索引:
>>> pi[0]
99
>>>给索引赋值会改变pointer指向对象的值:
>>> i
c_long(99)
>>> pi[0]=22
>>> i
c_long(22)
>>>一个完整的例子:
>>> PI=POINTER(c_int)
>>> a=c_int(90)
>>> b=PI(a)
>>> b.contents=c_int(900)
>>> a
c_long(90)
>>> b=PI(a)
>>> b.contents
c_long(90)
>>> b.contents.value
90
>>> b.contents.value=900
>>> a
c_long(900)
>>> b[0]
900
>>> b[0]=890
>>> a
c_long(890)
>>>使用pointer对象时,可以用不同于0的索引,但必须清楚为什么这么做,就像在c中强制性访问或改变内存位置一样。一般来说如果从c函数获取到一个等价pointer对象,并且知道pointer对象实际上指向一个array而不是单一对象,那么就只能使用这个特性(非0索引访问)。
表象之下,pointer()函数远不止简单地创建pointer实例,首先得建立pointer类型,这是调用POINTER()函数完成的。POINTER()接受任意ctypes类型为参数,并返回一个新类型:
>>> PI=POINTER(c_int)
>>> PI
>>> PI(42)
TypeError: expected c_long instead of int
>>> PI(c_int(42))
<__main__.LP_c_long object at 0x000001FD2FB97A48>
>>> 调用pointer()的时候如果没有给定初始化对象则会创建一个NULL(空) pointer。NULL指针对象等效False布尔值:
>>> null_ptr=POINTER(c_int)()
>>> bool(null_ptr)
False
>>>ctypes在解引用pointer对象(去掉引用形式的引用,获取所指对象)的时候会做NULL检查(解引用一个非法的非NULL指针对象会致python崩溃):
>>> null_ptr[0]
ValueError: NULL pointer access
>>> null_ptr[0]=1234
ValueError: NULL pointer access
>>>5.6 类型转换
通常情况下ctypes会做严格类型检查。这意味着如果POINTER(c_int)出现在一个函数argtypes列表或作为一个structure定义的字段成员类型,函数参数或结构字段只能接受与该类型完全相同的实例对象。实际上,在ctypes接受其他对象之处存在一些例外。例如,传递相容的array实例来替代pointer实例。所以,对于POINTER(c_int),ctypes接受一个对等的c_int型array:
>>> class Bar(Structure):
_fields_ = [("count", c_int), ("values", POINTER(c_int))]
>>> bar=Bar()
>>> bar.values=POINTER(c_int)(c_int(90))
>>> bar.values
<__main__.LP_c_long object at 0x000001FD2FB97B48>
>>> bar.values.contents.value
90
>>> bar.values=90
TypeError: expected LP_c_long instance, got int
>>> bar.count=3
>>> bar.values=(c_int*3)(1,2,3)
>>> for i in range(bar.count):
print(bar.values[i],end=" ")
1 2 3
>>>这也就是说,array实例和pointer实例是相容的,可以相互转换。
此外,如果一个函数参数显式地在argtypes中声明为pointer类型,比如POINTER(c_int),那么可以把pointer所指类型的实例对象(本例中为c_int实例)传给函数作参数。ctypes将会自动地调用byref()进行必要转换,即POINTER和pointer也是相容的。
>>> bar=Bar()
>>> arr=(c_int*3)(1,2,3)
>>> ptr=pointer(c_int(90))
>>> PTR=POINTER(c_int)(c_int(90))
>>> bar.values=arr
>>> bar.values=ptr
>>> bar.values=PTR
>>> bar.values=90
TypeError: expected LP_c_long instance, got int
>>>要设置一个POINTER类型字段为NULL,可以直接赋值None:
>>> bar.values=None
>>>在c语言中,一种类型可以转换成另一种类型。对于类型不相容的实例,ctypes提供一个与c类型转换作用相同的cast()函数进行类型转换。之前定义的Bar结构values字段接受一个POINTER(c_int)对象(及其相容对象),而不是其他类型的对象:
>>> bar.values=(c_byte*4)()
TypeError: incompatible types, c_byte_Array_4 instance instead of LP_c_long instance
>>>这种情况cast()函数就很有用。
cast()函数可用于将一种ctypes类型实例转换成另一种ctypes数据类型的pointer对象。cast()有两个参数,一个参数是能转换成某种类型pointer的ctypes对象,一个参数是pointer类型。cast()返回一个和第一个参数引用内存块相同的第二个参数指定类型的实例。
>>> a=(c_byte*4)()
>>> cast(a,POINTER(c_int))
<__main__.LP_c_long object at 0x000001FD2FFDF248>
>>>所以,cast()可用来为Bar结构的values字段赋值:
>>> bar=Bar()
>>> bts=(c_ubyte*4)(0xdd,0xcc,0xbb,0xaa)
>>> bar.values=cast(bts,POINTER(c_int))
>>> bar.values.contents.value
-1430532899
>>> hex(cast(bar.values,POINTER(c_uint)).contents.value)
'0xaabbccdd'
>>>5.7 不完全类型
不完全类型指尚未实际定义成员的structure、union或array。c语言中,它们可以通过声明在前而在定义在后的方式来指定:
struct cell;
...
struct cell {
char* name;
struct cell *next;
};如下所示,直接将它们转换成ctypes代码,但实际无效:
>>> class cell(Structure):
_fields_ = [("name", c_char_p),
("next", POINTER(cell))]
NameError: name 'cell' is not defined
>>>这是因为在目前class语句中新类cell不可用。解决方案是,先定义cell类,再在class语句后面设置_fields_属性(只能设置一次):
>>> class cell(Structure):pass
>>> cell._fields_ = [("name", c_char_p),
("next", POINTER(cell))]
>>> cell._fields_ = [("name", c_wchar_p),
("next", POINTER(cell))]
AttributeError: _fields_ is final下面来试一试。创建两个cell实例,让它们互相指向彼此,然后按指向链遍历几次:
>>> c1=cell()
>>> c1.name='白天'.encode('utf-8')
>>> c2=cell()
>>> c2.name=b'night'
>>> c1.next=pointer(c2)
>>> c2.next=pointer(c1)
>>> p=c1
>>> for i in range(8):
print(p.name.decode('utf-8'),end=' ')
p=p.next[0]
白天 night 白天 night 白天 night 白天 night
>>>5.8 回调函数
ctypes能从python的callable对象创建c函数pointer对象。这类对象有时候被称为回调函数(callback function)。
首先,必须为回调函数创建一个类型。这个类型要能确定函数的调用约定,返回类型,接受的参数类型和数量。这可以通过下面的工厂函数来完成。
工厂函数CFUNCTYPE()创建cdecl调用约定的回调函数类型。windows中,WINFUNCTYPE()工厂函数创建stdcall调用约定的回调函数类型。
这两个工厂函数调用时,第一个参数为返回类型,剩下的参数则为回调函数所要求的参数(数量与类型)。
下面举一个使用标准c函数库qsort()的例子,qsort()函数借助一个回调函数对数据项进行排序,在这里用于对整数array排序:
>>> IntArray=c_int*5
>>> ia=IntArray(5,1,7,33,99)
>>> qsort=cdll.msvcrt.qsort
>>> qsort.restype=None
>>>调用qsort()的时候必须有以下几个参数:一个指向待排序数据的pointer(可以是数组),array中项目的数量,各项大小,以及一个回调函数(一个指向用于自定义何谓“比较”的比较函数pointer)。回调函数被调用的时候带有两个指向数据项的pointer,并且如果第一项比第二项小必须返回负整数,二者相等必须返回0,第一项比第二项大必须返回正整数。
所以,回调函数接受两个指向整数的pointer,并返回一个整数。下面就来创建回调函数的类型:
>>> CMPFUNC=CFUNCTYPE(c_int,POINTER(c_int),POINTER(c_int))
>>>排序之前,这里先定义一个简单的回调函数来显示每次传递过来的值:
>>> def py_cmp_func(a,b):
print('py_cmp_func',a[0],b[0])
return 0
>>> cmp_func=CMPFUNC(py_cmp_func)
>>> qsort(ia,len(ia),sizeof(c_int),cmp_func)
py_cmp_func 1 5
py_cmp_func 7 5
py_cmp_func 33 5
py_cmp_func 99 5
py_cmp_func 1 99
py_cmp_func 7 99
py_cmp_func 33 99
py_cmp_func 1 33
py_cmp_func 7 33
py_cmp_func 1 7
>>>现在来真正完成两项间的比较并返回相应的比较结果:
>>> def py_cmp_func(a,b):
print('py_cmp_func',a[0],b[0])
return a[0]-b[0]
>>> cmp_func=CMPFUNC(py_cmp_func)
>>> ia=IntArray(5,1,7,33,99)
>>> qsort(ia,len(ia),sizeof(c_int),cmp_func)
py_cmp_func 1 5
py_cmp_func 7 5
py_cmp_func 33 7
py_cmp_func 99 33
py_cmp_func 1 5
py_cmp_func 7 5
py_cmp_func 33 7
py_cmp_func 1 5
py_cmp_func 7 5
py_cmp_func 1 5
>>>最终排序结果:
>>> for i in ia:print(i,end=' ')
1 5 7 33 99
>>>注意:只要CFUNCTYPE()对象被用于c代码,就务必要确保对它们的持续引用。ctypes不会而如果程序员也不的话,则它们可能被垃圾回收机制回收,从而在创建回调函数时给予程序致命一击,类似如下所示:
>>> cmp_func=98
>>> qsort(ia,len(ia),sizeof(c_int),cmp_func)
OSError: exception: access violation writing 0x0000000000000062同时也要注意到,如果回调函数被创建自python控制之外的线程调用(如通过外部代码调用回调函数),ctypes会在每次请求调用时创建一个全新虚拟python线程来执行回调函数。这一行为符合大多数潜在期望和预想,但有一样例外,用threading.local存放的值将不会在不同回调过程中存活(只在本次调用中是同一对象),甚至即便它们是被同一c线程调用。
5.9 DLL导出变量
一些共享函数库不仅导出函数,而且也导出变量。python库的一个例子是Py_OptimizeFlag,其值为整数0,1或2,这取决于启动时给定的标志是-O还是-OO。
ctypes使用所访问变量对应的ctypes类型的in_dll()类方法来访问这样的值。pythonapi是给定的要访问的python c API预定义符号:
>>> opt_flag = c_int.in_dll(pythonapi, "Py_OptimizeFlag")
>>> opt_flag
c_long(0)
>>>
C:\Users\cyx>python -O
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from ctypes import *
>>> opt_flag = c_int.in_dll(pythonapi, "Py_OptimizeFlag")
>>> opt_flag
c_long(1)
>>>下面这个扩展例子示范pointer的使用,该pointer访问导出自python的PyImport_FrozenModules。
原文档PyImport_FrozenModules变量参考引用如下:
This pointer is initialized to point to an array of struct_frozen records, terminated by one whose members are all NULL or zero. When a frozen module is imported, it is searched in this table. Third-party code could play tricks with this to provide a dynamically created collection of frozen modules.
所以,对pointer对象PyImport_FrozenModules的处理非常有用。为限制例子的大小,例中仅展示如何用ctypes读取PyImport_FrozenModules:
>>> class struct_frozen(Structure):
_fields_ = [("name", c_char_p),
("code", POINTER(c_ubyte)),
("size", c_int)]
>>>现在仅是定义struct_frozen数据类型,还要获取指向PyImport_FrozenModules的pointer:
>>> FrozenTable = POINTER(struct_frozen)
>>> table = FrozenTable.in_dll(pythonapi, "PyImport_FrozenModules")
>>>由于table是一个指向struct_frozen数组记录的pointer,所以可以对它反复迭代访问。但因为pointer没有大小,所以一定要确保循环能够终止,否则迟早会因访问违规或别的原因崩溃。最好是在遇到NULL入口的时候主动终止并跳出循环:
>>> for item in table:
if item.name is None:
break
print(item.name.decode("ascii"), item.size)
_frozen_importlib 29089
_frozen_importlib_external 38876
__hello__ 139
__phello__ -139
__phello__.spam 139
>>>事实上,标准python有一个冻结模块和一个冻结包(size显示为负)并不为人所知,仅用于测试。可以试着导入看看(如import __hello__)。
5.10彩蛋
ctypes中有些实际结果远超一般预期的“彩蛋”。
5.10.1 交错的内部关系
>>> from ctypes import *
>>> class POINT(Structure):
_fields_ = ("x", c_int), ("y", c_int)
>>> class RECT(Structure):
_fields_ = ("a", POINT), ("b", POINT)
>>> p1=POINT(1,2)
>>> p2=POINT(3,4)
>>> RC=RECT(p1,p2)
>>> print(RC.a.x,RC.a.y,RC.b.x,RC.b.y)
1 2 3 4
>>> RC.a,RC.b=RC.b,RC.a
>>>
结果当然应该是3 4 1 2。想多了。
>>> print(RC.a.x,RC.a.y,RC.b.x,RC.b.y)
3 4 3 4
>>>竟然是3 4 3 4,发生了什么?
下面是“RC.a,RC.b=RC.b,RC.a”的实际过程:
>>> temp0, temp1 = RC.b, RC.a
>>> RC.a = temp0
>>> RC.b = temp1
>>>temp0、temp1是使用RC内部缓存的对象。所以在执行“RC.a = temp0”时把temp0缓存的内容复制到RC相应缓存中(RC.a)。(因为RC.a被temp1使用)轮换下来,temp1的内容也发生变化,所以最后“RC.b = temp1”就不会出现所期待的结果。
>>> for i in range(4):exec("A"+str(i)+"=type('A%d',(object,),{})"%i)
>>> a=A0();b=A1();c=A2();d=A3()
>>> a,b=c,d
>>> a is c
True
>>> temp0, temp1 = RC.b, RC.a
>>> temp0 is RC.b
False
>>> temp0.x
3
>>> temp0.x=33
>>> RC.b.x
33
>>>一定要记住,从structure、union、array获取子成员对象不要用copy(类似浅复制,“=”语义发生改变),而是获取一个可访问根对象内部缓存的封装(代理)对象。
>>> import copy
>>> print(RC.a.x,RC.a.y,RC.b.x,RC.b.y)
1 2 3 4
>>> class record:
def __init__(self,RC):
self.a=copy.deepcopy(RC.a)
self.b=copy.deepcopy(RC.b)
>>> rRC=record(RC)
>>> print(rRC.a.x,rRC.a.y,rRC.b.x,rRC.b.y)
1 2 3 4
>>> rRC.a.x=11;rRC.a.y=22
>>> print(rRC.a.x,rRC.a.y,rRC.b.x,rRC.b.y)
11 22 3 4
>>> print(RC.a.x,RC.a.y,RC.b.x,RC.b.y)
1 2 3 4
>>>5.10.2 是我非我
>>> s=c_char_p()
>>> s.value=b"abc def ghi"
>>> s.value
b'abc def ghi'
>>> s.value is s.value
False
>>>另一个可能不同于个人预期的例子如上所示。
为什么结果为False?每个ctypes实例对象包含一个内存块,外加对内存块内容进行访问的描述符。使用时,会在内存块中存放一个非自身的python对象以替代所存对象的内容,也就是说,每次访问内容(value)时都将重新构造一个新的python对象。
6、可变数据类型
这里的可变主要是指大小可变。ctypes支持可变array和structure。
resize()函数可用于重置一个已存在的ctypes对象内存块大小,带有两个参数,一个是对象,一个是请求的以字节为单位的内存块大小。内存块大小不得小于指定对象的类型对应的大小,否则会抛出ValueError异常:
>>> short_array=(c_short*4)()
>>> sizeof(short_array)
8
>>> resize(short_array,4)
ValueError: minimum size is 8
>>> resize(short_array,32)
>>> sizeof(short_array)
32
>>> len(short_array)
4
>>> sizeof(type(short_array))
8
>>>这种特性除了好还是好,总之非常好。那么如何才能访问到数组中新增的元素呢?由于short_array的类型对外声称的仍是4个元素,如果访问其他元素将出现错误:
>>> short_array[:]
[0, 0, 0, 0]
>>> short_array[7]
IndexError: invalid index
>>>通过ctypes配合可变数据类型使用的另一种方式是利用python的动态特性,并根据实际情况在已知所需内存大小后定义或重新定义数据类型:
>>> short_array=(c_short*16)()还有一种比较危险的方式:
>>> short_arr=(c_short*15)()
>>> short_arr[:]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> resize(short_arr,40)
>>> a=POINTER(c_short)(short_arr)
>>> length=sizeof(short_arr)//sizeof(c_short)
>>> for i in range(length):a[i]=i
>>> short_arr[:]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
>>> for i in range(length):print(a[i],end=' ')
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
>>>本教程翻译、整理、注解自官网文档,更多版本、平台、使用指南等细节,请参考:
https://docs.python.org/release/3.6.5/library/ctypes.html