Alluxio的Raft HA实现
文章目录
- 前言
- 基于Raft实现的要点
- Alluxio Raft HA实现的相关角色类
- Alluxio Raft HA部分场景分析
-
- Leader重新选举监听处理
- JournalStateMachine的状态apply处理
- Raft HA过程调用
- 参考资料
前言
Alluxio在HA的实现上,早期实现的方式是基于ZK(用来做领导选举)+shared journal storage(状态同步)的方式来达到其服务高可用性的,这种方式和HDFS的HA实现十分类似。不过后来Alluxio社区实现了基于Raft协议的新的HA实现方式,这里的Raft实现依赖了开源Raft Java实现库Apache Ratis。作为全新的HA实现,本文笔者结合Alluxio相关代码来简单聊聊里面的一些实现细节。
基于Raft实现的要点
Raft一致性协议算法目前逐渐被越来越多的大型系统所使用,比如对象存储系统Apache Ozone。Ozone内部的数据一致性控制依赖的实现也是Apache Ratis。
对于同样要依赖Apache Ratis做Raft HA实现的Alluxio系统来说,它需要特别关注哪几个要点的实现呢?这里笔者结合之前对于Ozone以及Apache Ratis的了解,列出以下几点:
- StateMachine,状态机的定义,不同的系统它所谓的状态机的概念是不同的。比如以存储系统而言,大部分情况可理解为为master元数据的控制更新
- Leader/Follower节点的选举,重新选举时的回调执行操作
以上两点是笔者认为做Raft实现需要尤其考虑实现的点,其它的部分我们再结合实际的系统实现做对应逻辑的适配修改。比如本文今天所讲述的这样的一个系统就是Alluxio。
Alluxio Raft HA实现的相关角色类
下面我们结合Alluxio的代码做Alluxio Raft HA实现的介绍。
首先一个主要的中心控制类RaftJournalSystem,此类里包括了状态机,raft journal writer等等与Raft journal HA实现的相关角色类。
RaftPrimarySelector, Primary选举监听类,当有新的leader选举时,此类会监听回调对应的执行执行。
RaftJournalWriter,Raft Journal信息的写出类。此类会调用Raft Client向其它master server组进行journal信息的写出。
JournalStateMachine,状态机的定义实现类,此类负责master状态的更新以及snapshot的定期take操作。
BufferedJournalApplier,负责apply journal信息到master的类。此类内部额外维护了一个suspend buffer队列,用类临时存放暂停时间段待apply的raft journal信息。
SnapshotReplicationManager,snapshot管理类,在Raft server中,Follower会进行snapshot的take并upload snapshot到Leader的Raft Server里。
Alluxio Raft HA部分场景分析
Leader重新选举监听处理
当发生了新的Leader选举时,Alluxio的master目前是怎么样的一个action操作?
首先我们来看与此相关的角色类,RaftPrimarySelector,代码如下:
/**
* A primary selector backed by a Raft consensus cluster.
*/
@ThreadSafe
public class RaftPrimarySelector extends AbstractPrimarySelector {
/**
* Notifies leadership state changed.
* @param state the leadership state
*/
public void notifyStateChanged(State state) {
setState(state);
}
@Override
public void start(InetSocketAddress address) throws IOException {
// The Ratis cluster is owned by the outer {@link RaftJournalSystem}.
}
@Override
public void stop() throws IOException {
// The Ratis cluster is owned by the outer {@link RaftJournalSystem}.
}
}
此类基本继承父类的实现,只是对外方法里额外重置了一个状态。我们在基于ZK做Leader选举的时候,ZK是有提供对应接口监听得到新的Leader信息的。同理基于Raft实现的Apache Ratis同样有这么一个接口方法。
在JournalStateMachine的notifyLeaderChanged方法里,能监听到这个动作,随之会调用到RaftPrimarySelector#notifyStateChanged方法的执行,相关代码如下:
@Override
public void notifyLeaderChanged(RaftGroupMemberId groupMemberId, RaftPeerId raftPeerId) {
if (mRaftGroupId == groupMemberId.getGroupId()) {
mIsLeader = groupMemberId.getPeerId() == raftPeerId;
mJournalSystem.notifyLeadershipStateChanged(mIsLeader);
} else {
LOG.warn("Received notification for unrecognized group {}, current group is {}",
groupMemberId.getGroupId(), mRaftGroupId);
}
}
...
/**
* Notifies the journal that the leadership state has changed.
* @param isLeader whether the local server is teh current leader
*/
public void notifyLeadershipStateChanged(boolean isLeader) {
mPrimarySelector.notifyStateChanged(
isLeader ? PrimarySelector.State.PRIMARY : PrimarySelector.State.SECONDARY);
}
PrimarySelector在setState操作里会调用之前注册过的listener方法,因此在每次master状态发生变化的时候,它会执行下面的操作方法(FaultTolerantAlluxioMasterProcess#gainPrimacy):
private boolean gainPrimacy() throws Exception {
// Don't upgrade if this master's primacy is unstable.
AtomicBoolean unstable = new AtomicBoolean(false);
try (Scoped scoped = mLeaderSelector.onStateChange(state -> unstable.set(true))) {
// 判断当前角色是否是Primary
if (mLeaderSelector.getState() != State.PRIMARY) {
unstable.set(true);
}
stopMasters();
LOG.info("Secondary stopped");
try (Timer.Context ctx = MetricsSystem
.timer(MetricKey.MASTER_JOURNAL_GAIN_PRIMACY_TIMER.getName()).time()) {
// 先让journal system变为Primary的角色,此过程会有transaction的catch up操作
mJournalSystem.gainPrimacy();
}
// 如果不是Primary服务,则再执行对应非Primary相关的执行操作,比如stop journal writer
// 随后返回
if (unstable.get()) {
losePrimacy();
return false;
}
}
// 以Primary master身份启动master服务
startMasters(true);
mServingThread = new Thread(() -> {
try {
startServing(" (gained leadership)", " (lost leadership)");
} catch (Throwable t) {
Throwable root = Throwables.getRootCause(t);
if ((root != null && (root instanceof InterruptedException)) || Thread.interrupted()) {
return;
}
ProcessUtils.fatalError(LOG, t, "Exception thrown in main serving thread");
}
}, "MasterServingThread");
mServingThread.start();
if (!waitForReady(10 * Constants.MINUTE_MS)) {
ThreadUtils.logAllThreads();
throw new RuntimeException("Alluxio master failed to come up");
}
LOG.info("Primary started");
return true;
}
Journal system在变为Primary过程中,会进行关键的journal的catch up操作,保证其内部StateMachine apply了最新的journal transaction。
与此对应的(FaultTolerantAlluxioMasterProcess#)losePrimacy方法,发生在master监听发现自身已经不是Primary角色之后执行的。
private void losePrimacy() throws Exception {
if (mServingThread != null) {
stopServing();
}
// Put the journal in secondary mode ASAP to avoid interfering with the new primary. This must
// happen after stopServing because downgrading the journal system will reset master state,
// which could cause NPEs for outstanding RPC threads. We need to first close all client
// sockets in stopServing so that clients don't see NPEs.
mJournalSystem.losePrimacy();
if (mServingThread != null) {
mServingThread.join(mServingThreadTimeoutMs);
if (mServingThread.isAlive()) {
ProcessUtils.fatalError(LOG,
"Failed to stop serving thread after %dms. Serving thread stack trace:%n%s",
mServingThreadTimeoutMs, ThreadUtils.formatStackTrace(mServingThread));
}
mServingThread = null;
// 停止内部服务
stopMasters();
LOG.info("Primary stopped");
}
// 以非Primary角色重启内部服务
startMasters(false);
LOG.info("Secondary started");
}
JournalStateMachine的状态apply处理
另外一块关键的处理是JournalStateMachine状态机的状态apply处理,关键操作方法如下:
JournalStateMachine#applyTransaction:
@Override
public CompletableFuture<Message> applyTransaction(TransactionContext trx) {
try {
applyJournalEntryCommand(trx);
RaftProtos.LogEntryProto entry = Objects.requireNonNull(trx.getLogEntry());
updateLastAppliedTermIndex(entry.getTerm(), entry.getIndex());
// explicitly return empty future since no response message is expected by the journal writer
// avoid using super.applyTransaction() since it will echo the message and add overhead
return EMPTY_FUTURE;
} catch (Exception e) {
return RaftJournalUtils.completeExceptionally(e);
}
}
在上面的过程中,TransactionContext会被解析成具体的journal entry,然后apply到master state里去。
private void applySingleEntry(JournalEntry entry) {
...
mNextSequenceNumberToRead++;
if (!mIgnoreApplys) {
// journal applier(BufferedJournalApplier)类负责完成此步骤
mJournalApplier.processJournalEntry(entry);
}
}
这里的master state有多种子类的实现,比如InodeTreePersistentState。
Raft HA过程调用
上面小节只展示了部分的Raft HA过程处理,一个全局的HA过程调用图如下所示,笔者列出了文中提到的几个关键角色服务在图内,并没有涵盖所有的细节。
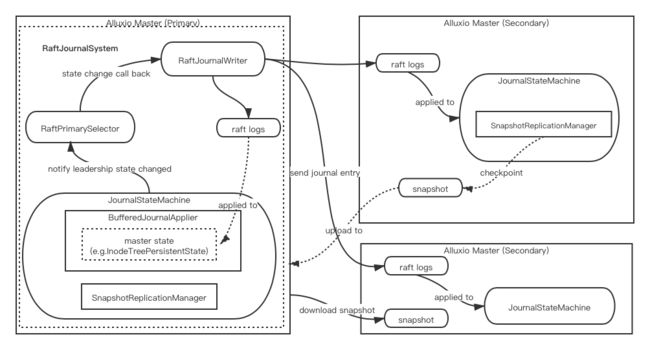
以上就是本文所阐述的主要内容了,有兴趣的同学可以阅读学习Alluxio 其它方式的HA的实现细节。
参考资料
[1].https://docs.alluxio.io/os/user/stable/en/deploy/Running-Alluxio-On-a-HA-Cluster.html#zookeeper-and-shared-journal-storage