睿智的目标检测47——Keras 利用mobilenet系列(v1,v2,v3)搭建yolov4-lite目标检测平台
睿智的目标检测47——Keras 利用mobilenet系列(v1,v2,v3)搭建yolov4-lite目标检测平台
- 学习前言
- 源码下载
- 网络替换实现思路
-
- 1、网络结构解析与替换思路解析
- 2、mobilenet系列网络介绍
-
- a、mobilenetV1介绍
- b、mobilenetV2介绍
- c、mobilenetV3介绍
- 3、将特征提取结果融入到yolov4网络当中
- 如何训练自己的mobilenet-yolo4
-
- 1、训练参数指定
- 2、开始训练
学习前言
一起来看看如何利用mobilenet系列搭建yolov4目标检测平台。
源码下载
https://github.com/bubbliiiing/mobilenet-yolov4-lite-keras
喜欢的可以点个star噢。
网络替换实现思路
1、网络结构解析与替换思路解析
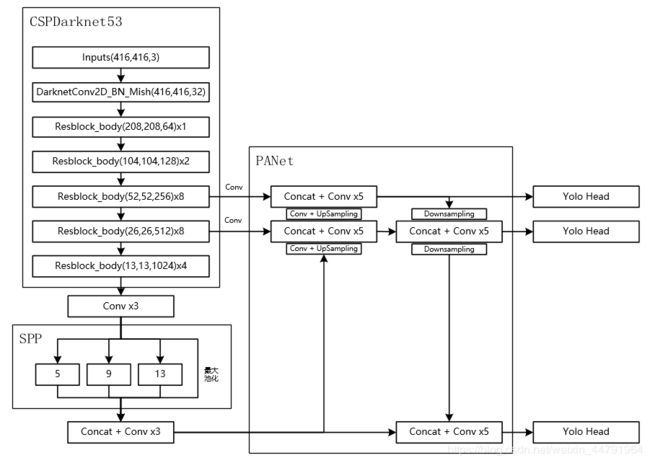
对于YoloV4而言,其整个网络结构可以分为三个部分。
分别是:
1、主干特征提取网络Backbone,对应图像上的CSPdarknet53
2、加强特征提取网络,对应图像上的SPP和PANet
3、预测网络YoloHead,利用获得到的特征进行预测
其中:
第一部分主干特征提取网络的功能是进行初步的特征提取,利用主干特征提取网络,我们可以获得三个初步的有效特征层。
第二部分加强特征提取网络的功能是进行加强的特征提取,利用加强特征提取网络,我们可以对三个初步的有效特征层进行特征融合,提取出更好的特征,获得三个更有效的有效特征层。
第三部分预测网络的功能是利用更有效的有效特整层获得预测结果。
在这三部分中,第1部分和第2部分可以更容易去修改。第3部分可修改内容不大,毕竟本身也只是3x3卷积和1x1卷积的组合。
mobilenet系列网络可用于进行分类,其主干部分的作用是进行特征提取,我们可以使用mobilenet系列网络代替yolov4当中的CSPdarknet53进行特征提取,将三个初步的有效特征层相同shape的特征层进行加强特征提取,便可以将mobilenet系列替换进yolov4当中了。
2、mobilenet系列网络介绍
本文共用到三个主干特征提取网络,分别是mobilenetV1、mobilenetV2、mobilenetV3。
a、mobilenetV1介绍
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积块)。
对于一个卷积点而言:
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积结构块,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
如下这张图就是depthwise separable convolution的结构
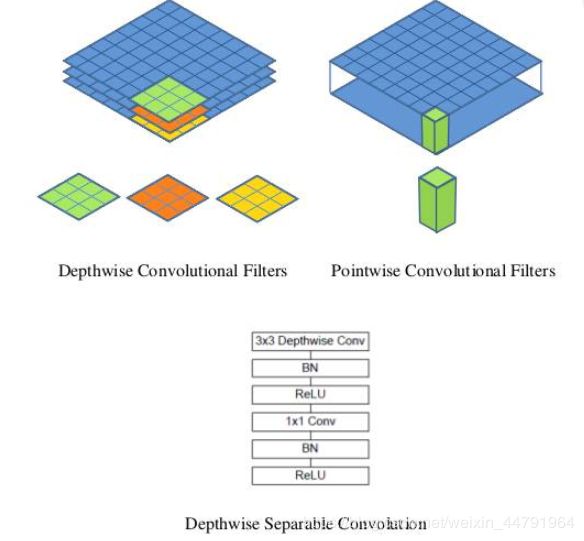
在建立模型的时候,可以使用Keras中的DepthwiseConv2D层实现深度可分离卷积,然后再利用1x1卷积调整channels数。
通俗地理解就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。
如下就是MobileNet的结构,其中Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理,
上图所示是的mobilenetV1-1的结构,我们可以设置mobilenetV1的alpha值改变它的通道数。
对于yolov4来讲,我们需要取出它的最后三个shape的有效特征层进行加强特征提取。
在代码中,我们取出了out1、out2、out3。
#-------------------------------------------------------------#
# MobileNet的网络部分
#-------------------------------------------------------------#
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D, Activation, DepthwiseConv2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
import keras.backend as backend
def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1):
pointwise_conv_filters = int(pointwise_conv_filters * alpha)
# 深度可分离卷积
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(inputs)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
# 1x1卷积
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def _conv_block(inputs, filters, alpha, kernel=(3, 3), strides=(1, 1)):
filters = int(filters * alpha)
x = Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv1')(inputs)
x = BatchNormalization(name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def relu6(x):
return K.relu(x, max_value=6)
def MobileNetV1(inputs,alpha=1,depth_multiplier=1):
if alpha not in [0.25, 0.5, 0.75, 1.0]:
raise ValueError('Unsupported alpha - `{}` in MobilenetV1, Use 0.25, 0.5, 0.75, 1.0'.format(alpha))
# 416,416,3 -> 208,208,32
x = _conv_block(inputs, 32, alpha, strides=(2, 2))
# 208,208,32 -> 208,208,64
x = _depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1)
# 208,208,64 -> 104,104,128
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier,
strides=(2, 2), block_id=2)
x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3)
# 104,104.128 -> 64,64,256
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier,
strides=(2, 2), block_id=4)
x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5)
feat1 = x
# 64,64,256 -> 32,32,512
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier,
strides=(2, 2), block_id=6)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11)
feat2 = x
# 32,32,512 -> 16,16,1024
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, block_id=13)
feat3 = x
return feat1,feat2,feat3
if __name__ == "__main__":
from keras.layers import Input
from keras.models import Model
alpha = 0.25
inputs = Input([None,None,3])
outputs = MobileNetV1(inputs,alpha=alpha)
model = Model(inputs,outputs)
model.summary()
b、mobilenetV2介绍
MobileNetV2是MobileNet的升级版,它具有一个非常重要的特点就是使用了Inverted resblock,整个mobilenetv2都由Inverted resblock组成。
Inverted resblock可以分为两个部分:
左边是主干部分,首先利用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维。
右边是残差边部分,输入和输出直接相接。

整体网络结构如下:(其中Inverted resblock进行的操作就是上述结构)

#-------------------------------------------------------------#
# MobileNetV2的网络部分
#-------------------------------------------------------------#
import math
import numpy as np
import tensorflow as tf
from keras import backend
from keras.preprocessing import image
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers import Conv2D, Add, ZeroPadding2D, GlobalAveragePooling2D, Dropout, Dense
from keras.layers import MaxPooling2D,Activation,DepthwiseConv2D,Input,GlobalMaxPooling2D
from keras.applications import imagenet_utils
from keras.applications.imagenet_utils import decode_predictions
from keras.utils.data_utils import get_file
# TODO Change path to v1.1
BASE_WEIGHT_PATH = ('https://github.com/JonathanCMitchell/mobilenet_v2_keras/'
'releases/download/v1.1/')
# relu6!
def relu6(x):
return backend.relu(x, max_value=6)
# 用于计算padding的大小
def correct_pad(inputs, kernel_size):
img_dim = 1
input_size = backend.int_shape(inputs)[img_dim:(img_dim + 2)]
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if input_size[0] is None:
adjust = (1, 1)
else:
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
# 使其结果可以被8整除,因为使用到了膨胀系数α
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def _inverted_res_block(inputs, expansion, stride, alpha, filters, block_id):
in_channels = backend.int_shape(inputs)[-1]
pointwise_conv_filters = int(filters * alpha)
pointwise_filters = _make_divisible(pointwise_conv_filters, 8)
x = inputs
prefix = 'block_{}_'.format(block_id)
# part1 数据扩张
if block_id:
# Expand
x = Conv2D(expansion * in_channels,
kernel_size=1,
padding='same',
use_bias=False,
activation=None,
name=prefix + 'expand')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name=prefix + 'expand_BN')(x)
x = Activation(relu6, name=prefix + 'expand_relu')(x)
else:
prefix = 'expanded_conv_'
if stride == 2:
x = ZeroPadding2D(padding=correct_pad(x, 3),
name=prefix + 'pad')(x)
# part2 可分离卷积
x = DepthwiseConv2D(kernel_size=3,
strides=stride,
activation=None,
use_bias=False,
padding='same' if stride == 1 else 'valid',
name=prefix + 'depthwise')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name=prefix + 'depthwise_BN')(x)
x = Activation(relu6, name=prefix + 'depthwise_relu')(x)
# part3压缩特征,而且不使用relu函数,保证特征不被破坏
x = Conv2D(pointwise_filters,
kernel_size=1,
padding='same',
use_bias=False,
activation=None,
name=prefix + 'project')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name=prefix + 'project_BN')(x)
if in_channels == pointwise_filters and stride == 1:
return Add(name=prefix + 'add')([inputs, x])
return x
def MobileNetV2(inputs, alpha=1.0):
if alpha not in [0.5, 0.75, 1.0, 1.3]:
raise ValueError('Unsupported alpha - `{}` in MobilenetV2, Use 0.5, 0.75, 1.0, 1.3'.format(alpha))
# stem部分
first_block_filters = _make_divisible(32 * alpha, 8)
x = ZeroPadding2D(padding=correct_pad(inputs, 3),
name='Conv1_pad')(inputs)
# 416,416,3 -> 208,208,32
x = Conv2D(first_block_filters,
kernel_size=3,
strides=(2, 2),
padding='valid',
use_bias=False,
name='Conv1')(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999,
name='bn_Conv1')(x)
x = Activation(relu6, name='Conv1_relu')(x)
# 208,208,32 -> 208,208,16
x = _inverted_res_block(x, filters=16, alpha=alpha, stride=1,
expansion=1, block_id=0)
# 208,208,16 -> 104,104,24
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=2,
expansion=6, block_id=1)
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=1,
expansion=6, block_id=2)
# 104,104,24 -> 52,52,32
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=2,
expansion=6, block_id=3)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=4)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=5)
feat1 = x
# 52,52,32 -> 26,26,96
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=2,
expansion=6, block_id=6)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1,
expansion=6, block_id=7)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1,
expansion=6, block_id=8)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1,
expansion=6, block_id=9)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1,
expansion=6, block_id=10)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1,
expansion=6, block_id=11)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1,
expansion=6, block_id=12)
feat2 = x
# 26,26,96 -> 13,13,320
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=2,
expansion=6, block_id=13)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1,
expansion=6, block_id=14)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1,
expansion=6, block_id=15)
x = _inverted_res_block(x, filters=320, alpha=alpha, stride=1,
expansion=6, block_id=16)
feat3 = x
return feat1,feat2,feat3
c、mobilenetV3介绍
mobilenetV3使用了特殊的bneck结构。
bneck结构如下图所示:
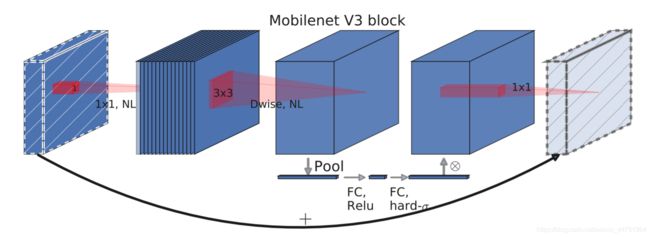
它综合了以下四个特点:
a、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
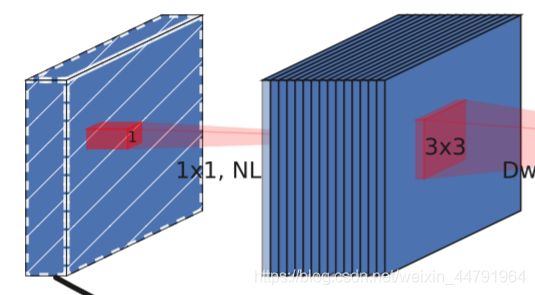
即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
b、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
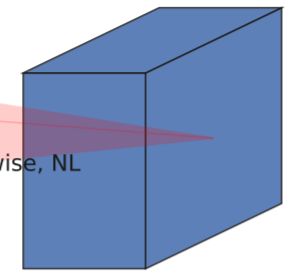
在输入1x1卷积进行升维度后,进行3x3深度可分离卷积。
c、轻量级的注意力模型。
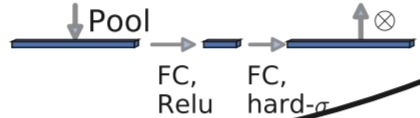
这个注意力机制的作用方式是调整每个通道的权重。
d、利用h-swish代替swish函数。
在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。
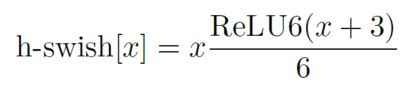
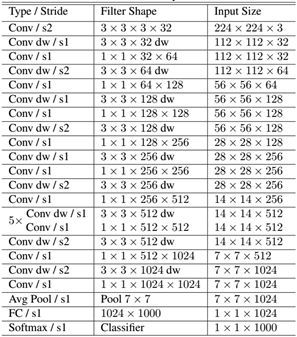
下图为整个mobilenetV3的结构图:
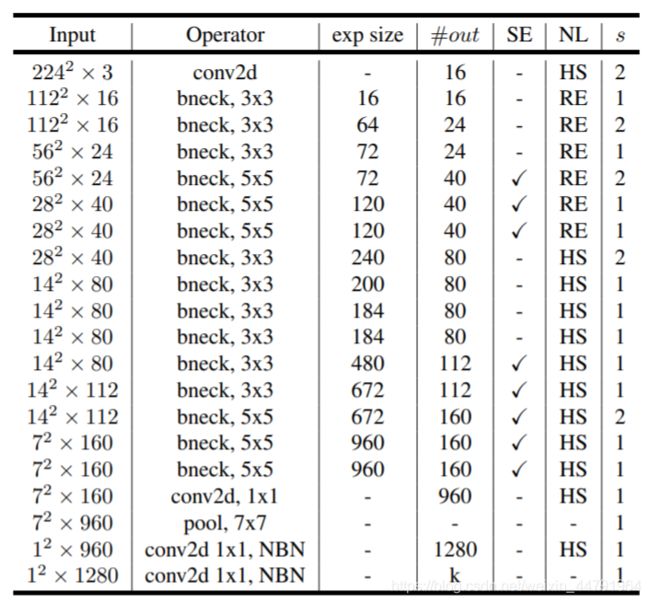
如何看懂这个表呢?我们从每一列出发:
第一列Input代表mobilenetV3每个特征层的shape变化;
第二列Operator代表每次特征层即将经历的block结构,我们可以看到在MobileNetV3中,特征提取经过了许多的bneck结构;
第三、四列分别代表了bneck内逆残差结构上升后的通道数、输入到bneck时特征层的通道数。
第五列SE代表了是否在这一层引入注意力机制。
第六列NL代表了激活函数的种类,HS代表h-swish,RE代表RELU。
第七列s代表了每一次block结构所用的步长。
from keras.layers import Conv2D, DepthwiseConv2D, Dense, GlobalAveragePooling2D, Input
from keras.layers import Activation, BatchNormalization, Add, Multiply, Reshape, Multiply
from keras.models import Model
from keras import backend
def _activation(x, name='relu'):
if name == 'relu':
return Activation('relu')(x)
elif name == 'hardswish':
return hard_swish(x)
def hard_sigmoid(x):
return backend.relu(x + 3.0, max_value=6.0) / 6.0
def hard_swish(x):
return Multiply()([Activation(hard_sigmoid)(x), x])
def _make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def _bneck(inputs, expansion, alpha, out_ch, kernel_size, stride, se_ratio, activation,
block_id):
channel_axis = 1 if backend.image_data_format() == 'channels_first' else -1
in_channels = backend.int_shape(inputs)[channel_axis]
out_channels = _make_divisible(out_ch * alpha, 8)
exp_size = _make_divisible(in_channels * expansion, 8)
x = inputs
prefix = 'expanded_conv/'
if block_id:
# Expand
prefix = 'expanded_conv_{}/'.format(block_id)
x = Conv2D(exp_size,
kernel_size=1,
padding='same',
use_bias=False,
name=prefix + 'expand')(x)
x = BatchNormalization(axis=channel_axis,
name=prefix + 'expand/BatchNorm')(x)
x = _activation(x, activation)
x = DepthwiseConv2D(kernel_size,
strides=stride,
padding='same',
dilation_rate=1,
use_bias=False,
name=prefix + 'depthwise')(x)
x = BatchNormalization(axis=channel_axis,
name=prefix + 'depthwise/BatchNorm')(x)
x = _activation(x, activation)
if se_ratio:
reduced_ch = _make_divisible(exp_size * se_ratio, 8)
y = GlobalAveragePooling2D(name=prefix + 'squeeze_excite/AvgPool')(x)
y = Reshape([1, 1, exp_size], name=prefix + 'reshape')(y)
y = Conv2D(reduced_ch,
kernel_size=1,
padding='same',
use_bias=True,
name=prefix + 'squeeze_excite/Conv')(y)
y = Activation("relu", name=prefix + 'squeeze_excite/Relu')(y)
y = Conv2D(exp_size,
kernel_size=1,
padding='same',
use_bias=True,
name=prefix + 'squeeze_excite/Conv_1')(y)
x = Multiply(name=prefix + 'squeeze_excite/Mul')([Activation(hard_sigmoid)(y), x])
x = Conv2D(out_channels,
kernel_size=1,
padding='same',
use_bias=False,
name=prefix + 'project')(x)
x = BatchNormalization(axis=channel_axis,
name=prefix + 'project/BatchNorm')(x)
if in_channels == out_channels and stride == 1:
x = Add(name=prefix + 'Add')([inputs, x])
return x
def MobileNetV3(inputs, alpha=1.0, kernel=5, se_ratio=0.25):
if alpha not in [0.75, 1.0]:
raise ValueError('Unsupported alpha - `{}` in MobilenetV3, Use 0.75, 1.0.'.format(alpha))
# 416,416,3 -> 208,208,16
x = Conv2D(16,kernel_size=3,strides=(2, 2),padding='same',
use_bias=False,
name='Conv')(inputs)
x = BatchNormalization(axis=-1,
epsilon=1e-3,
momentum=0.999,
name='Conv/BatchNorm')(x)
x = Activation(hard_swish)(x)
# 208,208,16 -> 208,208,16
x = _bneck(x, 1, 16, alpha, 3, 1, None, 'relu', 0)
# 208,208,16 -> 104,104,24
x = _bneck(x, 4, 24, alpha, 3, 2, None, 'relu', 1)
x = _bneck(x, 3, 24, alpha, 3, 1, None, 'relu', 2)
# 104,104,24 -> 52,52,40
x = _bneck(x, 3, 40, alpha, kernel, 2, se_ratio, 'relu', 3)
x = _bneck(x, 3, 40, alpha, kernel, 1, se_ratio, 'relu', 4)
x = _bneck(x, 3, 40, alpha, kernel, 1, se_ratio, 'relu', 5)
feat1 = x
# 52,52,40 -> 26,26,112
x = _bneck(x, 6, 80, alpha, 3, 2, None, 'hardswish', 6)
x = _bneck(x, 2.5, 80, alpha, 3, 1, None, 'hardswish', 7)
x = _bneck(x, 2.3, 80, alpha, 3, 1, None, 'hardswish', 8)
x = _bneck(x, 2.3, 80, alpha, 3, 1, None, 'hardswish', 9)
x = _bneck(x, 6, 112, alpha, 3, 1, se_ratio, 'hardswish', 10)
x = _bneck(x, 6, 112, alpha, 3, 1, se_ratio, 'hardswish', 11)
feat2 = x
# 26,26,112 -> 13,13,160
x = _bneck(x, 6, 160, alpha, kernel, 2, se_ratio, 'hardswish', 12)
x = _bneck(x, 6, 160, alpha, kernel, 1, se_ratio, 'hardswish', 13)
x = _bneck(x, 6, 160, alpha, kernel, 1, se_ratio, 'hardswish', 14)
feat3 = x
return feat1,feat2,feat3
3、将特征提取结果融入到yolov4网络当中
对于yolov4来讲,我们需要利用主干特征提取网络获得的三个有效特征进行加强特征金字塔的构建。
利用上一步定义的MobilenetV1、MobilenetV2、MobilenetV3三个函数我们可以获得每个Mobilenet网络对应的三个有效特征层。
我们可以利用这三个有效特征层替换原来yolov4主干网络CSPdarknet53的有效特征层。
为了进一步减少参数量,我们可以使用深度可分离卷积代替yoloV4中用到的普通卷积。
实现代码如下:
from functools import wraps
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D, Activation, DepthwiseConv2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from nets.mobilenet_v1 import MobileNetV1
from nets.mobilenet_v2 import MobileNetV2
from nets.mobilenet_v3 import MobileNetV3
from utils.utils import compose
def relu6(x):
return K.relu(x, max_value=6)
#--------------------------------------------------#
# 单次卷积
#--------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {
}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块
# Conv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {
'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
Activation(relu6))
#---------------------------------------------------#
# 卷积块
# DepthwiseConv2D + BatchNormalization + Relu6
#---------------------------------------------------#
def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha = 1,
depth_multiplier=1, strides=(1, 1), block_id=1):
pointwise_conv_filters = int(pointwise_conv_filters * alpha)
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False)(inputs)
x = BatchNormalization()(x)
x = Activation(relu6)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1))(x)
x = BatchNormalization()(x)
return Activation(relu6)(x)
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def make_five_convs(x, num_filters):
# 五次卷积
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = _depthwise_conv_block(x, num_filters*2,alpha=1)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = _depthwise_conv_block(x, num_filters*2,alpha=1)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def yolo_body(inputs, num_anchors, num_classes, backbone="mobilenetv1", alpha=1):
# 生成darknet53的主干模型
if backbone=="mobilenetv1":
feat1,feat2,feat3 = MobileNetV1(inputs, alpha=alpha)
elif backbone=="mobilenetv2":
feat1,feat2,feat3 = MobileNetV2(inputs, alpha=alpha)
elif backbone=="mobilenetv3":
feat1,feat2,feat3 = MobileNetV3(inputs, alpha=alpha)
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenetv1, mobilenetv2, mobilenetv3.'.format(backbone))
P5 = DarknetConv2D_BN_Leaky(int(512* alpha), (1,1))(feat3)
P5 = _depthwise_conv_block(P5, int(1024* alpha))
P5 = DarknetConv2D_BN_Leaky(int(512* alpha), (1,1))(P5)
maxpool1 = MaxPooling2D(pool_size=(13,13), strides=(1,1), padding='same')(P5)
maxpool2 = MaxPooling2D(pool_size=(9,9), strides=(1,1), padding='same')(P5)
maxpool3 = MaxPooling2D(pool_size=(5,5), strides=(1,1), padding='same')(P5)
P5 = Concatenate()([maxpool1, maxpool2, maxpool3, P5])
P5 = DarknetConv2D_BN_Leaky(int(512* alpha), (1,1))(P5)
P5 = _depthwise_conv_block(P5, int(1024* alpha))
P5 = DarknetConv2D_BN_Leaky(int(512* alpha), (1,1))(P5)
P5_upsample = compose(DarknetConv2D_BN_Leaky(int(256* alpha), (1,1)), UpSampling2D(2))(P5)
P4 = DarknetConv2D_BN_Leaky(int(256* alpha), (1,1))(feat2)
P4 = Concatenate()([P4, P5_upsample])
P4 = make_five_convs(P4,int(256* alpha))
P4_upsample = compose(DarknetConv2D_BN_Leaky(int(128* alpha), (1,1)), UpSampling2D(2))(P4)
P3 = DarknetConv2D_BN_Leaky(int(128* alpha), (1,1))(feat1)
P3 = Concatenate()([P3, P4_upsample])
P3 = make_five_convs(P3,int(128* alpha))
P3_output = _depthwise_conv_block(P3, int(256* alpha))
P3_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P3_output)
#26,26 output
P3_downsample = _depthwise_conv_block(P3, int(256* alpha), strides=(2,2))
P4 = Concatenate()([P3_downsample, P4])
P4 = make_five_convs(P4,int(256* alpha))
P4_output = _depthwise_conv_block(P4, int(512* alpha))
P4_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P4_output)
#13,13 output
P4_downsample = _depthwise_conv_block(P4, int(512* alpha), strides=(2,2))
P5 = Concatenate()([P4_downsample, P5])
P5 = make_five_convs(P5,int(512* alpha))
P5_output = _depthwise_conv_block(P5, int(1024* alpha))
P5_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P5_output)
return Model(inputs, [P5_output, P4_output, P3_output])
如何训练自己的mobilenet-yolo4
1、训练参数指定
本文一共使用了三个主干特征提取网络,我们可以在train.py当中进行指定。
backbone参数用于指定所用的主干特征提取网络,可以在mobilenetv1, mobilenetv2, mobilenetv3中进行选择。
alpha参数用于指定当前所使用的mobilenet系列网络的通道变化情况,默认状态下为1。
mobilenetv1的alpha可选范围为0.25、0.5、0.75、1.0。
mobilenetv2的alpha可选范围为0.5、0.75、1.0、1.3。
mobilenetv3的alpha可选范围为0.75、1.0。
训练前需要注意所用mobilenet版本、alpha值和预训练权重的对齐。
2、开始训练
yolo3整体的文件夹构架如下:
本文使用VOC格式进行训练。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。

训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。

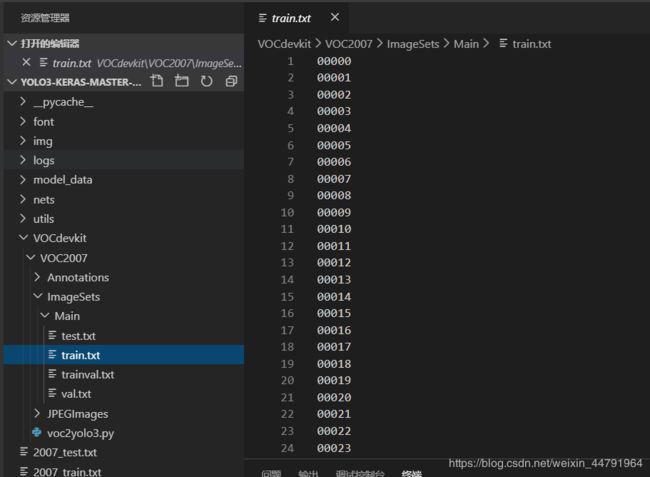
在训练前利用voc2yolo4.py文件生成对应的txt。
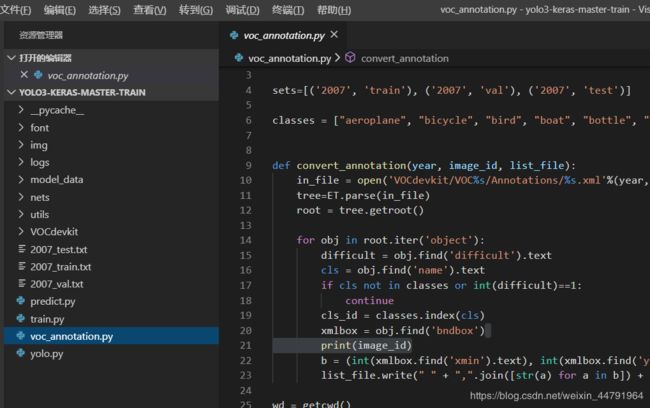
再运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
就会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。

在训练前需要修改model_data里面的voc_classes.txt文件,需要将classes改成你自己的classes。
运行train.py即可开始训练。
