【DataWhale数据分析】Task1学习报告
DataWhale数据分析|Task1
任务介绍:
任务要求:
统计2019年全年计算机各个方向论文数量
任务流程:
- 下载kaggle数据集
- 安装所需package:seaborn(数据可视化),BeautifulSoup4(爬虫相关,用于爬取数据),requests(网络通信),json(json格式数据读取),pandas(大数据分析),matploblib(绘图)
- 通过json包读取数据,并用pandas包转为dataframe格式准备进一步分析
- 按照时间特征提取2019年的数据
- 通过对html的各级tags进行切分来获取计算机相关的所有类别
- 通过一级学科标签对2019年的论文进行饼状图绘制
- 通过二级种类标签对计算机的论文进行分析
任务详解
1. json包读取数据
with open("arxiv-metadata-oai-2019.json", 'r') as f:
for idx, line in enumerate(f):
json.loads(line)
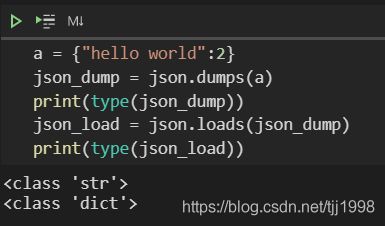
json.dumps()和json.loads()是json格式处理函数
- json.dumps()函数是将字典转化为json格式数据(字符串)
- json.loads()函数是将json格式数据(字符串)转换为字典
2. pandas包处理数据
1) 转换为dataframe格式
data.append(json.loads(line))
pd.DataFrame(data)
将字典(即表格的一行)的list数据转换为dataframe格式便于进一步处理
- DataFrame主要根据dict进行创建,以及读取csv或txt文件来创建。
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame = pd.DataFrame(data)
- DataFrame的行索引是index,列索引是columns,可以在创建DataFrame时指定索引的值:
pd.DataFrame(data,index=['one','two','three','four','five'],columns=['year','state','pop','debt']) - 使用嵌套字典也可以创建DataFrame,此时外层字典的键作为列,内层键则作为索引。
2) pandas基本操作
data.head()显示数据前五行
可以指定data["id"],head(),输出该行的数据data.describe()显示数据的统计信息,一般返回数据的数量,方差,标准差,最大值,最小值
语法为:DataFrame.describe(percentiles=None,include=None,exclude=None,datetime_is_numeric=False)
其中percentiles可指定返回的百分位数值,常见的中位数(50%);include指定需要统计的列,exclude则为指定不需要统计的列;datetime_is_numeric则是判断是否将日期格式当做数值数据处理。
示例:
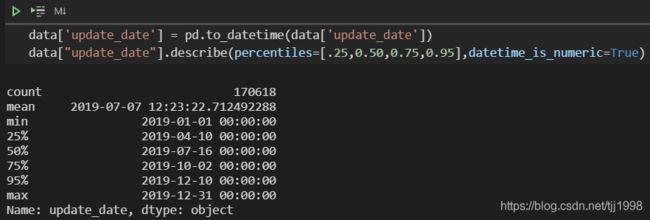
通过使用to_datetime函数将data["update_date"]转为日期格式;通过设定datetime_is_numeric=True来将日期格式作为数值格式处理;指定percentiles=[.25,0.50,0.75,0.95]输出该列的0.25、0.50、0.75、0.95分位数。data = data[data["year"] >= 2019]数据筛选
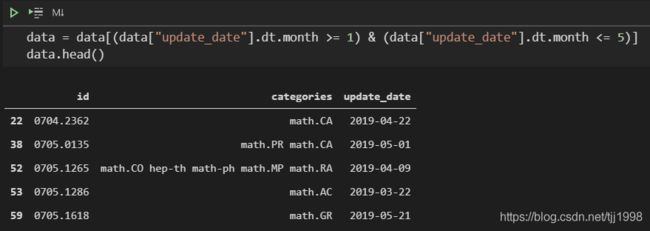
可以指定需要筛选的数据,支持的符号有‘>’、‘<’、‘==’、‘<=’、‘>=’等,如果需要指定多个筛选条件,需要将每个条件用小括号()包围然后用‘&’(且)和‘|’(或)来连接。示例:
DataFrame常用方法:
| 函数 | 功能 |
|---|---|
| df.count() | 非空元素计算 |
| df.min() | 最小值 |
| df.max() | 最大值 |
| df.idxmin() | 最小值的位置,类似于R中的which.min函数 |
| df.idxmax() | 最大值的位置,类似于R中的which.max函数 |
| df.quantile(0.1) | 10%分位数 |
| df.sum() | 求和 |
| df.mean() | 均值 |
| df.median() | 中位数 |
| df.mode() | 众数 |
| df.var() | 方差 |
| df.std() | 标准差 |
| df.mad() | 平均绝对偏差 |
| df.skew() | 偏度 |
| df.kurt() | 峰度 |
| df.describe() | 一次性输出多个描述性统计指标 |
3.获取计算机论文类别
1) 数据爬取
#爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy').text #获取网页的文本数据
soup = BeautifulSoup(website_url,'html.parser') #爬取数据
root = soup.find('div',{
'id':'category_taxonomy_list'}) #找出 BeautifulSoup 对应的标签入口
tags = root.find_all(["h2","h3","h4","p"], recursive=True) #读取 tags
通过requests包获取https://arxiv.org/category_taxonomy网页的文本数据,BeautifulSoup对网页文本数据进行解析。
函数说明:
find只返回第一个匹配到的对象
语法:find(name, attrs, recursive, text, **wargs)
| 参数名 | 作用 |
|---|---|
| name | 查找标签(str类型) |
| attrs | 查找标签的属性(dict类型) |
| recursive | 递归查找 |
| text | 查找文本(str类型) |
| **wargs | 基于定义的函数进行查找 |
find_all返回所有匹配到的对象
语法:find_all(name, attrs, recursive, text, limit, **kwargs)
| 参数名 | 作用 |
|---|---|
| name | 查找标签(str类型) |
| attrs | 查找标签的属性(dict类型) |
| recursive | 递归查找 |
| text | 查找文本(str类型) |
| limit | 限制得到的结果的数目 |
| **wargs | 基于定义的函数进行查找 |
2) 数据切分
#初始化 str 和 list 变量
level_1_name = ""
level_2_name = ""
level_2_code = ""
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
#进行
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)",r"\2",raw) #正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)",r"\1",raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)",r"\1",raw)
level_3_name = re.sub(r"(.*) \((.*)\)",r"\2",raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
#根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
#按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(["group_name","archive_name"])
re.sub(r"(.*) \((.*)\)",r"\1",raw) 利用正则表达式进行字符串抽取
语法:re.sub(pattern, repl, string, count=0, flags=0)
| 参数名 | 作用 |
|---|---|
| pattern | 表示正则表达式模式(必须) |
| repl | 表示用于替换的内容(必须) |
| string | 表示输入的字符串(必须) |
| count | 设定处理其中一部分需要替换的内容(可选) |
| flags | 可以修改正则表达式的一些运行方式(可选) |
3) 数据分组
通过"group_name" 进行分组,在组内使用 “archive_name” 进行排序。
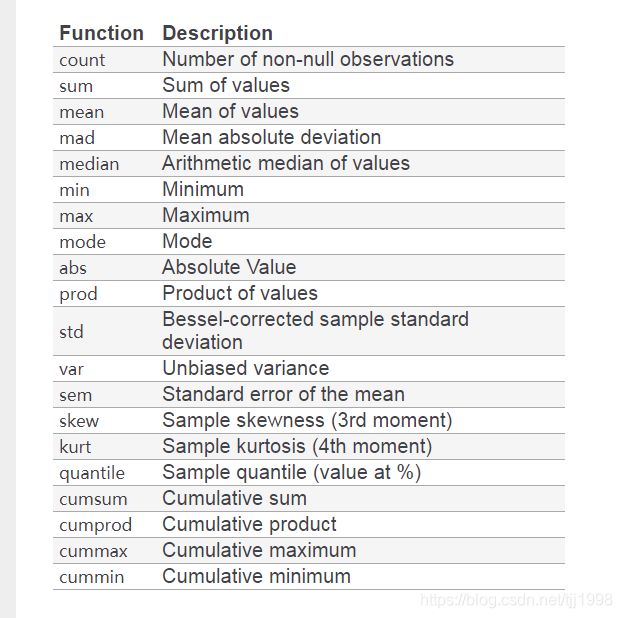
很多函数可以在groupby之后去处理:
4. 绘制不同方向论文占比饼状图
1) 准备表格
_df = data.merge(df_taxonomy, on="categories", how="left").drop_duplicates(["id","group_name"]).groupby("group_name") \
.agg({
"id":"count"}).sort_values(by="id",ascending=False).reset_index()
merge将data表和df_taxonomy表基于‘categories’列进行合并
语法merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
| 参数 | 描述 |
|---|---|
| how | 数据融合的方法,从在不重合的键,方式(inner、outer、left、right) |
| on | 用来对齐的列名,一定要保证左表和右表存在相同的列名。 |
| left_on | 左表对齐的列,可以是列名。也可以是DataFrame同长度的arrays |
| right_on | 右表对齐的列,可以是列名。 |
| left_index | 将左表的index用作连接键 |
| right_index | 将右表的index用作连接键 |
| suffixes | 左右对象中存在重名列,结果区分的方式,后缀名。 |
| copy | 默认:True。将数据复制到数据结构中,设置为False提高性能。 |
drop_duplicates删除重复行,在本例中为如果’id’和’group_name’都相同则认为重复。agg聚合函数, 其操作包括max、min、std、sum、count。
2) 绘制饼状图
fig = plt.figure(figsize=(15,12))
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout()
plt.show()
def pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=None, radius=None, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, hold=None, data=None)
x :(每一块)的比例,如果sum(x) > 1会使用sum(x)归一化;
labels :(每一块)饼图外侧显示的说明文字;
explode :(每一块)离开中心距离;
startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起;
shadow :在饼图下面画一个阴影。默认值:False,即不画阴影;
labeldistance :label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧;
autopct :控制饼图内百分比设置,可以使用format字符串或者format function; '%1.1f'指小数点前后位数(没有用空格补齐);
pctdistance :类似于labeldistance,指定autopct的位置刻度,默认值为0.6;
radius :控制饼图半径,默认值为1;counterclock :指定指针方向;布尔值,可选参数,默认为:True,即逆时针。将值改为False即可改为顺时针。
wedgeprops :字典类型,可选参数,默认值:None。参数字典传递给wedge对象用来画一个饼图。例如:wedgeprops={'linewidth':3}设置wedge线宽为3。
textprops :设置标签(labels)和比例文字的格式;字典类型,可选参数,默认值为:None。传递给text对象的字典参数。
center :浮点类型的列表,可选参数,默认值:(0,0)。图标中心位置。
frame :布尔类型,可选参数,默认值:False。如果是true,绘制带有表的轴框架。
rotatelabels :布尔类型,可选参数,默认为:False。如果为True,旋转每个label到指定的角度。
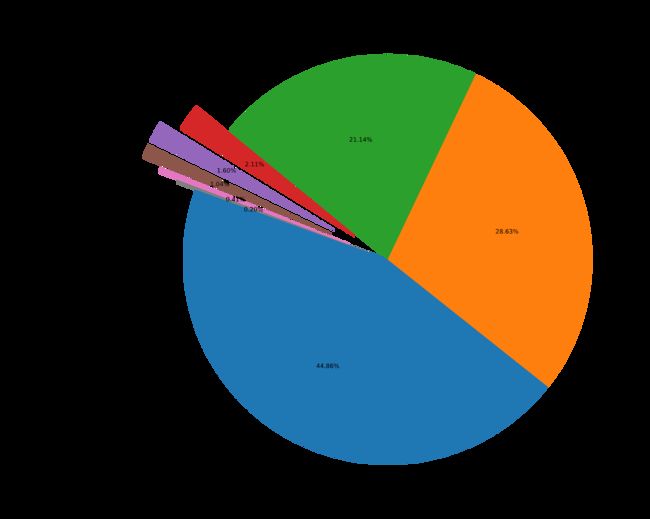
3. 计算机论文分析
group_name="Computer Science"
cats = data.merge(df_taxonomy, on="categories").query("group_name == @group_name")
cats.groupby(["year","category_name"]).count().reset_index().pivot(index="category_name", columns="year",values="id")
- 将data表通过‘categories’列与df_taxonomy表合并,查询group_name为"Computer Science"的行。
- 将得到的新表通过年份分组,组内按照category_name排序,count用于计数,reset_index函数用于还原索引,pivot()函数指定相应的column分别作为行、列索引以及值。
学习过程中遇到的问题及解决方案:
问题1.出现问题:FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
报错信息如下:
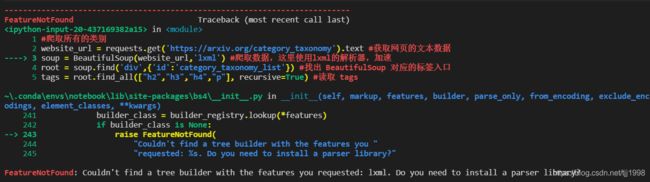
出现问题位置:
soup = BeautifulSoup(website_url,'lxml') #爬取数据,这里使用lxml的解析器,加速
出现问题原因:
lxml安装的最新版本,新版本语法支持发生了改变
解决方案:
- 不改变版本,将’lxml’替换为’html.parser’
- 卸载新版本,安装老版本
pip uninstall lxml
pip install lxml==3.7.0
参考文献:
[1]. Pandas-DataFrame基础知识点总结
[2]. json.dumps()和json.loads()
[3]. python中groupby函数详解(非常容易懂)
[4]. BeautifulSoup中的find,find_all
[5]. python正则表达式 re.sub的各个参数的详细解释
[6]. DataFrame 数据合并(merge,join,concat)
[7]. DataFrame中的count()函数,以及常用的统计方法
[8]. bs4 FeatureNotFound: Couldn’t find a tree builder with the features you requested: lxml. Do you need to install a parser library?