Java学习札记2013
Java学习札记2013
姓名:刘显安
2013年3月11日
第一个月:
20130311:
内存溢出的三种形式:
-
堆溢出:
| /** * @author LXA * 堆溢出 */ public class Heap { public static void main(String[] args) { ArrayList list=new ArrayList(); while(true) { list.add(new Heap()); } } } |
报错:
java.lang.OutOfMemoryError: Java heap space
-
栈溢出:
| /** * @author LXA * 栈溢出 */ public class Stack { public static void main(String[] args) { new Stack().test(); } public void test() { test(); } } |
报错:
java.lang.StackOverflowError
-
方法区溢出
20130312:
集合
线程
数据库
20130313:
数据库连接池:
反射:
| package C_20130313_反射; import java.lang.reflect.Method; class User { private String name; public User(){} public User(String name) { this.name=name; } public void say()//无参的方法 { System.out.println("大家好,我叫"+name+"!"); } public void say(String str)//有参的方法 { System.out.println("大家好,我叫"+name+"!"+str+",我是有参的方法!"); } } /** * @author LXA * 反射最简单的例子 */ public class反射 { public static void main(String[] args) throws Exception { Class c=Class.forName("C_20130313_反射.User");//通过反射找到对应的类 Method m1=c.getMethod("say");//找到名字叫做say、且无参的方法 Method m2=c.getMethod("say",String.class);//找到名字叫做say、且有一个String类型参数的方法 m1.invoke(c.newInstance());//注意newInstance()调用的是无参的构造方法!!! m2.invoke(new User("刘显安"),"哈哈");//通过有参的构造方法实例化一个对象 } } |
静态代理
动态代理:
文件IO:
Socket编程:
20130314:
模拟Tomcat:
20130318(Struts)
20130319(Hibernate)
缓存策略
保存策略
加载策略
单向关联
双向关联
20130320(Spring)
最近一直在搞正则表达式
20130322(周五,上课最后一天):
23号开始做项目了。
今天碰到的奇葩事情:
| public static void main(String[] args) throws Exception { File file=new File("F:\\1.txt"); System.out.println(file.exists()); FileReader fr=new FileReader(new File("F:\\1.txt")); } |
输出结果如下:

但是如果代码改为如下:
| public static void main(String[] args) throws Exception { File file=new File("F:\\1.txt");发生 System.out.println(file.exists()); FileReader fr=new FileReader(file); } |
就不会有任何错误,真是奇葩!!!谁能解释一下不?
20130325:
敲代码第一天:
发现Eclipse一个很不好的地方:运行时不会自动给你保存,而MyEclipse会给你自动保存!
20130326:
今天改写jstl。
关于Java的值传递与引用传递:
其实这个问题很好理解:
Java参数,不管是原始类型还是引用类型,传递的都是副本,也就是把参数复制一份再传过去,但是:
如果参数类型是原始类型,那么直接把这个参数的值复制一份传过去,所以如果在函数中改变了副本的值,原始的值是不会改变的。
如果参数类型是引用类型,那么传过来的就是这个参数的地址的副本,如果在函数中没有改变这个副本的地址,而是改变了地址所指向的东西,那么在函数内的改变肯定会影响到传入的参数。但是如果在函数中改变了副本的地址(比如new一个,那么副本就指向了一个新的地址),此时在函数里面做的所有修改都针对是对那个新地址所指向的对象,所以原始的值不会改变。
多说无益,看下面最简单的例子:
| class Student { int age=20;//学生的初始年龄设置为20 } public class T { public static void main(String[] args) { Student stu=new Student(); System.out.println("学生初始年龄:"+stu.age); update(stu); //将stu作为参数传过去 System.out.println("修改后的学生年龄:"+stu.age); } public static void update(Student stu) { stu.age=21; } } |
输出结果:
| 学生初始年龄:20 修改后的学生年龄:21 |
如果将update方法改为如下:
| public static void update(Student stu) { stu=new Student();//此时stu指向的是一个新地址 stu.age=21; } |
那么输出结果将变成:
| 学生初始年龄:20 修改后的学生年龄:20 |
注意:虽然上面说如果是引用类型会改变原始值,但是对于final的对象就不灵验了,比如String就是final的,因为final类是不可改变的,所以当改变了String的值时其实又new了一个String,自然原始值是不会跟着改变的(Integer等包装类都是final的)。
其实这就解释了为什么用String和StringBuffer做参数结果不一样。
Hibernate注解的使用:
注解和xml配置差不多,但能够少一半的文件,并且由于一般实体类的大部分属性都不需要配置什么,所以用配置文件会感觉有很大的冗余,这时注解就会大有用处!
-
导包:
在MyEclipse9中,一般导入以下2个库:核心库和注解库
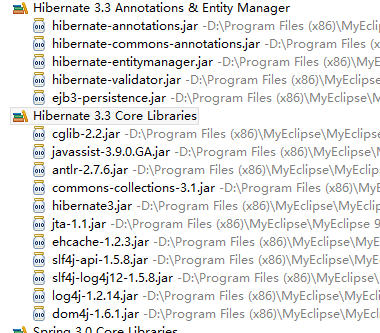
-
最简单的实体类(注意注解使用的都是 javax.persistence包下面的,别导错包了!):
| package entity;
import javax.persistence.Basic; import javax.persistence.Entity; import javax.persistence.Id;
@Entity public class Emp { @Id private int emp_id;//员工ID @Basic private String emp_name;//员工姓名 //省略get和set } |
-
hibernate.cfg.xml文件:
本人是在项目根目录下新建一个config"源文件夹",然后将所有配置文件都放在这个文件夹下(注意普通文件夹必须先构建路径使之成为源文件夹),然后使用默认配置文件名称hibernate默认就能够找到它。
注意:下面2行黄色标注部分先不用看!!!
| <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name="show_sql">true</property> <property name="format_sql">true</property> <property name="connection.driver_class">oracle.jdbc.driver.OracleDriver</property> <property name="connection.url"> jdbc:oracle:thin:@localhost:1521:xe</property> <property name="connection.username">lxa</property> <property name="connection.password">123</property> <property name="dialect">org.hibernate.dialect.Oracle10gDialect</property> <property name="hbm2ddl.auto">create</property> <mapping class="entity.Emp"/> <mapping resource="entity/Emp.hbm.xml"/> </session-factory> </hibernate-configuration> |
-
Hibernate工具类的改写(部分代码)
| public class HiberUtil { private static SessionFactory sessionFactory;//全局的会话工厂 static { sessionFactory=new AnnotationConfiguration() .configure() .addAnnotatedClass(Dept.class) //有多少个实体类就add多少次 .addAnnotatedClass(Emp.class) .buildSessionFactory(); } /** * 获取会话 */ public static Session getSession() { return sessionFactory.openSession(); } } |
对于已经注解的实体类,必须还要注册,注册有2种方法:
1、也就是最上面配置文件里面的写法(也就是说除了在实体类的上面加一个@Entity之外,还要在配置文件里map一下):
| <mapping class="entity.Emp"/> |
2、如果不喜欢在配置文件里写map,还可以在代码里注册,其实上面已经给出代码了,就是HiberUtil.java中的addAnnotatedClass()
补充:
hbm映射文件和注解可以混用。
可以发现,如果一个系统里面的实体类很多,那么一个个注册就很麻烦了,为此,本人写了一个简单的工具类来解决这个问题(其实就是类似Spring的包扫描,Spring的注解类之所以不需要注册,是因为它可以在配置文件里指定要扫描的包,不知道为什么hibernate不做这样一个功能!)
使用方法很简单:
| static { //以下是Hibernate3注册的方法 AnnotationConfiguration conf =new AnnotationConfiguration().configure(); PackageHelper.addPackage(conf, "entity");//指定要扫描的包名叫做entity sessionFactory = conf.buildSessionFactory(); } |
PackageHelper.java:
| /** * @author LXA * 获取某个包下面所有类的工具类 * 2013/03/26 */ public class PackageHelper { /** * 为Hibernate注解配置对象添加注解类 * @param conf 配置对象 * @param packageName 要扫描的包名 */ public static void addPackage(AnnotationConfiguration conf,String packageName) { Set<Class<?>> cs=findClass(packageName); for(Class<?> c:cs) conf.addAnnotatedClass(c); System.out.println("注册所有实体类完毕!"); } /** * 找到某一个包下面所有的类 * @param packageName * @return */ public static Set<Class<?>> findClass(String packageName) { Set<Class<?>> cs=new LinkedHashSet<Class<?>>(); try { //获取包名对应的真实物理地址 URL url = Thread.currentThread().getContextClassLoader().getResource(packageName.replace('.', '/')); String packagePath = URLDecoder.decode(url.getFile(), "utf-8");//中文路径会存在乱码问题 findClass(packageName, packagePath,cs); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return cs; }
/** * 递归的一个私有方法,供findClass(String packageName)调用 * @param packageName * @param packagePath * @param cs */ private static void findClass(String packageName, String packagePath,Set<Class<?>> cs) { File dir = new File(packagePath);// 获取此包的目录建立一个File if (!dir.exists() || !dir.isDirectory())// 如果不存在或者也不是目录就直接返回 return; File[] dirfiles = dir.listFiles();// 如果存在就获取包下的所有文件包括目录 for (File file : dirfiles)// 循环所有文件 { if (file.isDirectory())// 如果是目录则继续扫描 findClass(packageName + "." + file.getName(),file.getAbsolutePath(),cs); else { if (file.getName().endsWith(".class"))// 如果是java类文件去掉后面的.class 只留下类名 { String className = file.getName().replaceAll(".class$", ""); try { // 这里用forName有一些不好,会触发static方法,没有使用classLoader的load干净 // Class c=Class.forName(packageName + '.' + className); Class c = Thread.currentThread().getContextClassLoader() .loadClass(packageName + '.' + className); cs.add(c); } catch (ClassNotFoundException e) { e.printStackTrace(); } } } } } } |
20130327:
三种常见数据库连接方式:
| MySQL: jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/test jdbc.username=root jdbc.password=admin
Oracle: jdbc.driver=oracle.jdbc.driver.OracleDriver jdbc.url=jdbc:oracle:thin:@127.0.0.1:1521:orcl jdbc.username=scott jdbc.password=tiger
MS SQL Server: jdbc.driver= com.microsoft.jdbc.sqlserver.SQLServerDriver jdbc.url= jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=mssql jdbc.username=sa jdbc.password=sa |
Hibernate注解进阶:
-
Hibernate的注解本着尽量采用默认设置的原则来减少注解的代码,具体体现请往下看。
-
实体bean中所有的非static的属性都可以被持久化, 除非你将其注解为@Transient(相当于不让这个属性映射到数据库中去)
-
所有没有定义注解的属性等价于在其上面添加了@Basic注解. 通过 @Basic注解可以声明属性的获取策略(fetch strategy):
-
注解可以写在属性上,也可以写在方法上,但应尽量避免2种方法混用:要么都写在属性上,要么都写在get方法上。
-
你可以在实体bean中使用@Version注解,通过这种方式可添加对乐观锁定的支持,version列可以是numeric类型(推荐方式)也可以是timestamp类型.
如果想对一个列的属性进行具体设置:
| @Column(name="dept_name_222",length=100,nullable=false) private String dept_name;//部门名称 |
无注解之属性的默认值
如果某属性没有注解,该属性将遵守下面的规则:
|
主键生成策略:
使用@Id注解可以将实体bean中的某个属性定义为标识符(identifier). 该属性的值可以通过应用自身进行设置, 也可以通过Hiberante生成(推荐). 使用 @GeneratedValue注解可以定义该标识符的生成策略:
| AUTO |
自动,推荐使用,可以是identity column类型,或者sequence类型或者table类型,取决于不同的底层数据库. |
| TABLE |
使用表保存id值 |
| IDENTITY |
identity column,数据库自带的主键自增策略,如SQL Server和MySQL |
| SEQUENCE |
序列,适用于Oracle |
主键一般定义如下:
| @Id @GeneratedValue(strategy=GenerationType.AUTO) private int emp_id;//员工ID |
使用注解实现关联映射:
多对一:
员工表:
| @Entity public class Emp { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int emp_id;//员工ID private String emp_name;//员工姓名 @ManyToOne private Dept deptaa;//对应的部门 public Emp(){} public Emp(String emp_name) { this.emp_name=emp_name; } //省略get和set } |
部门表:
| @Entity public class Dept { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int dept_id;//部门ID private String dept_name;//部门名称 @Transient //这个表示emps只是普通字段,不会关联到数据库,相当于"注释" private Set<Emp> emps;//员工集合 public Dept(){} public Dept(String dept_name) { this.dept_name=dept_name; } //省略get和set } |
生成的表结构如下:
Dept:
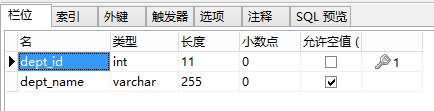
Emp:

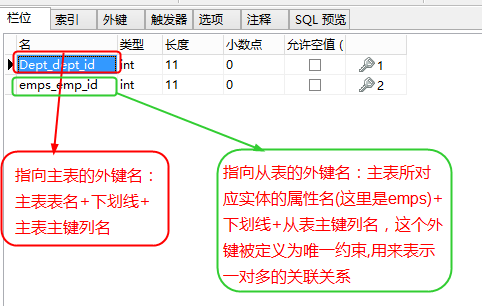
生成的外键:

如果想自己指定emp中外键的列名:
| @ManyToOne @JoinColumn(name="fsdfs") private Dept deptaa;//对应的部门 |
一对多:
Dept.java:
| @Entity public class Dept { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int dept_id;//部门ID private String dept_name;//部门名称 @OneToMany private Set<Emp> emps;//员工集合 public Dept(){} public Dept(String dept_name) { this.dept_name=dept_name; } //省略get和set } |
Emp.java(部分代码):
| @Transient //相当于把deptaa给注释掉 private Dept deptaa;//对应的部门 |
此时会生成3张表:
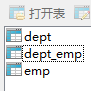
另外会生成一个中间的"联结表",表名默认是:主表表名+下划线+从表表名,所以这里是:dept_emp
关于这个中间连接表,Hibernate官方解释如下:
| 通过在被拥有的实体端(owned entity)增加一个外键列来实现一对多单向关联是很少见的,也是不推荐的. 我们强烈建议通过一个联接表(join table)来实现这种关联. 通过联接表处理单向一对多关联是首选方式.这种关联通过@JoinTable注解来进行描述(这个JoinTable不重要)。 |
当然,如果你不喜欢多一个中间表,可以这样(别的地方都不用改,只需改下面):
| @OneToMany @JoinColumn(name="empp_id")//指定从表中外键的名字,此时不会生成中间表 private Set<Emp> emps;//员工集合 |
20130328
HTTP错误代码表:
所有 HTTP 状态代码及其定义。
代码 指示
2xx 成功
200 正常;请求已完成。
201 正常;紧接 POST 命令。
202 正常;已接受用于处理,但处理尚未完成。
203 正常;部分信息 — 返回的信息只是一部分。
204 正常;无响应 — 已接收请求,但不存在要回送的信息。
3xx 重定向
301 已移动 — 请求的数据具有新的位置且更改是永久的。
302 已找到 — 请求的数据临时具有不同 URI。
303 请参阅其它 — 可在另一 URI 下找到对请求的响应,且应使用 GET 方法检索此响应。
304 未修改 — 未按预期修改文档。
305 使用代理 — 必须通过位置字段中提供的代理来访问请求的资源。
306 未使用 — 不再使用;保留此代码以便将来使用。
4xx 客户机中出现的错误
400 错误请求 — 请求中有语法问题,或不能满足请求。
401 未授权 — 未授权客户机访问数据。
402 需要付款 — 表示计费系统已有效。
403 禁止 — 即使有授权也不需要访问。
404 找不到 — 服务器找不到给定的资源;文档不存在。
407 代理认证请求 — 客户机首先必须使用代理认证自身。
415 介质类型不受支持 — 服务器拒绝服务请求,因为不支持请求实体的格式。
5xx 服务器中出现的错误
500 内部错误 — 因为意外情况,服务器不能完成请求。
501 未执行 — 服务器不支持请求的工具。
502 错误网关 — 服务器接收到来自上游服务器的无效响应。
503 无法获得服务 — 由于临时过载或维护,服务器无法处理请求。
-----------------------------------------------------------------------------------------------------------------------
HTTP 400 - 请求无效
HTTP 401.1 - 未授权:登录失败
HTTP 401.2 - 未授权:服务器配置问题导致登录失败
HTTP 401.3 - ACL 禁止访问资源
HTTP 401.4 - 未授权:授权被筛选器拒绝
HTTP 401.5 - 未授权:ISAPI 或 CGI 授权失败
HTTP 403 - 禁止访问
HTTP 403 - 对 Internet 服务管理器 (HTML) 的访问仅限于 Localhost
HTTP 403.1 禁止访问:禁止可执行访问
HTTP 403.2 - 禁止访问:禁止读访问
HTTP 403.3 - 禁止访问:禁止写访问
HTTP 403.4 - 禁止访问:要求 SSL
HTTP 403.5 - 禁止访问:要求 SSL 128
HTTP 403.6 - 禁止访问:IP 地址被拒绝
HTTP 403.7 - 禁止访问:要求客户证书
HTTP 403.8 - 禁止访问:禁止站点访问
HTTP 403.9 - 禁止访问:连接的用户过多
HTTP 403.10 - 禁止访问:配置无效
HTTP 403.11 - 禁止访问:密码更改
HTTP 403.12 - 禁止访问:映射器拒绝访问
HTTP 403.13 - 禁止访问:客户证书已被吊销
HTTP 403.15 - 禁止访问:客户访问许可过多
HTTP 403.16 - 禁止访问:客户证书不可信或者无效
HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效
HTTP 404.1 - 无法找到 Web 站点
HTTP 404 - 无法找到文件
HTTP 405 - 资源被禁止
HTTP 406 - 无法接受
HTTP 407 - 要求代理身份验证
HTTP 410 - 永远不可用
HTTP 412 - 先决条件失败
HTTP 414 - 请求 - URI 太长
HTTP 500 - 内部服务器错误
HTTP 500.100 - 内部服务器错误 - ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误
20130329:
今天把整个项目改用SSM框架来写,晚上验收。
MyBatis的使用:
MyBatis原名ibatis,是2010年开始改为此名的,据网上介绍说,它相对Hibernate而言优点主要是:半封装、轻量级(不整合Spring的话只有一个jar包,才685kb),SQL语句还是我们自己写,但从数据中取出来的数据可以直接封装成对象,相比Hibernate为了方便而"牺牲性能",MyBatis二者都考虑了。
Demo项目结构:
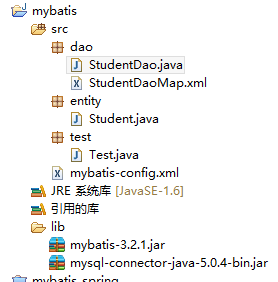
基本步骤:
-
新建一个Java项目
-
导入mybatis-3.2.1.jar和MySQL的驱动包
-
手工到数据库中建一个名为student的表,字段s_id,s_name,注意s_id设为自增:
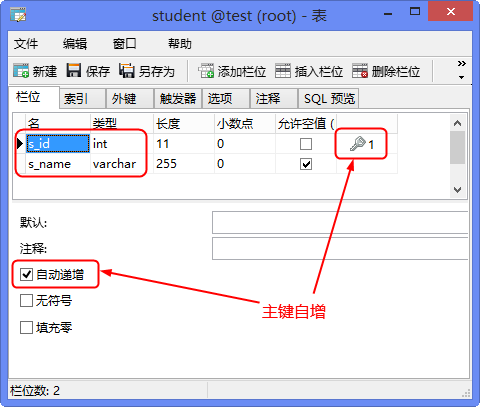
-
实体类:entity.Student.java
| public class Student { private int s_id; private String s_name; public Student(){} //省略get和set } |
5、dao.StudentDao.java:
| /** * @author LXA * 学生类Dao,注意必须是接口 */ public interface StudentDao { public void insert(Student student);//增 public void delete(int s_id);//删 public void update(Student student);//改 public Student getOne(int s_id);//查单个 public List<Student> getList();//查集合 } |
-
映射文件,SQL语句都写在这里面:
注意里面id都和上面的dao方法对应!
dao.StudentDaoMap.xml:
| <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="dao.StudentDao"> <insert id="insert" parameterType="entity.Student"> insert into student(s_name) values(#{s_name}) </insert> <delete id="delete" parameterType="int"> delete from student where s_id=#{s_id} </delete> <update id="update" parameterType="entity.Student"> update student set s_name=#{s_name} where s_id=#{s_id} </update> <select id="getOne" parameterType="int" resultType="entity.Student"> select * from student where s_id=#{s_id} </select> <select id="getList" resultType="entity.Student"> select * from student </select> </mapper> |
-
MyBatis配置文件:mybatis-config.xml
| <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <environments default="development"> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/test" /> <property name="username" value="root" /> <property name="password" value="1" /> </dataSource> </environment> </environments> <mappers> <mapper resource="dao/StudentDaoMap.xml" /> </mappers> </configuration> |
-
测试:Test.java
| public static void main(String[] args) throws IOException { String resource = "mybatis-config.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); //一般一个项目只需要一个factory SqlSession session=factory.openSession();//和Hibernate一样,一个session对应一个连接 StudentDao dao=session.getMapper(StudentDao.class); //这个dao建议和session一样,到用的时候再获取,也就是说其生命周期比较短
dao.insert(new Student("王老板"));//增,主键自增 dao.insert(new Student("刘显安")); dao.insert(new Student("小萃")); List<Student> list=dao.getList();//查 for(Student student:list) System.out.println(student.getS_id()+","+student.getS_name());
dao.update(new Student(22, "小小萃"));//改 Student student=dao.getOne(22);//查 System.out.println("修改之后:"+student.getS_id()+","+student.getS_name()); dao.delete(22);//删
session.commit();//提交 session.close();//关闭session } |
关于MyBatis多个参数的问题:
先看一下上面的例子:
| <update id="update" parameterType="entity.Student"> update student set s_name=#{s_name} where s_id=#{s_id} </update> |
修改时传入一个Student对象,在SQL中引用对象属性时我们直接用:
#{属性}即可。
但是如果传入多个参数呢?
网上有的用Map方式,有的用Bean方式,最简单的还是下面这样:
假设某方法如下(当然这个例子不是很恰当):
| public void update(Student student,int abc);//改 |
因为它有2个参数,所以这样改写:
| public void update(@Param("s")Student student,@Param("abc")int abc);//改 |
然后映射文件如下:
| <update id="update" parameterType="entity.Student"> update student set s_name=#{s.s_name} where s_id=#{abc} </update> |
意思是:因为有多个参数,所以现在要引用某个参数的属性,需指定其名称以免混淆(这里是s),而名称就是在方法里面用@Param指定的。
MyBatis的if和sql引用:
无需多言,看看就能明白:
| /** * 查询总的记录条数 * @return */ public int getCount(@Param("vo")ShiftSheetInfoVO vo); |
映射文件:
| <select id="getCount" resultType="int"> select count(*) from shift_sheet_info where 1=1 <include refid="queryLike"/> </select> <sql id="queryLike"> <if test="vo.sheet_num!=null and vo.sheet_num !=''"> and sheet_num like #{vo.sheet_num} </if> <if test="vo.sheet_name!=null and vo.sheet_name!=''"> and sheet_name like #{vo.sheet_name} </if> </sql> |
MyBatis的模糊查询和in语法:
MyBatis会自动在所有的形如#{s_id}外面加上个单引号,所以模糊查询用不了:
一般模糊查询语句如下:
| select * from student where s_name like '%萃%' |
(MySQL中单引号和双引号都可用)
这样写肯定是错误的:
| select * from student where s_name like %'萃'% |
所以在MyBatis中貌似模糊查询用不了,因为:
不管是#{%s_name%}还是%#{s_name}%都不正确!
下面分析一下in语法行不通的问题:
当主键为int类型时:
| select * from student where s_id in (1,2,3,5,7) |
当主键为varchar类型时:
| select * from student where s_id in ('安','萃','涛哥') |
因为MyBatis会自动在传入的字符串2边加上单引号,所以如果我们传入的字符串是(即头和尾不要单引号,中间有单引号和逗号):
安','萃','涛哥
那么理论上是可以查询的到数据的,但是坑爹的是,MyBatis自动把我们自己的单引号全部给转义了:
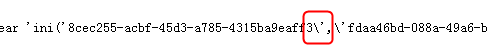
另外说明一点,如果想看到执行后的SQL语句,可以故意把它附近的语句写错,比如上面的我故意把in写成ini,所以肯定会报错,在页面上就可以看到真正的SQL语句了。
几点总结:
-
MyBatis的dao让spring管理的方法:所有dao都继承自一个BaseDao,然后在Spring的配置文件中指定BaseDao这一个bean即可,其它继承的Dao都会自动创建Bean。
-
JSTL的一个小问题:<c:forEach>里面是可以嵌套<c:if>的,只是在你刚开始写的时候IDE可能会提示错误,但是等你写完了就不会再提示了。
如:
| <c:forEach items="${shift_factory }" var="sf"> <option value="${sf.codeCoding }"<c:if test="${sf.codeCoding== vo.out_factory}">selected</c:if>>${sf.codeName }</option> </c:forEach> |
-
MySQL中时间类型一般用java.sql.TimeStamp
-
MySQL和SQL Server一样有数据库自带的自增属性,不像Oracle还要单独搞一个Sequence,麻烦!
-
MySQL的分页也比Oracle简单多了,一个limit 20,10即表示每页10条记录、查询第3页,前面一个是索引(从0开始),后面是查询的条数
-
浏览器的兼容性还是一个很大的问题!
-
Hibernate真的是一个重量级框架!很重很重!一个项目中加了Hibernate后启动速度大打折扣!
-
注解就是比配置好用,但像MyBatis把原本放在Java代码中的SQL语句放到Xml配置文件中,如果再反过来把SQL语句改用注解来写在Java类中,那真不知道对这说什么好了!个人觉得实在没必要!
SSM整合步骤:
整个demo程序结构如下,先在数据库手工建一个student的表再往下看:
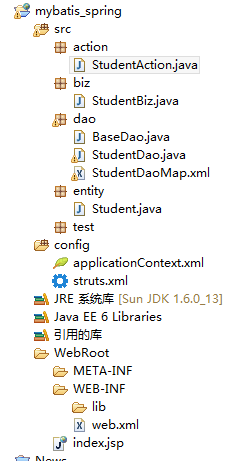
-
导入好多好多包,struts的、mybatis的2个,spring一大堆,自己稍微整理了下:
-
和配置SSH类似,web.xml的几个配置:
| <!-- Struts2过滤器 --> <filter> <filter-name>struts2</filter-name> <filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class> </filter> <!-- Struts2过滤器映射 --> <filter-mapping> <filter-name>struts2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
<!-- Spring编码过滤器 --> <filter> <filter-name>encodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> </filter> <!-- Spring编码过滤器映射 --> <filter-mapping> <filter-name>encodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
<!-- Spring 配置文件的本地路径 --> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext.xml</param-value> </context-param>
<!-- Spring配置信息加载监听器 Context Listener --> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <!-- Spring Web请求监听器 --> <listener> <listener-class> org.springframework.web.context.request.RequestContextListener</listener-class> </listener> |
-
struts.xml文件,这个太简单,省略了。
-
applicationContext.xml:
| <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.1.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.1.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd">
<context:component-scan base-package="action,dao,biz,util,aop"/> <!-- 设置Aop --> <aop:aspectj-autoproxy proxy-target-class="true"/> <!-- 数据源 --> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="com.mysql.jdbc.Driver"/> <property name="jdbcUrl" value="jdbc:mysql://localhost:3306/test"/> <property name="user" value="root"/> <property name="password" value="1"/> </bean>
<!-- SessionFactory --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource" /> <!-- 指定Map映射文件的路径 --> <property name="mapperLocations" value="classpath:dao/*.xml" /> </bean> <!-- 注册BaseDao --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="dao"/> <property name="markerInterface" value="dao.BaseDao"/> </bean> </beans> |
-
实体类Student.java,字段就是s_id和s_name2个,代码就略了。
-
在dao包下建一个BaseDao.java:
| package dao; /** * @author LXA * 最顶头的dao,所有dao都继承这个接口,目的是为了避免每个dao都在spring中注册 */ public interface BaseDao {
} |
-
再在dao包下新建一个StudentDao.java,注意继承自BaseDao.java( 注意dao不能使用注解):
| /** * @author LXA * 学生类DAO,继承自BaseDao,注意是一个接口 */ public interface StudentDao extends BaseDao { public void insert(Student student);//增 public void delete(int s_id);//删 public void update(Student student);//改 public Student getOne(int s_id);//查单个 public List<Student> getList();//查集合 } |
-
映射文件见: MyBatis的使用部分。
-
业务层:StudentBiz.java:
| @Service public class StudentBiz { @Resource private StudentDao dao; public Student getOne(int s_id) { return dao.getOne(s_id); } } |
-
Action层:StudentAction.java:
| @Controller public class StudentAction { @Resource private StudentBiz biz; public String login() { Student student=biz.getOne(18); System.out.println(student.getS_name()); return "ok"; } } |
10、使用浏览器访问指定页面即可。
20130330:
基于MySQL的MyBatis分页:
select * from student limit 20,10;
以上语句表示每页10条,查询第3页。第一个20表示起始数据的索引(0表示第1条),后面的10表示查询10条记录。
MyBatis中如下使用:
StudentDao.java部分代码如下:
| /** * 获取学生信息列表 * @param stu 封装模糊查询的对象 * @param start 起始记录索引 * @param pageSize 每一页的大小 * @return */ public List<Student> getList(@Param("s")Student stu, @Param("start")int start,@Param("pageSize")int pageSize); |
映射文件:
| <select id="getList" resultType="entity.Student"> select * from student where 1=1 <if test="s.s_name!=null and s.s_name !=''"> and s_name like #{s.s_name} </if> limit #{start},#{pageSize} </select> |
显然这样不方便,因为每次调用还要自己计算起始索引,所以还应当在业务层进行二次封装:
StudentBiz.java部分代码:
| /** * 获取学生信息列表 * @param vo 封装模糊查询的对象 * @param pageNo 页数 */ public List<Student> getList(Student s,int page,int pageSize) { return dao.getList(s,(page-1)*pageSize,pageSize); } |
JS中的EL表达式:
JavaScript中注释过的EL表达式仍然会被编译!(只能说这是EL表达式的一个天大的Bug),比如你写一个错误的EL表达式然后给它注释掉,访问那个页面还是会报错的。
关于Struts执行的流程:
20130331:
Eclipse一个不好的地方:
运行前不会自动保存没有保存的文件!
启动Eclipse时提示工作空间选择:
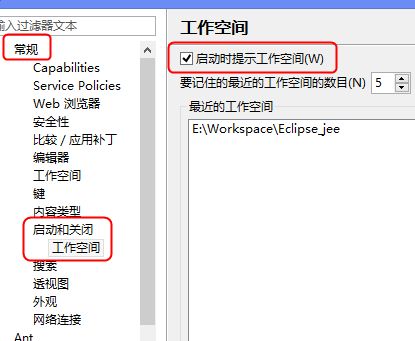
20130412(实习真正第一天):
关于Struts2与自定义过滤器冲突的问题:
自定义了一个过滤器,内容如下:
| public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("进入自定义过滤器"); chain.doFilter(request, response); } |
如果自定义的过滤器映射放在struts2的前面,不论是拦截具体的后缀(如*.aaa)还是为/*,2个过滤器都能正常进入:
| <filter> <filter-name>test1</filter-name><!-- 自定义过滤器 --> <filter-class>filter.StrutsFilter</filter-class> </filter> <filter-mapping> <filter-name>test1</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
<filter> <filter-name>struts2</filter-name> <filter-class> org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter </filter-class> </filter> <filter-mapping> <filter-name>struts2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
如果自定义过滤器放在了struts2的后面的话:
-
如果自定义拦截的时/*,访问struts符合的后缀URL时(如.do,.action等)之进入struts过滤器,否则进入自定义的过滤器。
-
如果拦截的是具体的,如*.bbb,那么只有访问的url后缀是bbb时才进入自定义。
总结:一句话,Struts很霸道,如果Struts过滤器放在了前面,那么一旦Struts把URL当成一个action,那么就不会进入自定义过滤器,如果自定义放在了前面,那么好办,一切正常OK!