使用Scrapy爬虫框架爬取一个页面
参考资料:Python网络爬虫与信息提取(北京理工大学慕课)
这个就是我们准备爬取的页面:

使用Scrapy库,首先需要产生一个Scrapy爬虫框架,它分为如下一些步骤:
1.建立一个Scrapy爬虫工程
首先我们打开Pycharm,新建一个Project,这里我新建了一个叫demo的Project:
然后我们打开Pycharm的终端,输入scrapy startproject python123demo:

这样,我们就建立了一个Scrapy爬虫工程:

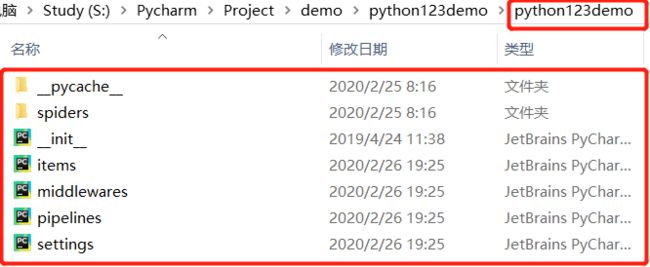

那么生成的这些东西是什么呢?

部署的概念是指:将建的爬虫放在特定的服务器上,并且在服务器配置好相关的操作接口。
对于本机使用的爬虫来讲,我们不需要改变部署的配置文件
如果用户希望扩展middleware的功能,那么需要把这些功能写到第二个python123demo/文件中。
如果希望优化爬虫功能,需要修改settings.py文件中的对应的配置项。
spiders/目录下存放的是python123demo这个工程中所建立的爬虫:

2.在工程中产生一个Scrapy爬虫
在工程中,产生一个爬虫只需要执行一条命令就可以,但这个命令需要约定用户给出爬虫的名字以及所爬取的网站。
我们打开Pycharm,在终端输入scrapy genspider demo python123.io:

这条命令的作用是生成一个名称为demo的spider(也就是爬虫),然后我们会发现在spiders目录下增加了一个代码叫demo.py:

这里边我们用命令生成了一个文件,看似很神秘,但这条命令的作用仅限于生成demo.py。
如果我们不是用这条命令来生成demo.py,事实上我们也可以手工来生成这个文件。
打开demo.py:

我们看到它是一个面向对象,方式编写的一个类,这个类叫DemoSpider。
由于爬虫的名字叫demo,所以这个类名也叫DemoSpider。
名字叫什么并没有什么关系,但是这个类必须是继承于scrapy.Spider这个类的子类。
name = "demo" 说明当前的爬虫的名字叫demo。
allowed_domains 就是最开始用户提交给命令行的域名,指的是这个爬虫在爬取网站的时候,它只能爬取这个域名以下的相关链接。(它是一个可选参数)
start_urls 是一个非常重要的变量,顾名思义,事实上它后面以列表形式包含的一个或多个url,就是scrapy框架所要爬取页面的初始页面。
def parse() 是一个解析页面的、空的方法,包含在这个类中,用于处理响应,解析内容形成字典,发现新的URL爬取请求。
3.配置产生的spider爬虫
具体来说,我们需要去修改demo.py文件,使它能够按照我们的要求去访问我们希望访问的那个链接,并且对相关的链接内容进行爬取。
这里我们对链接的解析部分定义的功能是:将返回的html页面存成文件。
具体来说,我们把demo.py文件修改如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response): # resonse相当于从网络中返回内容所存储的或对应的对象
fname = response.url.split('/')[-1] # 定义文件名字,把response中的内容写到一个html文件中
with open (fname, 'wb') as f: # 从响应的url中提取文件名字作为保存为本地的文件名,然后将返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % fname) # self.log是运行日志,不是必要的
# 这样,我们的demo.py文件就能够爬取一个网页,并且能够将网页的内容保存为一个html文件
4.运行爬虫,获取网页
在pycharm终端输入scrapy crawl demo
然后就能爬取到这个页面了:
这里我们回顾一下demo.py代码:

start_urls变量所表示的就是爬虫启动时,最开始的url链接。
parse方法表示的是对返回的页面进行解析,并且进行操作的相关步骤。
事实上这行代码是scrapy框架提供的一个简化版代码。
对应的完整版本:
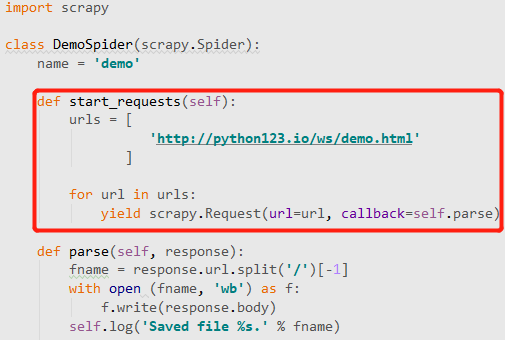
可以看到多出了一个start_requests方法。
那么两个版本的区别是什么?
由命令生成的简化版demo.py文件,它通过start_urls这个列表来给出初始的url链接。
而srapy框架支持的另外一种等价的方式,是使用一个叫start_requests的方法,这个方法中,首先定义了一个urls列表,并且对列表中的每一个列表通过yield scrapy.Requests向Engine提出了url访问请求。