[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
- Abstract
- Introduction
- Related Work
-
- Referring Image Segmentation
- Video Object Segmentation
- Multi-modal Video Understanding
- Refer-Youtube-VOS Dataset
- URVOS
-
- Visual Encoder
- Language Encoder
- Cross-modal Attention Module
- Memory Attention Module
- Decoder with Feature Pyramid Network
- Inference
- Experiments
Abstract
URVOS takes a video and a referring expression as inputs, and estimates the object masks referred by the given language expression in the whole video frames.
URVOS 使用视频和相应的表达作为输入,并预测整个视频帧中给定语言表达式相关的对象mask。
Our algorithm addresses the challenging problem by performing language-based object segmentation and mask propagation jointly using a single deep neural network with a proper combination of two attention models.
URVOS通过使用单个深度神经网络以及两个注意力模块的恰当结合,解决了联合执行基于语言的对象分割和mask传播带来的挑战。
we construct the first large-scale referring video object segmentation dataset called Refer-Youtube-VOS.
基于Youtube-VOS建立了第一个大规模参考视频分割数据集,即通过video+caption来执行分割。
本文在RefCOCO和RefVOS两个数据集上进行实验,证明模型有效性
( 比Khoreva, A., Rohrbach, A., Schiele, B.: Video object segmentation with language referring expressions.大一个数量级 referring DAVIS )
The dataset is released at https://github.com/skynbe/Refer-Youtube-VOS.
Introduction
Unsupervised techniques perform segmentation without the guidance for foreground objects, and aim to estimate the object masks using salient features, independent motions, or known class labels automatically.
Due to the ambiguity and the lack of flexibility in defining foreground objects, such approaches may be suitable for video analysis but not for video editing that requires to segment arbitrary objects or their parts flexibly.
基于caption分割的好处:由于定义前景对象时具有歧义且缺乏灵活性,不适用于需要灵活地分割任意对象或其部分的视频编辑任务。(无监督模式下通常都基于帧间连续性或者运动特征来确定前景对象,但是分割的前景对象在一些场景下具有局限性,并且在多目标分割上具有困难。)
URVOS is an end-to-end framework for referring video object segmentation,
which performs referring image segmentation and semi-supervised video object
segmentation jointly in a single model.(a referring image segmentation method initializes an object mask at a certain frame and then a video object segmentation method propagates the mask to the rest of the frames缺乏鲁棒性,URVOS将两个任务统一到了一起。 )
文中给出了一种新颖的交互方式叫做referring VOS:联合了基于caption的图像分割和半监督视频对象分割方法。(如果泛化能力足够强或者训练的数据量足够大,可以自由地选择前景对象进行分割)
contribution:
1、引入大规模referring VOS,其包含了用于3900+视频的27000+ referring expressions。(在数据集中给出了第一帧的caption和整个视频的caption)
2、提出了一个统一的端到端的深度神经网络,使用单个网络来同时执行基于语言的对象分割和mask传播。
3、与以前方法相比,显著提升性能。
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第1张图片](http://img.e-com-net.com/image/info8/a7a2e17c28c74ed9a5d02f8ded4e455d.jpg)
Related Work
Referring Image Segmentation
This task aims to produce a segmentation mask of an object in an input image given a natural language expression.
该任务旨在在给定自然语言表达的情况下在输入图像中生成对象的分割蒙版。
ECCV(2016):Segmentation from natural language expressions.
SNLE:用Baseline提出该任务,依赖于从LSTM和CNN多模态视觉-语言特征。
链接: link.
CVPR(2018):Referring image segmentation via recurrent refinement networks.
RRN:利用了特征金字塔来利用多尺度语义信息来referring image segmentation。
CVPR(2018):Mattnet: Modular attention network for referring expression comprehension.
MAttNet:引入了模块化注意力网络,该网络将多模态推理模型分解为主体,客体和关系模块,并利用注意力集中在相关模块上。
CVPR(2019):Cross-modal self-attention network for referring image segmentation.
CMSA:利用跨模式自注意力特征来桥接语言和视觉域的注意力,并有效地捕获视觉和语言模态之间的long-range关联。
URVOS使用了CMSA的变种来有效地得到跨模态注意特征。
Video Object Segmentation
URVOS belongs to offline learning, which modifies the non-local module of STM for its integration into our memory attention network and exploits temporal coherence of segmentation results.
Multi-modal Video Understanding
语言和视频理解的交互在各个领域进行了研究:visual tracking, action segmentation, video captioning and video question answering.
Refer-Youtube-VOS Dataset
YouTube-VOS:4519 high-resolution videos with 94 common object categories. Each video has pixel-level instance segmentation annotation at every 5 frames in 30-fps videos, and their durations are around 3 to 6 seconds.
We employed Amazon Mechanical Turk to annotate referring expressions.
ReferVOS collected two kinds of annotations, which describe the highlighted object (1) based on a whole video (Full-video expression) and (2) using only the first frame of the video (First-frame expression). After the initial annotation, we conducted verification and cleaning jobs for all annotations, and dropped objects if an object cannot be localized using language expressions only.
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第2张图片](http://img.e-com-net.com/image/info8/756881658a1b4a86b179125af4ed6b21.jpg)
带注释的第一帧对象数量少于完整视频表达的对象数量,因为仅使用第一帧会使注释更加模糊和不一致,并且在验证过程中我们丢弃了更多注释。
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第3张图片](http://img.e-com-net.com/image/info8/f4e96490b84d47f59ad6202fe4b0838b.jpg)
URVOS
we cast the referring video object segmentation task as a joint problem of referring object segmentation in an image and mask propagation in a video . We propose a unified framework that performs referring image segmentation and video object segmentation jointly. Given a video and a referring expression, our network estimates an object mask in an input frame using the linguistic referring expression and the mask predictions in the previous frames. We iteratively process video frames until the mask predictions in all frames converge.
给定视频和参照表达式,我们的网络使用语言参照表达式和先前帧中的mask预测来估计target frame的mask预测。 我们迭代处理视频帧,直到所有帧中的掩码预测都收敛为止。
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第4张图片](http://img.e-com-net.com/image/info8/260dd47f52474513af9d195465084221.jpg)
Visual Encoder
使用ResNet-50作为backbone来提取输入帧的视觉特征。为了补充视觉特征的空间信息,按照SNLE的策略添加了8个维度的空间坐标。具体的,我们让 F F F和 f p f_{p} fp分别代表一个视觉特征和F上一个确定空间位置为p处的切片视觉特征, p ∈ { 1 , 2 , 3 , . . . . . , H ∗ W } p \in \{1,2,3,.....,H*W\} p∈{ 1,2,3,.....,H∗W}。我们直接concat空间坐标 s p s_{p} sp和 f p f_{p} fp来得到location-aware visual features:
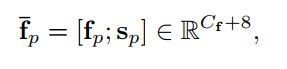
s p s_{p} sp表示8通道的空间坐标特征。在URVOS上仅使用Res5和Res4的特征。

Language Encoder
给定一个引用表达式,表达式中的一系列单词被编码成mutil-hot 向量,并且使用线性层被以 C e C_{e} Ce为维度数投影到嵌入空间中。 为了在保持表达式中语义的同时对语言表达式的顺序性质进行建模,我们在每个单词位置添加位置编码(NIPS2017.Attention is all you need)。使用 w l w_{l} wl表示l-th单词的嵌入向量, p l p_{l} pl表示l-th单词在表达式的位置。通过聚合两种嵌入向量,可以得到语言特征。
![]()
Cross-modal Attention Module
Using both visual and lingual features, we produce a joint cross-modal feature representation by concatenating the features in both the domains.
通过使用视觉特征和语言特征,我们concat两个域中的特征得到了联合跨模态特征表示。
我们首先对每个特征独立使用self-attention,再concat联合特征以有效地捕获两种模态之间的复杂对齐。每个self-attention module 将 每个特征映射到 C a C_{a} Ca维空间。

SA*()表示对每个域的自监督模块。我们直接合并得到在空间位置p和单词位置I的联合跨模态特征:

我们对所有的 c p l c_{pl} cpl进行聚合,得到一个跨模态特征图(空间位置为HW个,词向量L个,每个位置p、词向量位置l对应2 C a C_{a} Ca通道数):
![]()
接下来对C应用self-attention:
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第5张图片](http://img.e-com-net.com/image/info8/b5e0ff288b68420d931470ee4b59b526.jpg)
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第6张图片](http://img.e-com-net.com/image/info8/b7b35f38fab64e6fbe26d21b28630c11.jpg)
Memory Attention Module
借鉴STM,为了利用先前处理的帧的预测mask,设计了一个Memory Attention Module。该模块通过计算当前帧的视觉特征图与前一帧的mask-encoded的视觉特征图之间的相关性,从前一帧检索相关信息。通过另一个特征提取器获得了蒙版编码的视觉特征,该特征提取器通过在通道方向上堆叠RGB图像及其分段蒙版获得4个通道输入。
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第7张图片](http://img.e-com-net.com/image/info8/61769b9846c8418192f2f4ccc2894d60.jpg)
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第8张图片](http://img.e-com-net.com/image/info8/7f4e3dfcc2f7488689a8f29be848eb63.jpg)
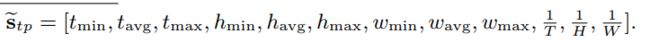
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第9张图片](http://img.e-com-net.com/image/info8/024da773fe8b4eb3a8b30de48f366781.jpg)
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第10张图片](http://img.e-com-net.com/image/info8/9936282dfbfd4fa48e95641c129d63b1.jpg)
此模块中,我们针对目标和内存帧均采用了第四阶段特征(Res4),因为它需要更多描述性特征来计算帧局部区域之间的相关性,而跨模式注意模块则采用了第五阶段特征(Res5) )以利用更多的语义信息。
Decoder with Feature Pyramid Network
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第11张图片](http://img.e-com-net.com/image/info8/5970f415864348188b90cfa3313b13a0.jpg)
在第一层和第二层分别结合cross-attentive features和cross-attentive features,来有效地捕捉多模态和时序信息。
不使用特征金字塔的最后输出作为mask生成,我们按照BFPN使用额外的self-attention模块来增强所有level下特征的语义。我们在归一化特征尺寸之后对所有特征求平均,并且对combined feature maps应用一个self-attention。将得到的特征rescaled到原始尺寸,并通过恒等连接与初始输出聚合。遵循(Panoptic feature pyramid networks),这些多尺度输出被用于生成输入图片1/4大小的mask。
Inference
网络输入: a target image, memory images and their mask predictions, and a language expression
由于第一帧没有预测的mask,使用了一个novel two-stage过程,能够充分利用提出的两个注意力模块。
First stage:不使用memory frame来执行网络,这仅仅基于语言表达式对每帧进行独立预测mask。在得到初始的每帧mask预测,我们通过选择一个与语言表达式置信度最高的mask作为anchor mask。(we calculate the confidence score of each frame by averaging the pixelwsie final segmentation scores and select the frame with the highest one.)
Second stage:在第二阶段,我们使用完整的网络从锚点到两端更新初始分割结果。我们首先将锚帧设置为存储帧,然后通过从锚帧顺序传播掩码预测来重新估计对象掩码。在每一帧更新遮罩预测后,我们将图像及其遮罩添加到内存中。但是,实际上,将所有先前的帧累积到内存中可能会导致内存溢出问题并降低推理速度。为了缓解此问题,我们将最大存储帧数设置为T。如果内存帧数达到T,则我们用新的预测替换内存中的最低置信帧。请注意,我们利用存储帧中的先前掩码预测并估计目标帧的掩码。同时,我们在第二阶段也使用语言表达作为指导,这使我们能够处理具有挑战性的场景,例如漂移和遮挡。我们基于每次迭代中识别出的新锚点,通过重复第二阶段来迭代地细化细分。
Experiments
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第12张图片](http://img.e-com-net.com/image/info8/6ddad4be5a6142eaade174fa4f910b45.jpg)
prec@X,表示设置阈值,如果一个视频帧的J分数大于X,则视为该帧被成功分割。
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第13张图片](http://img.e-com-net.com/image/info8/f89dc95f1ff941e0bd42a05705f4f45e.jpg)
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第14张图片](http://img.e-com-net.com/image/info8/fb0780b9edc34e9b8d267a1503d7a301.jpg)
数据集规模对结果的影响:
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第15张图片](http://img.e-com-net.com/image/info8/456e1ca2939844419389729b41a010c7.jpg)
Inference:
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第16张图片](http://img.e-com-net.com/image/info8/7093363f79244873b7ee11c26b722f52.jpg)
![[论文阅读2020]URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark_第17张图片](http://img.e-com-net.com/image/info8/d6a567aedc7b4dcdbddc1303a7a33502.jpg)