MapReduce实现账单统计
文章目录
- 一、项目简介
- 二、样例
-
- 1. 样例输入
- 2. 样例输出
- 二、具体实现
-
- 1. 引入maven依赖
- 2. 随机生成数据
- 3. Mapper类的编写
- 4. Reducer类的编写
- 5. Partitioner类的编写
- 6. Driver类的编写
- 7. 打包成jar文件并上传hadoop集群执行
- 三、项目地址
一、项目简介
本项目主要通过采用MapReduce的java-api,对自己随机生成的消费账单(如适用于统计某宝的购买记录等)进行合并和统计操作,使得可以按年或按月查询每个用户的账单。并根据本项目实际情况设置了2个分区和2个reduce。
二、样例
1. 样例输入
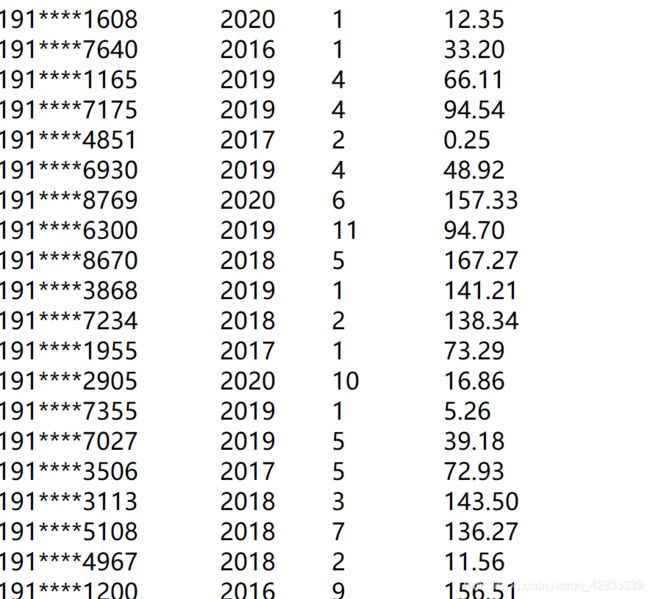
其中,第一列表示账号(关联到手机号),第二列表示产生这一消费的年份,第三列表示产生这一消费的月份,最后一列表示此次支出的具体金额。
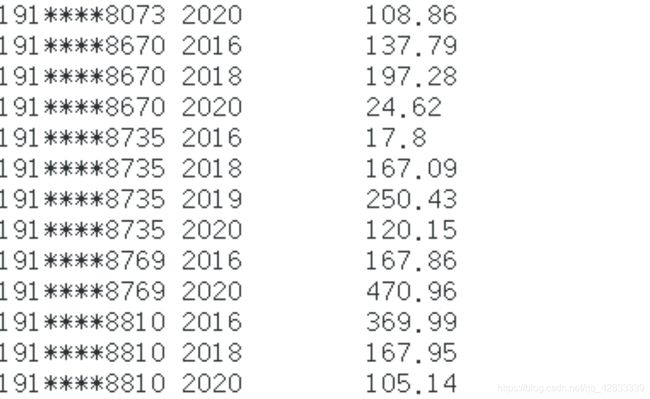
2. 样例输出
本样例是依据按年统计进行的输出,生成用户(关联手机号)的年度账单。
二、具体实现
1. 引入maven依赖
首先需要创建一个普通的maven项目,然后引入Hadoop和Junit的maven依赖。Junit主要用于单元测试(本来只有main程序可以运行的,导入Junit之后可以在任意函数前加@Test之后便可直接运行该程序),因此Junit可以根据具体需要和偏好决定是否导入。
maven依赖添加于pom.xml之中,具体配置如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.11version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.junit.jupitergroupId>
<artifactId>junit-jupiter-apiartifactId>
<version>RELEASEversion>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>compilescope>
dependency>
dependencies>
2. 随机生成数据
本项目由于是自己临时想到的一个点子,正好可供MapReduce的实操练习,因此也没有数据可以直接使用。因此,我便采取了用java代码生成模拟数据的思路,随机生成了100个用户的账单,他们的所有消费记录都是从2016-2020年的任意时间,且每个用户的消费记录条数也是随机生成。
/**
* @author Zhou.Y.M
* @create 2020/12/20 16:05
*/
public class createData {
static final String preNum="191****";
int []tailNums=new int[4];
String []Nums=new String[100];
@Before
public void createNums()
{
for(int i=0;i<Nums.length;i++)
{
Nums[i]=preNum;
for(int j=0;j<tailNums.length;j++)
{
tailNums[j]=(int)(Math.random()*10);
Nums[i]+=tailNums[j];
}
//System.out.println(Nums[i]);
}
}
@Test
public void createBills() throws IOException {
OutputStream out= new BufferedOutputStream(new FileOutputStream("input\input.txt"));
int k=(int) (Math.random()* Nums.length);
DecimalFormat df=new DecimalFormat("0.00");
for(int j=0;j<5;j++)
{
for(int i=0;i< Nums.length;i++)
{
if(i==k)
break;
out.write((Nums[i]+"\t"+(int)(2016+Math.random()*5)+"\t"+(int)(Math.random()*12+1)+"\t"+df.format(Math.random()*200)+"\n").getBytes());
}
}
out.flush();
out.close();
}
}
3. Mapper类的编写
1)统计年账单的Mapper类
public class doMapper_year extends Mapper<LongWritable, Text, Text, DoubleWritable> {
//public static final IntWritable one = new IntWritable(1);//这里的IntWritable相当于Int类型
//public static Text word = new Text();//Text相当于String类型
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String []line=value.toString().split("\t");
String phoneAndYear=line[0]+" "+line[1];
double bill=Double.parseDouble(line[line.length-1]);
System.out.println("test");
System.out.println("hgweiohg");
//将word存到容器中,记一个数
context.write(new Text(phoneAndYear), new DoubleWritable(bill));
}
}
2)统计月账单的Mapper类
public class doMapper_month extends Mapper<LongWritable, Text, Text, DoubleWritable> {
//public static final IntWritable one = new IntWritable(1);//这里的IntWritable相当于Int类型
//public static Text word = new Text();//Text相当于String类型
// map参数,将处理后的数据写入context并传给reduce
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException, IOException {
//StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分
String[] line = value.toString().split("\t");
String phoneAndMonth = line[0] + " " +line[1]+" "+ line[2];
double bill = Double.parseDouble(line[line.length - 1]);
//将word存到容器中,记一个数
context.write(new Text(phoneAndMonth), new DoubleWritable(bill));
}
}
4. Reducer类的编写
由于无论是统计年账单还是月账单,所用到的Reducer的处理逻辑都是一样的,因此我们只需编写一个Reducer类即可。
public class doReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void reduce(Text key,Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
double sum=0;
for(DoubleWritable value:values)
{
sum+=Double.parseDouble(value.toString());
}
DecimalFormat df=new DecimalFormat("0.00");
sum=Double.parseDouble(df.format(sum));
System.out.println(key+" "+sum);
context.write(key,new DoubleWritable(sum));
}
}
5. Partitioner类的编写
我们按照尾号的大小,将数据分成了两个区,由不同的Reducer进行处理,并输出到不同的文件之中。
public class myPartition extends Partitioner<Text, DoubleWritable> {
@Override
public int getPartition(Text text, DoubleWritable intWritable, int num) {
if(Integer.parseInt(text.toString())<50)
return 0%num;
else
return 1%num;
// return 0;
}
}
6. Driver类的编写
public class Driver {
public static void main(String[] args) throws InterruptedException, IOException, URISyntaxException, ClassNotFoundException {
Configuration conf = new Configuration();
//System.setProperty("HADOOP_USER_NAME", "hadoop");
//conf.set("fs.defaultFS","hdfs://centos01:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(Driver.class);
job.setMapperClass(doMapper_year.class);
job.setReducerClass(doReducer.class);
//设置自定义分区类
job.setPartitionerClass(myPartition.class);
// 设置reduce个数
job.setNumReduceTasks(2);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(job, new Path("/test/MapReduce/input"));
FileOutputFormat.setOutputPath(job, new Path("/test/MapReduce/output"));
System.exit(job.waitForCompletion(true)?0:-1);
}
}
7. 打包成jar文件并上传hadoop集群执行
首先在maven的pom.xml中添加如下插件:
<plugins>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<appendAssemblyId>falseappendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>BillComputing.statistics.DrivermainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>assemblygoal>
goals>
execution>
executions>
plugin>
plugins>
然后依次点击maven中的compile和package(如果是用的idea编辑器,则默认在编辑器的右侧),生成的jar包存放在target文件夹中。然后上传到hadoop集群上,最后用以下代码在集群上运行jar包。
hadoop fs jar xxxx.jar(jar包存放的路径) xxx(类路径名)
需要注意的是,用此种方式运行jar包时,jar包不是放在hadoop集群的,而是在linux上,因此路径也是linux文件系统中的路径。而类路径,是指你要执行的包含main函数的主类,该类名一定要写全名,如org.example.BillComputing.Driver。
三、项目地址
最后附上本项目的github地址,供大家参考。Github项目地址
大家如果觉得我写得不错,也可以关注一波,您的关注就是对我最大的支持。另外我之前也写过一篇同系列的关于HDFS的实战文章以及关于Hive的原理介绍文章,也可供大家参考。
仅使用HDFS的Java-API进行WordCount词频统计工作
Hive学习笔记(1)——Hive原理初探