深度学习在电商推荐系统的实践
导读:推荐导购场景在电商中是重要的满足用户"逛"和"买"的场景,本次分享我们聚焦深度学习在阿里B2B电商 ( 1688 ) 推荐系统中的应用,其中包括商品推荐中召回 ( 多兴趣Deep Match ),排序 ( 自研DMR ) 的相关工作,以及在新兴的互动内容场景 ( 直播、短视频 ) 中通过异构网络来解决异构信息的精准匹配问题。
本文分享大纲如下:
-
发展历史
-
商品召回:Deep Match
-
商品排序:DIN-DIEN, DMR
-
内容推荐:直播排序
发展历史
下图是1688推荐系统这三年发展的一个的roadmap:

1. 2017年
从17年开始,我们才更加的专注于个性化的分发,不管是搜索还是推荐。如果是做推荐的同学们也知道,一开始,我们要做召回、排序、业务的定制以及类似的一些工作。所以我们在17年的时候,主要是借助阿里之前淘系的基建,比如SWING & E-TREC这些I2I的方法,这其实就是协同过滤的升级版本,然后去进行一个基本的召回方式,以及用LR到GBDT去做一个最初始的CTR预估。然后到年底的时候,我们从LR到GBDT转换到了W&DL,因为当时,大概是16年吧,谷歌的W&DL的论文出来后,然后17年在阿里有一个比较大的场景的一些实践。可能有些针对业务定制的是我们的Unbalance I2I,这个I2I的意思呢,是我们总有一些业务是一个小的商品池,它是一个比较特定的它不是一个全域可推荐的范围,当我们进行一个大的商品触发的时候,就是定向的往这个小的商品池里触发。
2. 2018年
18年深度学习在业界越来越火了,所以我们顺着这个潮流,在排序当中是走到了DIN和DIEN,这两个工作是阿里妈妈北京的团队做的在广告上的一个CTR的模型的排序,以及顺着Youtube的Deep Match的工作我们也做了我们这边的Deep Match,以及一些机制的构建,补足了之前我们只有CTR模型没有CVR模型的一个短板,一些更“标题党”的商品会往下落。
3. 2019年
在最近的一年,我们在召回上去进行了一个多兴趣点的Deep Match的尝试,在粗排上从GBDT走到了双塔,以及在排序当中,之前是借鉴公司以及业界的一些先进的经验,我们在这边有了一些自己的更多的一些创新的工作,比如说在CTR中有一些DMR,等一下会详细的讲到(AAAI 2020),还有就是在CVR模型当中走到了ESMM+MMOE这样子的模型。最近特别火的就是直播了,以及直播这种内容化的一些推荐。
商品召回
大家都知道,一开始做召回的话主要就是协同过滤类的方法,例如比较经典的I2I召回和U2I召回,1688使用过的是Deep Match U2I召回。

1. I2I召回
-
采用了SWING/E-TREC 等启发式方法,效果好,普适性高
-
因为有I2I的关系,用户要是有新的行为马上能进行一个触发,可以进行一个实时的召回
-
有解释性的保障
2. U2I召回
-
采用了优化的方法,通常比启发式方法靠谱
-
主要是由User ID来进行一个embedding的生成,新的行为进来后比较难进行实时更新(实时效率低可以进行弥补)
-
可解释性也比较差(并没有办法解决)
3. Deep Match U2I召回

16年YouTube提出的Deep Match的方法主要是解决了之前召回效率低的问题,因为这种方法是把用户的历史序列以及他对应的user profile进行一个embedding之后,然后通过MLP得到一个用户的表征,这个表征由于是实时生成,用户的足迹在不断的往里面加,那么这个效率是比较高的。Deep Match模型可以更多的用到一些商品侧的自身的一些行为、类目、属性的信息,从而能更好的构建模型。但是它的可解释性较差,另外召回是bad case还是惊喜是一个各花入各眼的过程,需要线上的ABtest给出答案。

在Youtube Deep Match的基础上,我们基于序列上下文的Attention,构建用户表征,即通过时间衰减/行为类别/停留时间等信息对用户序列进行建模,模型的结构图如上所示。
经过线上测试uv点击率 +0.92%,人均点击次数 +9.81%,发现性曝光占比 +8.04%。
Practical Lessons:
-
因为是一个match的过程,所以我们选择了随机负采样作为负样本
-
Position Embedding很有效,用户行为的远近是比较重要的
-
Item Feature Sequence能有效增加信息量
迭代方向:
-
用户多兴趣点提取
-
双塔结构,利用target的side information辅助
商品排序
1. DIN
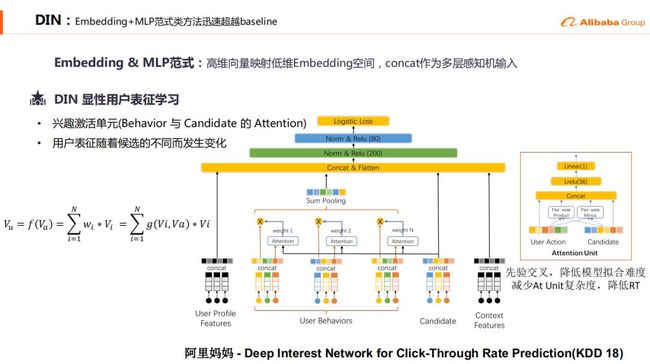
17年的时候,我们演进到了WDL的过程,然后18年的时候因为阿里妈妈在KDD18的时候发表了DIN的那篇paper,同时也在公司内部做了一些介绍,我们就顺着这个潮流从WDL走到了纯的用户向量表征再接MLP的范式。
DIN是显性的用户表征学习,对Behavior和Candidate引入了Attention使得用户表征随着候选的不同而发生变化。DIN结构如上图所示。

线上效果 ( baseline: WDL ):
-
CUN:CTR +5% ,CVR +11%
-
1688: CTR +4% , CVR + 1%
关于Attention:
-
Concat( keys, querys, keys * querys, keys - querys) + Relu + MLP
-
运算量 = 400 候选 * 50 sequence + 400 MLP
-
线上DIN在400个候选RTP打分的响应时间是 15ms
DIN没有考虑的信息:
用户长期兴趣偏好 ( 广告区别于推荐 ) 词袋模型, 序列不敏感(对最近的行为无额外偏好)没利用 raw feature
2. LSRMM
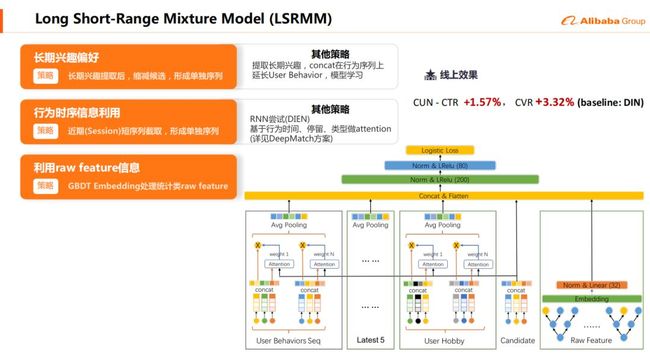
基于DIN存在的一些问题,,我们做了一些改进,提出了LSRMM ( Long Short-Range Mixture Model ),该模型能够去抽取一个长期的用户偏好。这个兴趣偏好不是整个end to end学出来的,而是直接通过离线的方式统计出用户在各个时间是否都对于一个特定的类别的东西有一个偏好。比如说像我喜欢羽毛球,那在候选中会额外的出现羽毛球。
LSRMM特点:
-
长期兴趣偏好:长期兴趣提取后,缩减候选,形成单独序列
-
行为时序信息利用:近期(session)短序列截取,形成单独序列
-
利用raw feature信息: GBDT Embedding 处理统计类raw feature
线上效果:
CUN CTR +1.57%,CVR +3.32% ( baseline:DIN )
3. DIEN
当我们知道DIN和DIEN的时候,这两篇paper都引出来了,但是为什么我们没有直接上DIEN而是用了DIN呢,主要原因就在于DIEN在用户表征里有两层GRU的结构,用GRU跑起来是一个串行的结构,它不能并行。我们预估起来它这个耗时是比较厉害的,存在一定的上线的工程风险,所以我们在这边就是先上的DIN再上的DIEN。
模型演化过程:
① GRU + Attention + GRU
② GRU + Attention + ATGRU
③ GRU + Attention + ATGRU + Auxiliary Loss

Practical Lessons—rt降低之路 ( 1000个item打分时长 )
这是我们做的一些优化以改进DIEN的效率,原版DIEN ( 350ms ):
① user feature只传一次节省通信开销 ( 340ms )
② 第一层RNN只跑一次 ( 250ms )
③ Embedding size降至32 ( 140ms ),( 这个会影响效果 )
④ 简化attention后 ( 140ms )
⑤ 分batch并发请求rtp ( 100ms以内 )
各种方法benchmark结果比较:

4. DMR:Deep Match to Rank
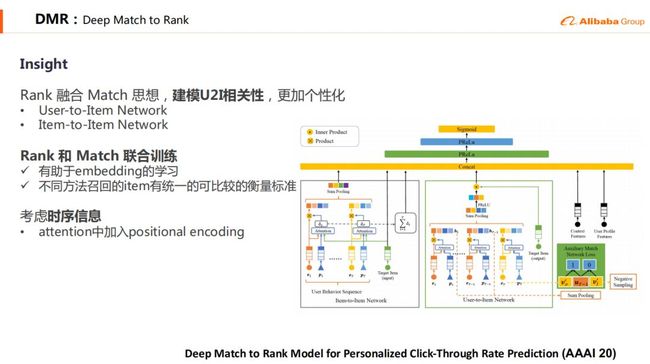
DMR是我们最新发表在AAAI2020上的论文 ( oral ),在Ranking中融合了Matching的思想,建模u2i相关性。DIN和DIEN都是聚焦用户兴趣的建模,而DMR又往前走了一步,对u2i相关性进行建模,这个相关性可以直接衡量用户对商品的偏好程度,从而提升模型的效果。这个u2i相关性是无法通过统计的方法得到的,因为通常不会给用户推荐重复的商品;也无法从召回得到,因为通过是有多路召回,每路召回的相关性不能相互比较。
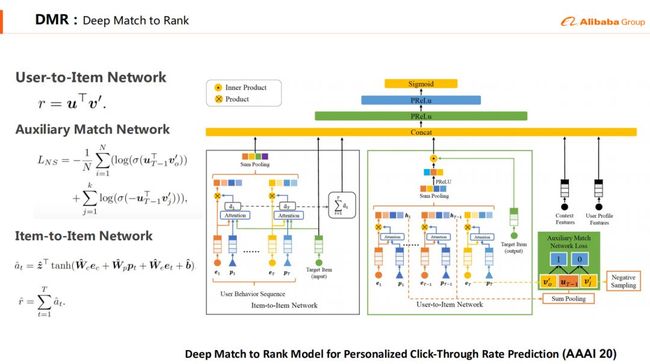
DMR提供了一个统一的任意u2i相关性的建模方法。DMR中采用两个子网络建模u2i相关性,其中User-to-Item Network直接通过user和item的向量内积建模u2i相关性,并用一个辅助的deepmatch任务联合训练,促使更大的内积表征更强的相关性,从而提升效果。Item-to-item网络采用间接的方式建模u2i相关性,类似于DIN的网络,我们先做一个target attention,这个attention权重可以理解成i2i权重,再将权重求和得到第二种u2i相关性。DMR提供了一个u2i相关性建模的范式,可以很方便的加入到其他深度模型中。
DMR的实验:
线上效果 ( DMR vs DIN ):
① uv-ctr相对提升1.23%
② 人均点击次数相对提升9.13%
③ pv-ctr相对提升3.61%
④ L-O转化相对提升1.81%
内容推荐
1688团队从2019年开始大规模的去做直播业务,最近直播有多火呢,连法院拍卖这个事情都开始上直播了。

1. 1688直播推荐的业务背景
-
电商内容化重要⽅向, 提升⽤户时长与粘性
-
B类采购批发,小商家为主, 主要类目为⼥装/童装/配饰/⾷品等
-
转化率⾼,目前频道⻚UV转化率17%, 全导购场景第⼀
-
核⼼考察指标为买家数(转化率) , 同时关注点击与⽤户时⻓
2. 直播在1688上面临的一些特色的问题
第一个呢是只用排序就行了的场景,因为每一个时段同场次在线的直播数还不过1000,不过1000的话那未必有一个召回的诉求,给1000个打个分我们的模型性能还是罩得住的,所以我们对召回诉求就不强。
第二个,直播是一个多目标学习的过程,在哪里建模也都是一个多目标的过程,比如既要点击率又要在观看时间长,又要转化率高,还有些粉丝亲密度的问题。
还有个问题是,直播这个东西,本来我们是推商品的,这边又开始推直播了,我们就想直播和商品之间是一个什么样的关系,是不是一个商品很不错,它对应的一个老板做直播就很不错,其实答案是否定的。就是商品和商家的直播之间还是不一样的,有很多商家日常商品经营做的好的,未必就是直播做的好的。所以在这里它是一个内容的异构网络。
接下来我们讲介绍整体的算法迭代流程。
3. 直播排序迭代V1: 特征工程+机器学习

业务初期选择了特征⼯程 + 机器学习 LR/GBDT,核心在于实时数据、实时交叉特征打点⽇志的建设,在特征⼯程上选取了经典推荐的user, item(live), user X item三个维度,这里相比于之前排权重,UV和转换率都有一个比较明显的提升。
4. 直播算法迭代V2:深度学习双序列模型 + 多目标学习 (Multi Seq MTL Model)
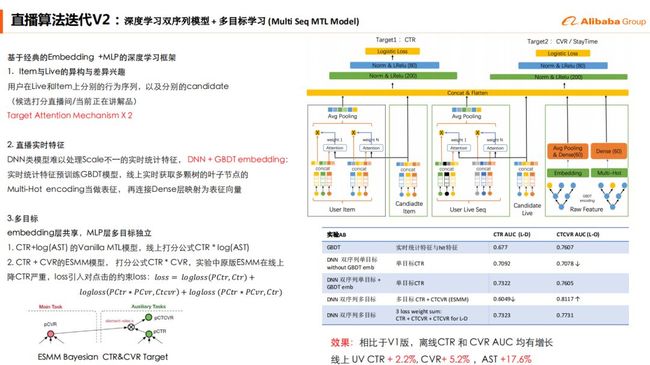
我们通过拆解用户行为轨迹当中,直播和商品作为两条不同的行为序列去进行分别的Attention,直播中每一个卖家都在贴一个正在介绍的商品,所以图中会有一个Candidate Item。
此外,由于DNN类模型难以处理Scale不一的实时统计特征,我们采取了DNN + GBDT embedding的模型结构,实时统计特征预训练GBDT模型,线上实时获取多颗叶子节点的Multi-Hot encoding当做表征,再连接Dense层映射为表征向量。相比于V1版本离线测试显示CTR 和 CVR AUC均有增长,线上测试UV CTR + 2.2%, CVR+ 5.2%,AST +17.6%
5. 直播算法迭代V3: Item到Live异构行为激活 ( HIN Attention )

动机:V2中⽤户行为都为同构的, 即item-> Item Att, Live-> Live Att,但对于⼤多数⽤户, 尤其是直播新⼈仅有Item⾏为的⽤户,最重要的是基于⽤户商品行为到直播的 Item-> Live 的异构推荐排序
V3:引⼊一路 Candidate Live到Item Seq的兴趣提取单元, 并在Live和Item表征中尝试了几种⽅法:
-
End2End Share embedding, 与V2模型中的其他部分live和item embedding共享, 共同训练
-
End2End not share embedding,为该路HIN Attention单独声明和训练embedding
-
HIN Pre-train, 基于Live 2Item的边关系, User 2 Item和User 2 Live的异构网络, 集合HIN Metapath2vec的方案预训练embedding, 预期可融⼊更多信息
效果:当前上线:End2End not share CVR +2.47%,停留时⻓AST + 3.92%
Future
这部分是我们预期在未来进行的工作
粗排网络
① 同时开播业务体量达到⼀定量级后, 基于双塔向量召回的粗排模型
多目标学习MTL
① MMOE结构,多个Expert Net建模不同目标,多业务场景已验证有效
② 多目标级联的Bayesian Net结构优化
异构网络HIN
① 引⼊更多关系(如粉丝关注) 的预训练向量,也可⽤于召回和商业化的商品分销
② 端到端的HIN2Rec建模, 如直接在模型中直播间本次讲解的多个商品去实时表征直播
内容理解
① 业界正在探索的⽅向, 还没有很成熟的落地