爬虫实战:链接爬虫实战
假设我们想要把一个网页中所有的链接地址提取出来,我们可以通过python爬虫实现。
思路
- 确定好要爬取的入口链接
- 根据需求构建好链接提取的正则表达式
- 模拟成浏览器并爬取对应网页
- 根据步骤2的正则表达式提取出该网页中的链接
- 过滤掉重复链接
- 后续操作,如打印出链接。
第一步:入口链接
个人博客
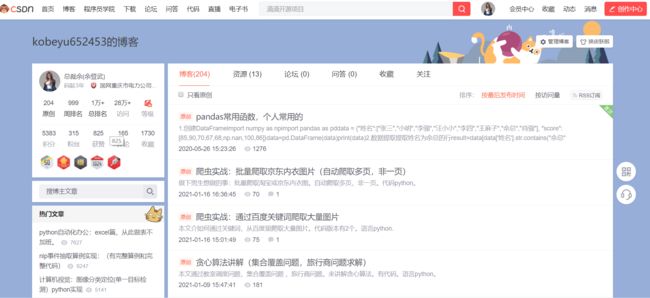
网址
https://blog.csdn.net/KOBEYU652453?spm=1001.2101.3001.5343
第二步:定义正则表达式
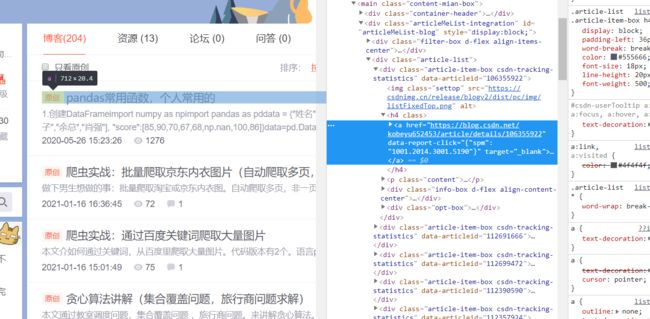
链接示例
href="https://blog.csdn.net/kobeyu652453/article/details/106355922
正则用法教程链接
python :re模块基本用法
于是我们可以定义正则规则
pat='(https?://[^\s)";]+\.(\w|/)*)' #^\匹配任何非空白字符 \w任何数字字母 * 0个或多个
因为有的网址是http,非https,如何在s后面加?号。
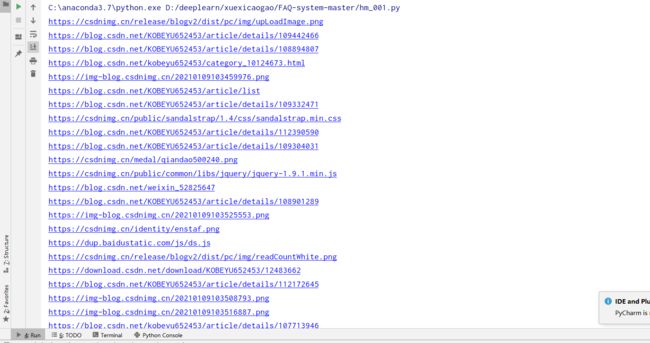
全文代码
import re
import urllib.request
from urllib import request
def getlink(url):
headers = ("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 将opener安装为全局
urllib.request.install_opener(opener)
url_request = request.Request(url)
html1 = request.urlopen(url_request, timeout=10)
data=str(html1.read())
#根据需要定义正则表达式
pat = '(https?://[^\s)";]+\.(\w|/)*)' # ^\匹配任何非空白字符 \w任何数字字母 * 0个或多个
link=re.compile(pat).findall(data)
#去除重复元素
link=set(link)
return link
url='https://blog.csdn.net/KOBEYU652453?spm=1001.2101.3001.5343'
linklist=getlink(url)
for link in linklist:
print(link[0])
![]()
作者:电气-余登武