【我的区块链之路】- 以太坊源码剖析之Geth节点启动全量过程详解
【转载请标明出处】https://blog.csdn.net/qq_25870633/article/details/82992805
最近在整理前端时间学习的源码,由于源码的学习是片段的,那么我们在这篇文章中把它关联起来,这篇文章我们讲P2P部分,我们会从Geth的入口一直到后面的节点发现,节点间广播及同步TX和Block的讲解。首先,我这里先不说fetcher 及downloader的具体工作流程,只是从geth函数作为入口,把它做了哪些事情,及和p2p相关的部分细化征程一张流程图先展示出来,然后,我们在跟着代码一步步的分析。
废话不多说,先上图:

好了,我知道的流程比较复杂,图也很大,我这里已经对 fetcher 和downloader 部分剪出来,单独做成图另外讲解了!那么,长话短说,我们直接上代码分析了:
我们先看下 go-ehereum/cmd/geth路径下的main.go 文件的main函数中做了些什么事:
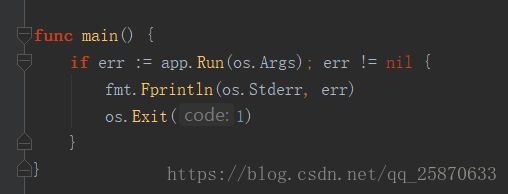
很简单,就是一个app.Run(os.Args)。因为在以太坊中是用了一个第三方库来解析命令行,gopkg.in/urfave/cli.v1 所以,我们只需要知道,app其实就是这个第三方库的一个实例,在当前main.go文件的最上面定义全局变量有一行:
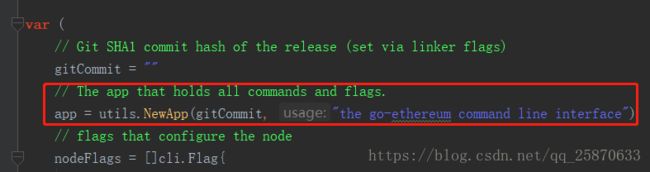
然后,我们又在init函数中发现了:

这一行,所以我们只需要知道其实app.Run就是会调用app.Action 成员所引用的函数。不必深究这个第三方库的使用,这不是我们本文的重点。
我们先看下 geth 函数中做了些什么事情。
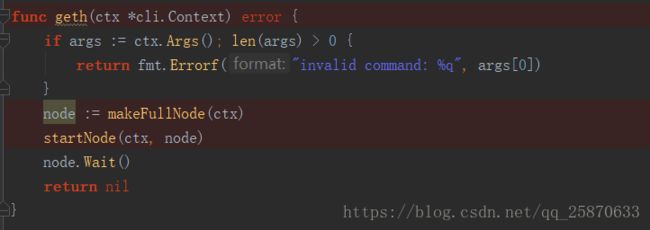
OK,里面总共就做了三件事:
- 创建一个本地node实例
- 启动本地的node实例
- 阻塞本地node实例进程(监听退出事件)
但是,这三件事,其实是底层的很多件事情编织到一起的。
我们一个一个来对这三件事进行分析,首先看看实例化node实例里面做了些什么:
初始化node节点:
func makeFullNode(ctx *cli.Context) *node.Node {
stack, cfg := makeConfigNode(ctx)
utils.RegisterEthService(stack, &cfg.Eth)
if ctx.GlobalBool(utils.DashboardEnabledFlag.Name) {
utils.RegisterDashboardService(stack, &cfg.Dashboard, gitCommit)
}
// Whisper must be explicitly enabled by specifying at least 1 whisper flag or in dev mode
shhEnabled := enableWhisper(ctx)
shhAutoEnabled := !ctx.GlobalIsSet(utils.WhisperEnabledFlag.Name) && ctx.GlobalIsSet(utils.DeveloperFlag.Name)
if shhEnabled || shhAutoEnabled {
if ctx.GlobalIsSet(utils.WhisperMaxMessageSizeFlag.Name) {
cfg.Shh.MaxMessageSize = uint32(ctx.Int(utils.WhisperMaxMessageSizeFlag.Name))
}
if ctx.GlobalIsSet(utils.WhisperMinPOWFlag.Name) {
cfg.Shh.MinimumAcceptedPOW = ctx.Float64(utils.WhisperMinPOWFlag.Name)
}
utils.RegisterShhService(stack, &cfg.Shh)
}
// Add the Ethereum Stats daemon if requested.
if cfg.Ethstats.URL != "" {
utils.RegisterEthStatsService(stack, cfg.Ethstats.URL)
}
return stack
}根据之前初始化的上下文配置(创建app对象的时候),先调用 stack, cfg := makeConfigNode(ctx) 构造出一个node实例,及相关的配置信息 cfg。
然后,紧接着分别注册了 Eth服务、dashboard服务、shh服务及EthStats服务。其中注册的动作,都是调用了 utils.RegisterEthService(...) 方法做的,我们跟进去看里面到底做了什么事情。
// 注册Eth服务
func RegisterEthService(stack *node.Node, cfg *eth.Config) {
var err error
if cfg.SyncMode == downloader.LightSync {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
return les.New(ctx, cfg)
})
} else {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
fullNode, err := eth.New(ctx, cfg)
if fullNode != nil && cfg.LightServ > 0 {
ls, _ := les.NewLesServer(fullNode, cfg)
fullNode.AddLesServer(ls)
}
return fullNode, err
})
}
if err != nil {
Fatalf("Failed to register the Ethereum service: %v", err)
}
}
// 注册dashboard服务
func RegisterDashboardService(stack *node.Node, cfg *dashboard.Config, commit string) {
stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
return dashboard.New(cfg, commit, ctx.ResolvePath("logs")), nil
})
}
// 注册shh服务
func RegisterShhService(stack *node.Node, cfg *whisper.Config) {
if err := stack.Register(func(n *node.ServiceContext) (node.Service, error) {
return whisper.New(cfg), nil
}); err != nil {
Fatalf("Failed to register the Whisper service: %v", err)
}
}
// 注册EthStats服务
func RegisterEthStatsService(stack *node.Node, url string) {
if err := stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
// Retrieve both eth and les services
var ethServ *eth.Ethereum
ctx.Service(ðServ)
var lesServ *les.LightEthereum
ctx.Service(&lesServ)
return ethstats.New(url, ethServ, lesServ)
}); err != nil {
Fatalf("Failed to register the Ethereum Stats service: %v", err)
}
}
我们可以看到,每一种注册的底层实现,其实都是调用了 stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {}) 函数,再跟进这个函数中看:
func (n *Node) Register(constructor ServiceConstructor) error {
n.lock.Lock()
defer n.lock.Unlock()
if n.server != nil {
return ErrNodeRunning
}
n.serviceFuncs = append(n.serviceFuncs, constructor)
return nil
}很简单的实现,就是把入参的 各类Service的创建函数作为入参,并都收集到node实例的 serviceFuncs 切片中。那么,我们现在就已经理解了什么是想node节点注册服务了。无非就是把各个创建服务的函数全部都收集到node实例的serviceFuncs切片中去。(请记住这块逻辑的操作,后续我们会用到)。
因为是涉及讲P2P部分的逻辑,所以我们这里只注重将Eth服务部分。我们看看在注册Eth服务是入参的所谓EthService的构造函数是怎么实现的 (即:eth.New(ctx, cfg) 的实现):
func New(ctx *node.ServiceContext, config *Config) (*Ethereum, error) {
if config.SyncMode == downloader.LightSync {
return nil, errors.New("can't run eth.Ethereum in light sync mode, use les.LightEthereum")
}
if !config.SyncMode.IsValid() {
return nil, fmt.Errorf("invalid sync mode %d", config.SyncMode)
}
chainDb, err := CreateDB(ctx, config, "chaindata")
if err != nil {
return nil, err
}
chainConfig, genesisHash, genesisErr := core.SetupGenesisBlock(chainDb, config.Genesis)
if _, ok := genesisErr.(*params.ConfigCompatError); genesisErr != nil && !ok {
return nil, genesisErr
}
log.Info("Initialised chain configuration", "config", chainConfig)
eth := &Ethereum{
config: config,
chainDb: chainDb,
chainConfig: chainConfig,
eventMux: ctx.EventMux,
accountManager: ctx.AccountManager,
engine: CreateConsensusEngine(ctx, &config.Ethash, chainConfig, chainDb),
shutdownChan: make(chan bool),
networkID: config.NetworkId,
gasPrice: config.GasPrice,
etherbase: config.Etherbase,
bloomRequests: make(chan chan *bloombits.Retrieval),
bloomIndexer: NewBloomIndexer(chainDb, params.BloomBitsBlocks),
}
log.Info("Initialising Ethereum protocol", "versions", ProtocolVersions, "network", config.NetworkId)
if !config.SkipBcVersionCheck {
bcVersion := rawdb.ReadDatabaseVersion(chainDb)
if bcVersion != core.BlockChainVersion && bcVersion != 0 {
return nil, fmt.Errorf("Blockchain DB version mismatch (%d / %d). Run geth upgradedb.\n", bcVersion, core.BlockChainVersion)
}
rawdb.WriteDatabaseVersion(chainDb, core.BlockChainVersion)
}
var (
vmConfig = vm.Config{EnablePreimageRecording: config.EnablePreimageRecording}
cacheConfig = &core.CacheConfig{Disabled: config.NoPruning, TrieNodeLimit: config.TrieCache, TrieTimeLimit: config.TrieTimeout}
)
eth.blockchain, err = core.NewBlockChain(chainDb, cacheConfig, eth.chainConfig, eth.engine, vmConfig)
if err != nil {
return nil, err
}
// Rewind the chain in case of an incompatible config upgrade.
if compat, ok := genesisErr.(*params.ConfigCompatError); ok {
log.Warn("Rewinding chain to upgrade configuration", "err", compat)
eth.blockchain.SetHead(compat.RewindTo)
rawdb.WriteChainConfig(chainDb, genesisHash, chainConfig)
}
eth.bloomIndexer.Start(eth.blockchain)
if config.TxPool.Journal != "" {
config.TxPool.Journal = ctx.ResolvePath(config.TxPool.Journal)
}
eth.txPool = core.NewTxPool(config.TxPool, eth.chainConfig, eth.blockchain)
if eth.protocolManager, err = NewProtocolManager(eth.chainConfig, config.SyncMode, config.NetworkId, eth.eventMux, eth.txPool, eth.engine, eth.blockchain, chainDb); err != nil {
return nil, err
}
eth.miner = miner.New(eth, eth.chainConfig, eth.EventMux(), eth.engine)
eth.miner.SetExtra(makeExtraData(config.ExtraData))
eth.APIBackend = &EthAPIBackend{eth, nil}
gpoParams := config.GPO
if gpoParams.Default == nil {
gpoParams.Default = config.GasPrice
}
eth.APIBackend.gpo = gasprice.NewOracle(eth.APIBackend, gpoParams)
return eth, nil
}可以看得出来,代码还是不少的,那么该函数一进来就做了这么几件事:
- 创建一个操作链的DB实例:
chainDb, err := CreateDB(ctx, config, "chaindata") - 根据DB实例初始化创世块及相关链的初识配置信息:
chainConfig, genesisHash, genesisErr := core.SetupGenesisBlock(chainDb, config.Genesis) - 创建一个最顶层的结构Ethereum结构的实例:
eth := &Ethereum{ config: config, chainDb: chainDb, chainConfig: chainConfig, eventMux: ctx.EventMux, accountManager: ctx.AccountManager, engine: CreateConsensusEngine(ctx, &config.Ethash, chainConfig, chainDb), shutdownChan: make(chan bool), networkID: config.NetworkId, gasPrice: config.GasPrice, etherbase: config.Etherbase, bloomRequests: make(chan chan *bloombits.Retrieval), bloomIndexer: NewBloomIndexer(chainDb, params.BloomBitsBlocks), }(我们可以看到,共识引擎及布隆过滤服务也同时被实例化在Ethereum对象中)
- 检查DB的版本:
if !config.SkipBcVersionCheck { bcVersion := rawdb.ReadDatabaseVersion(chainDb) if bcVersion != core.BlockChainVersion && bcVersion != 0 { return nil, fmt.Errorf("Blockchain DB version mismatch (%d / %d). Run geth upgradedb.\n", bcVersion, core.BlockChainVersion) } rawdb.WriteDatabaseVersion(chainDb, core.BlockChainVersion) } - 加载整条完整链:
eth.blockchain, err = core.NewBlockChain(chainDb, cacheConfig, eth.chainConfig, eth.engine, vmConfig)(这里后续文章中再做细讲)
- 启动布隆过滤服务:
eth.bloomIndexer.Start(eth.blockchain) - 初始化交易池:
eth.txPool = core.NewTxPool(config.TxPool, eth.chainConfig, eth.blockchain) - 初始化P2P协议管理 pm 实例:
if eth.protocolManager, err = NewProtocolManager(eth.chainConfig, config.SyncMode, config.NetworkId, eth.eventMux, eth.txPool, eth.engine, eth.blockchain, chainDb); err != nil { return nil, err }【注意】:这个是超级超级重点的,请记住这里,我们下面讲
- 初始化一个矿工实例:
eth.miner = miner.New(eth, eth.chainConfig, eth.EventMux(), eth.engine) - 初始化Gas预言机:
eth.APIBackend.gpo = gasprice.NewOracle(eth.APIBackend, gpoParams)
以上就是在EthService的构造函数中去实例化一个EthService实现所做的事情。由于本文注重讲P2P部分,所以在上面第8点中,初始化一个协议管理pm实例是一部超级重要的操作,我们可以跟进去看看:上源码
func NewProtocolManager(config *params.ChainConfig, mode downloader.SyncMode, networkID uint64, mux *event.TypeMux, txpool txPool, engine consensus.Engine, blockchain *core.BlockChain, chaindb ethdb.Database) (*ProtocolManager, error) {
// Create the protocol manager with the base fields
manager := &ProtocolManager{
networkID: networkID,
eventMux: mux,
txpool: txpool,
blockchain: blockchain,
chainconfig: config,
peers: newPeerSet(),
newPeerCh: make(chan *peer),
noMorePeers: make(chan struct{}),
txsyncCh: make(chan *txsync),
quitSync: make(chan struct{}),
}
// Figure out whether to allow fast sync or not
if mode == downloader.FastSync && blockchain.CurrentBlock().NumberU64() > 0 {
log.Warn("Blockchain not empty, fast sync disabled")
mode = downloader.FullSync
}
if mode == downloader.FastSync {
manager.fastSync = uint32(1)
}
// Initiate a sub-protocol for every implemented version we can handle
manager.SubProtocols = make([]p2p.Protocol, 0, len(ProtocolVersions))
for i, version := range ProtocolVersions {
// Skip protocol version if incompatible with the mode of operation
if mode == downloader.FastSync && version < eth63 {
continue
}
// Compatible; initialise the sub-protocol
version := version // Closure for the run
manager.SubProtocols = append(manager.SubProtocols, p2p.Protocol{
Name: ProtocolName,
Version: version,
Length: ProtocolLengths[i],
Run: func(p *p2p.Peer, rw p2p.MsgReadWriter) error {
peer := manager.newPeer(int(version), p, rw)
select {
case manager.newPeerCh <- peer:
manager.wg.Add(1)
defer manager.wg.Done()
return manager.handle(peer)
case <-manager.quitSync:
return p2p.DiscQuitting
}
},
NodeInfo: func() interface{} {
return manager.NodeInfo()
},
PeerInfo: func(id discover.NodeID) interface{} {
if p := manager.peers.Peer(fmt.Sprintf("%x", id[:8])); p != nil {
return p.Info()
}
return nil
},
})
}
if len(manager.SubProtocols) == 0 {
return nil, errIncompatibleConfig
}
// Construct the different synchronisation mechanisms
manager.downloader = downloader.New(mode, chaindb, manager.eventMux, blockchain, nil, manager.removePeer)
validator := func(header *types.Header) error {
return engine.VerifyHeader(blockchain, header, true)
}
heighter := func() uint64 {
return blockchain.CurrentBlock().NumberU64()
}
inserter := func(blocks types.Blocks) (int, error) {
// If fast sync is running, deny importing weird blocks
if atomic.LoadUint32(&manager.fastSync) == 1 {
log.Warn("Discarded bad propagated block", "number", blocks[0].Number(), "hash", blocks[0].Hash())
return 0, nil
}
atomic.StoreUint32(&manager.acceptTxs, 1) // Mark initial sync done on any fetcher import
return manager.blockchain.InsertChain(blocks)
}
manager.fetcher = fetcher.New(blockchain.GetBlockByHash, validator, manager.BroadcastBlock, heighter, inserter, manager.removePeer)
return manager, nil
}以上函数在初始化pm实例时,主要做了以下操作:
- 初始化ProtocolManager实例:
// Create the protocol manager with the base fields manager := &ProtocolManager{ networkID: networkID, eventMux: mux, txpool: txpool, blockchain: blockchain, chainconfig: config, peers: newPeerSet(), newPeerCh: make(chan *peer), noMorePeers: make(chan struct{}), txsyncCh: make(chan *txsync), quitSync: make(chan struct{}), }(类似Ethereum对象的实例化一样,在实例化自身的同时,创建了一些重要的成员,其中最主要的为:newPeerSet() 创建了一个本地缓存远端peer实例的Set、newPeerCh 监听新节点的通道、txsyncCh 监听由 远端节点及本地交易池中交易数组组成的 信息的通道)
- 使用for循环去收集创建好的 Protocol 实例,其中在Protocol创建时,会个自己的几个函数类型成员赋值,最重要的是Run函数的赋值,我们看代码可以看出,里面做了两件事情,a:把新加入的节点信息封装成一个peer,往通道 newPeerCh 中发送,且会回调pm实例的Handle 函数【注意:这个Run函数超级重要】;
- 实例化downloader :(后面讲downloader时再讲)
// Construct the different synchronisation mechanisms manager.downloader = downloader.New(mode, chaindb, manager.eventMux, blockchain, nil, manager.removePeer) - 实例化 fetcher :(后面讲fetcher时再讲)
manager.fetcher = fetcher.New(blockchain.GetBlockByHash, validator, manager.BroadcastBlock, heighter, inserter, manager.removePeer)
然后,我们在上面知道了在pm实例化是会去实例化protocol实例并收集起来,而protocol实力在创建时,会在自己的Run函数中回调pm的Handle 函数,那么其实,很多 tx及Block、BlockHash的广播,同步等操作都会在 pm的Handle函数中完成,之所以是用了回调,是因为需要:每当有一个新的远端节点与当前节点发生TCP连接的时候,只要后续把protocol给Run起来的话,就会触发pm.Handle() 的回调去做各种各样的事情。下面,我们来看看pm的Handle函数又是做了些什么事情呢?
1、一进来先做了一步本地node根据缓存在本地的peer信息去和该peer的真实远端节点做握手
func (p *peer) Handshake(network uint64, td *big.Int, head common.Hash, genesis common.Hash) error {
// Send out own handshake in a new thread
errc := make(chan error, 2)
var status statusData // safe to read after two values have been received from errc
go func() {
errc <- p2p.Send(p.rw, StatusMsg, &statusData{
ProtocolVersion: uint32(p.version),
NetworkId: network,
TD: td,
CurrentBlock: head,
GenesisBlock: genesis,
})
}()
go func() {
errc <- p.readStatus(network, &status, genesis)
}()
timeout := time.NewTimer(handshakeTimeout)
defer timeout.Stop()
for i := 0; i < 2; i++ {
select {
case err := <-errc:
if err != nil {
return err
}
case <-timeout.C:
return p2p.DiscReadTimeout
}
}
p.td, p.head = status.TD, status.CurrentBlock
return nil
}我们可以看到,无非就是Send了个 StatusMsg 的状态,然后起一个监听 p.readStatus(network, &status, genesis) ,【注意】这两个是属于两个P2P节点的一来一回的哦
2、想本地pm的peerSet中注册这个新连接的peer实例:
// Register the peer locally
if err := pm.peers.Register(p); err != nil {
p.Log().Error("Ethereum peer registration failed", "err", err)
return err
}
defer pm.removePeer(p.id)这个里面其实也只是做了下面找个几件事:
func (ps *peerSet) Register(p *peer) error {
ps.lock.Lock()
defer ps.lock.Unlock()
if ps.closed {
return errClosed
}
if _, ok := ps.peers[p.id]; ok {
return errAlreadyRegistered
}
ps.peers[p.id] = p
go p.broadcast()
return nil
}func (p *peer) broadcast() {
for {
select {
case txs := <-p.queuedTxs:
if err := p.SendTransactions(txs); err != nil {
return
}
p.Log().Trace("Broadcast transactions", "count", len(txs))
case prop := <-p.queuedProps:
if err := p.SendNewBlock(prop.block, prop.td); err != nil {
return
}
p.Log().Trace("Propagated block", "number", prop.block.Number(), "hash", prop.block.Hash(), "td", prop.td)
case block := <-p.queuedAnns:
if err := p.SendNewBlockHashes([]common.Hash{block.Hash()}, []uint64{block.NumberU64()}); err != nil {
return
}
p.Log().Trace("Announced block", "number", block.Number(), "hash", block.Hash())
case <-p.term:
return
}
}
}a、先把该节点实例放置pm的peerSet中
b、异步发起真实的P2P广播,其实就是起了一个一直循环处理 分别调了三个方法:把缓存在本地的peerSet中的peer内部的交易信息txs、区块信息Block、区块头Hash 都使用P2P的方式发给当前peer。
3、将当前peer注册到downloader中:
if err := pm.downloader.RegisterPeer(p.id, p.version, p); err != nil {
return err
}4、把本地交易池txpool中的交易信息分别按照缓存在本地pm中的peer逐个构建 txsync 结构体并塞入 pm.txsyncCh 通道 【请记住这个通道】,以便后续分peer去广播txs。这时候其实是还没有发起真实的P2P哦。和上面第2步中那三个发P2P的不一样哦。
pm.syncTransactions(p)func (pm *ProtocolManager) syncTransactions(p *peer) {
var txs types.Transactions
pending, _ := pm.txpool.Pending()
for _, batch := range pending {
txs = append(txs, batch...)
}
if len(txs) == 0 {
return
}
select {
case pm.txsyncCh <- &txsync{p, txs}:
case <-pm.quitSync:
}
}5、死循环一直在处理这 handleMsg 方法:【注意】这个方法超级重要,是一个重要的核心方法
for {
if err := pm.handleMsg(p); err != nil {
p.Log().Debug("Ethereum message handling failed", "err", err)
return err
}
}func (pm *ProtocolManager) handleMsg(p *peer) error {
// Read the next message from the remote peer, and ensure it's fully consumed
msg, err := p.rw.ReadMsg()
if err != nil {
return err
}
if msg.Size > ProtocolMaxMsgSize {
return errResp(ErrMsgTooLarge, "%v > %v", msg.Size, ProtocolMaxMsgSize)
}
defer msg.Discard()
// Handle the message depending on its contents
switch {
case msg.Code == StatusMsg:
// Status messages should never arrive after the handshake
return errResp(ErrExtraStatusMsg, "uncontrolled status message")
// Block header query, collect the requested headers and reply
case msg.Code == GetBlockHeadersMsg:
// Decode the complex header query
var query getBlockHeadersData
if err := msg.Decode(&query); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
hashMode := query.Origin.Hash != (common.Hash{})
first := true
maxNonCanonical := uint64(100)
// Gather headers until the fetch or network limits is reached
var (
bytes common.StorageSize
headers []*types.Header
unknown bool
)
for !unknown && len(headers) < int(query.Amount) && bytes < softResponseLimit && len(headers) < downloader.MaxHeaderFetch {
// Retrieve the next header satisfying the query
var origin *types.Header
if hashMode {
if first {
first = false
origin = pm.blockchain.GetHeaderByHash(query.Origin.Hash)
if origin != nil {
query.Origin.Number = origin.Number.Uint64()
}
} else {
origin = pm.blockchain.GetHeader(query.Origin.Hash, query.Origin.Number)
}
} else {
origin = pm.blockchain.GetHeaderByNumber(query.Origin.Number)
}
if origin == nil {
break
}
headers = append(headers, origin)
bytes += estHeaderRlpSize
// Advance to the next header of the query
switch {
case hashMode && query.Reverse:
// Hash based traversal towards the genesis block
ancestor := query.Skip + 1
if ancestor == 0 {
unknown = true
} else {
query.Origin.Hash, query.Origin.Number = pm.blockchain.GetAncestor(query.Origin.Hash, query.Origin.Number, ancestor, &maxNonCanonical)
unknown = (query.Origin.Hash == common.Hash{})
}
case hashMode && !query.Reverse:
// Hash based traversal towards the leaf block
var (
current = origin.Number.Uint64()
next = current + query.Skip + 1
)
if next <= current {
infos, _ := json.MarshalIndent(p.Peer.Info(), "", " ")
p.Log().Warn("GetBlockHeaders skip overflow attack", "current", current, "skip", query.Skip, "next", next, "attacker", infos)
unknown = true
} else {
if header := pm.blockchain.GetHeaderByNumber(next); header != nil {
nextHash := header.Hash()
expOldHash, _ := pm.blockchain.GetAncestor(nextHash, next, query.Skip+1, &maxNonCanonical)
if expOldHash == query.Origin.Hash {
query.Origin.Hash, query.Origin.Number = nextHash, next
} else {
unknown = true
}
} else {
unknown = true
}
}
case query.Reverse:
// Number based traversal towards the genesis block
if query.Origin.Number >= query.Skip+1 {
query.Origin.Number -= query.Skip + 1
} else {
unknown = true
}
case !query.Reverse:
// Number based traversal towards the leaf block
query.Origin.Number += query.Skip + 1
}
}
return p.SendBlockHeaders(headers)
case msg.Code == BlockHeadersMsg:
// A batch of headers arrived to one of our previous requests
var headers []*types.Header
if err := msg.Decode(&headers); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// If no headers were received, but we're expending a DAO fork check, maybe it's that
if len(headers) == 0 && p.forkDrop != nil {
// Possibly an empty reply to the fork header checks, sanity check TDs
verifyDAO := true
// If we already have a DAO header, we can check the peer's TD against it. If
// the peer's ahead of this, it too must have a reply to the DAO check
if daoHeader := pm.blockchain.GetHeaderByNumber(pm.chainconfig.DAOForkBlock.Uint64()); daoHeader != nil {
if _, td := p.Head(); td.Cmp(pm.blockchain.GetTd(daoHeader.Hash(), daoHeader.Number.Uint64())) >= 0 {
verifyDAO = false
}
}
// If we're seemingly on the same chain, disable the drop timer
if verifyDAO {
p.Log().Debug("Seems to be on the same side of the DAO fork")
p.forkDrop.Stop()
p.forkDrop = nil
return nil
}
}
// Filter out any explicitly requested headers, deliver the rest to the downloader
filter := len(headers) == 1
if filter {
// If it's a potential DAO fork check, validate against the rules
if p.forkDrop != nil && pm.chainconfig.DAOForkBlock.Cmp(headers[0].Number) == 0 {
// Disable the fork drop timer
p.forkDrop.Stop()
p.forkDrop = nil
// Validate the header and either drop the peer or continue
if err := misc.VerifyDAOHeaderExtraData(pm.chainconfig, headers[0]); err != nil {
p.Log().Debug("Verified to be on the other side of the DAO fork, dropping")
return err
}
p.Log().Debug("Verified to be on the same side of the DAO fork")
return nil
}
// Irrelevant of the fork checks, send the header to the fetcher just in case
headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now())
}
if len(headers) > 0 || !filter {
err := pm.downloader.DeliverHeaders(p.id, headers)
if err != nil {
log.Debug("Failed to deliver headers", "err", err)
}
}
case msg.Code == GetBlockBodiesMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
// Gather blocks until the fetch or network limits is reached
var (
hash common.Hash
bytes int
bodies []rlp.RawValue
)
for bytes < softResponseLimit && len(bodies) < downloader.MaxBlockFetch {
// Retrieve the hash of the next block
if err := msgStream.Decode(&hash); err == rlp.EOL {
break
} else if err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Retrieve the requested block body, stopping if enough was found
if data := pm.blockchain.GetBodyRLP(hash); len(data) != 0 {
bodies = append(bodies, data)
bytes += len(data)
}
}
return p.SendBlockBodiesRLP(bodies)
case msg.Code == BlockBodiesMsg:
// A batch of block bodies arrived to one of our previous requests
var request blockBodiesData
if err := msg.Decode(&request); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Deliver them all to the downloader for queuing
transactions := make([][]*types.Transaction, len(request))
uncles := make([][]*types.Header, len(request))
for i, body := range request {
transactions[i] = body.Transactions
uncles[i] = body.Uncles
}
// Filter out any explicitly requested bodies, deliver the rest to the downloader
filter := len(transactions) > 0 || len(uncles) > 0
if filter {
transactions, uncles = pm.fetcher.FilterBodies(p.id, transactions, uncles, time.Now())
}
if len(transactions) > 0 || len(uncles) > 0 || !filter {
err := pm.downloader.DeliverBodies(p.id, transactions, uncles)
if err != nil {
log.Debug("Failed to deliver bodies", "err", err)
}
}
case p.version >= eth63 && msg.Code == GetNodeDataMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
// Gather state data until the fetch or network limits is reached
var (
hash common.Hash
bytes int
data [][]byte
)
for bytes < softResponseLimit && len(data) < downloader.MaxStateFetch {
// Retrieve the hash of the next state entry
if err := msgStream.Decode(&hash); err == rlp.EOL {
break
} else if err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Retrieve the requested state entry, stopping if enough was found
if entry, err := pm.blockchain.TrieNode(hash); err == nil {
data = append(data, entry)
bytes += len(entry)
}
}
return p.SendNodeData(data)
case p.version >= eth63 && msg.Code == NodeDataMsg:
// A batch of node state data arrived to one of our previous requests
var data [][]byte
if err := msg.Decode(&data); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Deliver all to the downloader
if err := pm.downloader.DeliverNodeData(p.id, data); err != nil {
log.Debug("Failed to deliver node state data", "err", err)
}
case p.version >= eth63 && msg.Code == GetReceiptsMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
// Gather state data until the fetch or network limits is reached
var (
hash common.Hash
bytes int
receipts []rlp.RawValue
)
for bytes < softResponseLimit && len(receipts) < downloader.MaxReceiptFetch {
// Retrieve the hash of the next block
if err := msgStream.Decode(&hash); err == rlp.EOL {
break
} else if err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Retrieve the requested block's receipts, skipping if unknown to us
results := pm.blockchain.GetReceiptsByHash(hash)
if results == nil {
if header := pm.blockchain.GetHeaderByHash(hash); header == nil || header.ReceiptHash != types.EmptyRootHash {
continue
}
}
// If known, encode and queue for response packet
if encoded, err := rlp.EncodeToBytes(results); err != nil {
log.Error("Failed to encode receipt", "err", err)
} else {
receipts = append(receipts, encoded)
bytes += len(encoded)
}
}
return p.SendReceiptsRLP(receipts)
case p.version >= eth63 && msg.Code == ReceiptsMsg:
// A batch of receipts arrived to one of our previous requests
var receipts [][]*types.Receipt
if err := msg.Decode(&receipts); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Deliver all to the downloader
if err := pm.downloader.DeliverReceipts(p.id, receipts); err != nil {
log.Debug("Failed to deliver receipts", "err", err)
}
case msg.Code == NewBlockHashesMsg:
var announces newBlockHashesData
if err := msg.Decode(&announces); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
// Mark the hashes as present at the remote node
for _, block := range announces {
p.MarkBlock(block.Hash)
}
// Schedule all the unknown hashes for retrieval
unknown := make(newBlockHashesData, 0, len(announces))
for _, block := range announces {
if !pm.blockchain.HasBlock(block.Hash, block.Number) {
unknown = append(unknown, block)
}
}
for _, block := range unknown {
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
}
case msg.Code == NewBlockMsg:
// Retrieve and decode the propagated block
var request newBlockData
if err := msg.Decode(&request); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
request.Block.ReceivedAt = msg.ReceivedAt
request.Block.ReceivedFrom = p
// Mark the peer as owning the block and schedule it for import
p.MarkBlock(request.Block.Hash())
pm.fetcher.Enqueue(p.id, request.Block)
// Assuming the block is importable by the peer, but possibly not yet done so,
// calculate the head hash and TD that the peer truly must have.
var (
trueHead = request.Block.ParentHash()
trueTD = new(big.Int).Sub(request.TD, request.Block.Difficulty())
)
// Update the peers total difficulty if better than the previous
if _, td := p.Head(); trueTD.Cmp(td) > 0 {
p.SetHead(trueHead, trueTD)
// Schedule a sync if above ours. Note, this will not fire a sync for a gap of
// a singe block (as the true TD is below the propagated block), however this
// scenario should easily be covered by the fetcher.
currentBlock := pm.blockchain.CurrentBlock()
if trueTD.Cmp(pm.blockchain.GetTd(currentBlock.Hash(), currentBlock.NumberU64())) > 0 {
go pm.synchronise(p)
}
}
case msg.Code == TxMsg:
// Transactions arrived, make sure we have a valid and fresh chain to handle them
if atomic.LoadUint32(&pm.acceptTxs) == 0 {
break
}
// Transactions can be processed, parse all of them and deliver to the pool
var txs []*types.Transaction
if err := msg.Decode(&txs); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
for i, tx := range txs {
// Validate and mark the remote transaction
if tx == nil {
return errResp(ErrDecode, "transaction %d is nil", i)
}
p.MarkTransaction(tx.Hash())
}
pm.txpool.AddRemotes(txs)
default:
return errResp(ErrInvalidMsgCode, "%v", msg.Code)
}
return nil
}不难看出,这个方法超级的长,但是却是属于由一个死循环一直在处理的,而方法里面无非就是对P2P节点双发发来的请求,解析对应的Msg.Code 来获取对应的请求状态,去做对应的请求处理。下面我们注重讲其中几个就可以了:
a、当收到的状态是 NewBlockHashesMsg 时:表示接收到了远端广播过来的BlockHash,先解析请求获取 announces数组;遍历announces数组对比出本地链上未出现的Block的hash及number收集到unknown数组中, 再根据逐一调用 pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies) 并把 请求区块头及请求区块体的函数实现传进去以备后续使用。
b、当收到的状态是 BlockHeadersMsg 时:表示接收到了远端广播过来的 BlockHeader,先解析请求获取 headers ,然后调用 headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now()) 过滤掉不合法的区块头,然后再使用 downloader去处理区块头 pm.downloader.DeliverHeaders(p.id, headers) 。
c、当接收到的状态是 BlockBodiesMsg 时:表示接收到了远端广播过来的 bodies 数组 blockBodiesData。先解析请求,过滤非法的body:pm.fetcher.FilterBodies(...),使用downloader处理 body:pm.downloader.DeliverBodies(...)。
再往下就是 fetcher 和downloader的逻辑中再细讲了。到目前为止,就是在初始化node的时候把关于P2P 部分【主要是tx及block广播等处理的逻辑,但是目前这些方法都只是在Protocol.Run 中写了 pm.Handle() 的回调而已,还诶有发起真实的调用,这里只相当于是注册而已,真实的调用需要在node启动部分才会有调到这里来】给讲解完了,下面我们来查看node启动部分,及P2P 请求部分的逻辑。
启动本地node节点实例:
由代码中我们可以看到节点启动,主要做了以下几件事:
1、启动node自身:【这个超级重要,下面我们要细讲】
// Start up the node itself
utils.StartNode(stack)2、启动并解锁账户相关:
// Unlock any account specifically requested
ks := stack.AccountManager().Backends(keystore.KeyStoreType)[0].(*keystore.KeyStore)3、订阅钱包事件:
stack.AccountManager().Subscribe(events)4、创建RPC client连接:
rpcClient, err := stack.Attach()5、检索运行的Ethereum服务:
if err := stack.Service(ðereum); err != nil {
utils.Fatalf("Ethereum service not running: %v", err)
}6、设置挖矿开启的线程数:
// Use a reduced number of threads if requested
if threads := ctx.GlobalInt(utils.MinerThreadsFlag.Name); threads > 0 {
type threaded interface {
SetThreads(threads int)
}
if th, ok := ethereum.Engine().(threaded); ok {
th.SetThreads(threads)
}
}7、根据命令行设置txpool的gasPrice,由矿工决定:
// Set the gas price to the limits from the CLI and start mining
ethereum.TxPool().SetGasPrice(utils.GlobalBig(ctx, utils.GasPriceFlag.Name))8、启动挖矿任务:
if err := ethereum.StartMining(true); err != nil {
utils.Fatalf("Failed to start mining: %v", err)
}好了,下面我们注重讲解,启动node自身这部分的逻辑,因为里面才是包含了真正的P2P部分。
启动node自身:
代码如下:
func StartNode(stack *node.Node) {
if err := stack.Start(); err != nil {
Fatalf("Error starting protocol stack: %v", err)
}
go func() {
sigc := make(chan os.Signal, 1)
signal.Notify(sigc, syscall.SIGINT, syscall.SIGTERM)
defer signal.Stop(sigc)
<-sigc
log.Info("Got interrupt, shutting down...")
go stack.Stop()
for i := 10; i > 0; i-- {
<-sigc
if i > 1 {
log.Warn("Already shutting down, interrupt more to panic.", "times", i-1)
}
}
debug.Exit() // ensure trace and CPU profile data is flushed.
debug.LoudPanic("boom")
}()
}可以看到一进来就做了两件事,一件是node.Start();一件是监听系统的退出信号来做程序退出,这里是吧 node.Wait() 里面监听的阻塞通道给stop掉。再跟进node.Start() 中看看:
func (n *Node) Start() error {
n.lock.Lock()
defer n.lock.Unlock()
// Short circuit if the node's already running
if n.server != nil {
return ErrNodeRunning
}
if err := n.openDataDir(); err != nil {
return err
}
// Initialize the p2p server. This creates the node key and
// discovery databases.
n.serverConfig = n.config.P2P
n.serverConfig.PrivateKey = n.config.NodeKey()
n.serverConfig.Name = n.config.NodeName()
n.serverConfig.Logger = n.log
if n.serverConfig.StaticNodes == nil {
n.serverConfig.StaticNodes = n.config.StaticNodes()
}
if n.serverConfig.TrustedNodes == nil {
n.serverConfig.TrustedNodes = n.config.TrustedNodes()
}
if n.serverConfig.NodeDatabase == "" {
n.serverConfig.NodeDatabase = n.config.NodeDB()
}
running := &p2p.Server{Config: n.serverConfig}
n.log.Info("Starting peer-to-peer node", "instance", n.serverConfig.Name)
// Otherwise copy and specialize the P2P configuration
services := make(map[reflect.Type]Service)
for _, constructor := range n.serviceFuncs {
// Create a new context for the particular service
ctx := &ServiceContext{
config: n.config,
services: make(map[reflect.Type]Service),
EventMux: n.eventmux,
AccountManager: n.accman,
}
for kind, s := range services { // copy needed for threaded access
ctx.services[kind] = s
}
// Construct and save the service
service, err := constructor(ctx)
if err != nil {
return err
}
kind := reflect.TypeOf(service)
if _, exists := services[kind]; exists {
return &DuplicateServiceError{Kind: kind}
}
services[kind] = service
}
// Gather the protocols and start the freshly assembled P2P server
for _, service := range services {
running.Protocols = append(running.Protocols, service.Protocols()...)
}
if err := running.Start(); err != nil {
return convertFileLockError(err)
}
// Start each of the services
started := []reflect.Type{}
for kind, service := range services {
// Start the next service, stopping all previous upon failure
if err := service.Start(running); err != nil {
for _, kind := range started {
services[kind].Stop()
}
running.Stop()
return err
}
// Mark the service started for potential cleanup
started = append(started, kind)
}
// Lastly start the configured RPC interfaces
if err := n.startRPC(services); err != nil {
for _, service := range services {
service.Stop()
}
running.Stop()
return err
}
// Finish initializing the startup
n.services = services
n.server = running
n.stop = make(chan struct{})
return nil
}主要做了下面几件事:
1、创建一个p2p.Server 实例:
running := &p2p.Server{Config: n.serverConfig}2、使用for循环逐个的初始化之前初始化node时被收集到node.ServiceFuns数组中的各个服务的构造函数,来初识化各个服务实例。
3、逐个的把各个服务中的Protocol收集到p2pServer中,待后面有用。【这里的Protocol就是之前收集到ProtocolManager对象中的具有Run函数并回调pm.Handle() 的那些Protocol实例】
4、启动p2pServer:【超级重要下面细讲】
if err := running.Start(); err != nil {
return convertFileLockError(err)
}5、根据p2pServer逐个的把各个服务启动:【超级重要下面细讲】
for kind, service := range services {
// Start the next service, stopping all previous upon failure
if err := service.Start(running); err != nil {
for _, kind := range started {
services[kind].Stop()
}
running.Stop()
return err
}
// Mark the service started for potential cleanup
started = append(started, kind)
}6、启动RPC服务:
里面分别对应着http、ws等等rpc服务的api等
if err := n.startRPC(services); err != nil {
for _, service := range services {
service.Stop()
}
running.Stop()
return err
}启动p2pServer:
1、根据需要定义底层协议传输实现:
if srv.newTransport == nil {
srv.newTransport = newRLPX
}2、初始化一大堆通道:
srv.quit = make(chan struct{})
srv.addpeer = make(chan *conn)
srv.delpeer = make(chan peerDrop)
srv.posthandshake = make(chan *conn)
srv.addstatic = make(chan *discover.Node)
srv.removestatic = make(chan *discover.Node)
srv.peerOp = make(chan peerOpFunc)
srv.peerOpDone = make(chan struct{})其中我们主要需要注意:srv.posthandshake 和 srv.addpeer 这两个通道。【请记住这两个通道】
3、nat记录UDP的内外网端口映射:
if srv.NAT != nil {
if !realaddr.IP.IsLoopback() {
go nat.Map(srv.NAT, srv.quit, "udp", realaddr.Port, realaddr.Port, "ethereum discovery")
}
// TODO: react to external IP changes over time.
if ext, err := srv.NAT.ExternalIP(); err == nil {
realaddr = &net.UDPAddr{IP: ext, Port: realaddr.Port}
}
}4、启动UDP:【注意】请记住这部分操作,很重要,下面细讲
if !srv.NoDiscovery {
cfg := discover.Config{
PrivateKey: srv.PrivateKey,
AnnounceAddr: realaddr,
NodeDBPath: srv.NodeDatabase,
NetRestrict: srv.NetRestrict,
Bootnodes: srv.BootstrapNodes,
Unhandled: unhandled,
}
ntab, err := discover.ListenUDP(conn, cfg)
if err != nil {
return err
}
srv.ntab = ntab
}5、加载启动节点信息:
加载配置中的远端peer的初始集【静态节点/启动节点】
dialer := newDialState(srv.StaticNodes, srv.BootstrapNodes, srv.ntab, dynPeers, srv.NetRestrict)6、启动TCP:【注意】请记住这部分操作,很重要,下面细讲
// listen/dial
if srv.ListenAddr != "" {
if err := srv.startListening(); err != nil {
return err
}
}7、把p2p的服务run起来 【根据初始集】【注意】请记住这部分操作,很重要,下面细讲
go srv.run(dialer)UDP启动:
启动UDP的过程中其实是做了很多件事的。
1、创建一个UDP实例:
udp := &udp{
conn: c,
priv: cfg.PrivateKey,
netrestrict: cfg.NetRestrict,
closing: make(chan struct{}),
gotreply: make(chan reply),
addpending: make(chan *pending),
}2、创建Table实例:(一个用来存储k-桶的对象)
tab, err := newTable(udp, PubkeyID(&cfg.PrivateKey.PublicKey), realaddr, cfg.NodeDBPath, cfg.Bootnodes)在创建这个table实例的过程中,分别:
a、实例化了一个操作lvlDB的实例
db, err := newNodeDB(nodeDBPath, nodeDBVersion, ourID)b、实例化一个table对象
tab := &Table{
net: t,
db: db,
self: NewNode(ourID, ourAddr.IP, uint16(ourAddr.Port), uint16(ourAddr.Port)),
refreshReq: make(chan chan struct{}),
initDone: make(chan struct{}),
closeReq: make(chan struct{}),
closed: make(chan struct{}),
rand: mrand.New(mrand.NewSource(0)),
ips: netutil.DistinctNetSet{Subnet: tableSubnet, Limit: tableIPLimit},
}c、设置启动节点信息到桶的tab.nursery数组中
if err := tab.setFallbackNodes(bootnodes); err != nil {
return nil, err
}d、加载部分随机的节点ID及所有的启动节点Id
tab.seedRand()
tab.loadSeedNodes()e、异步启动刷桶逻辑
go tab.loop()而异步刷桶中又分为:
【Ⅰ】每隔10秒钟刷心跳
func (tab *Table) doRevalidate(done chan<- struct{}) {
defer func() { done <- struct{}{} }()
last, bi := tab.nodeToRevalidate()
if last == nil {
// No non-empty bucket found.
return
}
// Ping the selected node and wait for a pong.
err := tab.net.ping(last.ID, last.addr())
tab.mutex.Lock()
defer tab.mutex.Unlock()
b := tab.buckets[bi]
if err == nil {
// The node responded, move it to the front.
log.Trace("Revalidated node", "b", bi, "id", last.ID)
b.bump(last)
return
}
// No reply received, pick a replacement or delete the node if there aren't
// any replacements.
if r := tab.replace(b, last); r != nil {
log.Trace("Replaced dead node", "b", bi, "id", last.ID, "ip", last.IP, "r", r.ID, "rip", r.IP)
} else {
log.Trace("Removed dead node", "b", bi, "id", last.ID, "ip", last.IP)
}
}先随机的选择一个桶并拿出它的entries队列的尾元素发起ping请求。如果ping成功,则把该元素移到entries队列头;否则,删除该元素,并从replacements队列随即一个元素放置entires队列尾。
【Ⅱ】每隔30秒刷桶
func (tab *Table) doRefresh(done chan struct{}) {
defer close(done)
// Load nodes from the database and insert
// them. This should yield a few previously seen nodes that are
// (hopefully) still alive.
tab.loadSeedNodes()
// Run self lookup to discover new neighbor nodes.
tab.lookup(tab.self.ID, false)
// The Kademlia paper specifies that the bucket refresh should
// perform a lookup in the least recently used bucket. We cannot
// adhere to this because the findnode target is a 512bit value
// (not hash-sized) and it is not easily possible to generate a
// sha3 preimage that falls into a chosen bucket.
// We perform a few lookups with a random target instead.
for i := 0; i < 3; i++ {
var target NodeID
crand.Read(target[:])
tab.lookup(target, false)
}
}
可以看出,先加载一波静态节点,然后根据当前节点信息先去刷一波桶拉回据当前节点的邻居节点;然后 for 3 次循环,每次生成一个随机nodeID即:target,再根据target去刷桶拉回距随机target节点的邻居节点。【其中刷桶均是调用了 tab.lookup(...) 函数】
3、异步启动一个 go udp.loop() :
在底层主要维护一个 plist 的pending信息队列 ,通过下面两个操作来维护:
监听 p := <-t.addpending 通道
监听 r := <-t.gotreply 通道
以上两个通道中的内容均由下面第4点的packet的回应实现中写入;回应实现分别为 neighbors 和pong。
4、异步启动一个 go udp.readLoop(...) :
死循环接收 UDP 数据包。
t.conn.ReadFromUDP(buf) 和 t.handlePacket(...)。其中t.handlePacket(...)底层是调用了packet的实现,分别有四种实现,即:ping、pong、findnode、neighbors。对于pong和neighbors 会往 第3点的那两个通道写入信息。
TCP启动:
主要有:启动TCP的Server 端,只有有远端的client与本地的server发生连接,就把连接实例conn写入启动p2pServer之初初始化的那堆通道中的 srv.addpeer 与 srv.posthandshake 通道 。
【注意:使用k-bucket中初识集的节点并对这些节点发起TCP 的client端的连接是在下面根据初始集去server.run的时候那里面做的】
终于到了今天的重头戏:
go srv.run(dialer):
根据初始集(即静态节点及启动节点)的节点去把p2p的服务run起来。
1、先创建各种节点连接及节点发现的任务:
// starts until max number of active tasks is satisfied
startTasks := func(ts []task) (rest []task) {
i := 0
for ; len(runningTasks) < maxActiveDialTasks && i < len(ts); i++ {
t := ts[i]
srv.log.Trace("New dial task", "task", t)
go func() { t.Do(srv); taskdone <- t }()
runningTasks = append(runningTasks, t)
}
return ts[i:]
}
scheduleTasks := func() {
// Start from queue first.
queuedTasks = append(queuedTasks[:0], startTasks(queuedTasks)...)
// Query dialer for new tasks and start as many as possible now.
if len(runningTasks) < maxActiveDialTasks {
nt := dialstate.newTasks(len(runningTasks)+len(queuedTasks), peers, time.Now())
queuedTasks = append(queuedTasks, startTasks(nt)...)
}
}请注意这里面的 t.Do(srv)函数,他有几个实现,其中最主要的是 负责向初始集发起TCPclient连接的 dialTask.Do( ) 和 节点发现的 discoverTask.Do( ):
节点连接dialTask.Do( ) :
会先去连接入参的初始集节点,t.dial(srv, t.dest);如果某个节点连接失败,就会根据该节点的ID去做刷桶动作;即首先去解析该节点 t.resolve(...) 在这个函数里面再调用真正的刷桶 tab.lookup(...);刷完桶之后,再抽出一部分节点集再去调用连接t.dial(srv, t.dest)【这里的调用连接,其实就是向从桶中抽出的节点集发起TCP client的连接】
节点发现discoverTask.Do( ):
则是直接根据初始集去做刷桶动作。
2、如果监听到 之前所说的 c := <-srv.addpeer通道 有新连接加入的话就根据该conn创建一个peer:p := newPeer(c, srv.Protocols)。
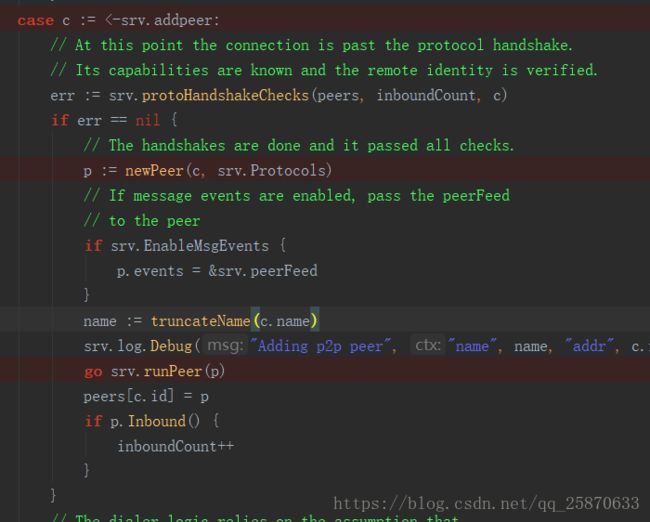
3、根据这个新创建的peer去run相关动作:【这一步相当重要】

在这个函数里面再去把之前从Service中收集起来的Protocol到p2pServer中的protocol给真正run起来,其实就是调用了 protocol的Run方法【还记的这里面对ProtocolManager的Handle方法做了回调么?在初始化node节点部分有讲】,所以这里才是真正对pm.Handle() 有作用的地方,这样做的目的就是,在初始化的时候先定义了交给远点节点发起回调本节点的方法被内置在了Protocol中,而每当新的远端节点( client 端)和本节点 (Server端)连接时,就会对本节点发起回调。
启动各项服务(启动Service):
这里我们只打算讲启动Ethereum服务部分,因为和tx、Block同步相关的都是写在这里的,先上代码:
func (s *Ethereum) Start(srvr *p2p.Server) error {
// Start the bloom bits servicing goroutines
s.startBloomHandlers()
// Start the RPC service
s.netRPCService = ethapi.NewPublicNetAPI(srvr, s.NetVersion())
// Figure out a max peers count based on the server limits
maxPeers := srvr.MaxPeers
if s.config.LightServ > 0 {
if s.config.LightPeers >= srvr.MaxPeers {
return fmt.Errorf("invalid peer config: light peer count (%d) >= total peer count (%d)", s.config.LightPeers, srvr.MaxPeers)
}
maxPeers -= s.config.LightPeers
}
// Start the networking layer and the light server if requested
s.protocolManager.Start(maxPeers)
if s.lesServer != nil {
s.lesServer.Start(srvr)
}
return nil
}我们可以看出来,其实里面做了,创建一个RPC服务实例、启动pm实例【超重要】、如果需要的话还会启动轻节点服务;其中我们主要讲启动pm实例部分
func (pm *ProtocolManager) Start(maxPeers int) {
pm.maxPeers = maxPeers
// broadcast transactions
pm.txsCh = make(chan core.NewTxsEvent, txChanSize)
pm.txsSub = pm.txpool.SubscribeNewTxsEvent(pm.txsCh)
go pm.txBroadcastLoop()
// broadcast mined blocks
pm.minedBlockSub = pm.eventMux.Subscribe(core.NewMinedBlockEvent{})
go pm.minedBroadcastLoop()
// start sync handlers
go pm.syncer()
go pm.txsyncLoop()
}我们可以看到,里头其实就是先注册了交易监听,挖矿区块监听,然后做了四个协程,分别是单个广播交易、单个广播区块、批量同步区块、批量同步交易等四部分
1、go pm.txBroadcastLoop():
把监听到的交易广播个缓存在本地pm的peerSet中的peer内部的交易队列中,其实就是做了个缓存,并没有发起P2P,而真正做P2P动作,有之前所说的在新节点加入本地时,往本地节点的peerSet做了注册之后起的一个异步协程实时的把这一步缓存在本地的信息发起真正的p2p广播。
2、go pm.minedBroadcastLoop():
道理和真正p2p的时机和上述一样,只是往本地缓存的时候分别往部分peer缓存了block,往全部peer缓存了blockHash。
3、go pm.syncer():
这里面先启动fetcher,而启动fetcher其实是调用了一个fetcher的loop函数这个函数和之前pm的Handle中底层死循环处理的handleMsg函数相辅相成。然后读取 pm.newPeerCh (在 protocol.Run中的manager.newPeerCh <- peer 往里面放值,及每个新加入的peer都会触发)并根据<-pm.newPeerCh有新加入节点时,去判断本地pm.PeerSet中的远端peer实例个数是否 >= 5 或者每10秒钟 触发一次 go pm.synchronise(pm.peers.BestPeer()) 这个函数里面才是使用了 downloader 去同步区块并且会在同步完成后把本地Chain上的最后一个块的hash 广播到其他peer缓存中。
4、go pm.txsyncLoop() :
实时监听本 <-pm.txsyncCh通道 【内容在 pm的Handle函数的 pm.syncTransactions(p) 中被写入】中的txsync然后根据里面的peerId去广播txs。
启动RPC服务及APIS:
根据各项服务,逐个把对应的RPC-API服务启动起来(如 http、ws等等)。
// Lastly start the configured RPC interfaces
if err := n.startRPC(services); err != nil {
for _, service := range services {
service.Stop()
}
running.Stop()
return err
}func (n *Node) startRPC(services map[reflect.Type]Service) error {
// Gather all the possible APIs to surface
apis := n.apis()
for _, service := range services {
apis = append(apis, service.APIs()...)
}
// Start the various API endpoints, terminating all in case of errors
if err := n.startInProc(apis); err != nil {
return err
}
if err := n.startIPC(apis); err != nil {
n.stopInProc()
return err
}
if err := n.startHTTP(n.httpEndpoint, apis, n.config.HTTPModules, n.config.HTTPCors, n.config.HTTPVirtualHosts, n.config.HTTPTimeouts); err != nil {
n.stopIPC()
n.stopInProc()
return err
}
if err := n.startWS(n.wsEndpoint, apis, n.config.WSModules, n.config.WSOrigins, n.config.WSExposeAll); err != nil {
n.stopHTTP()
n.stopIPC()
n.stopInProc()
return err
}
// All API endpoints started successfully
n.rpcAPIs = apis
return nil
}这里面我们可以看到先收集各种服务上的apis然后去启动各种RPC服务。
总结:
1、其实就是先在初始化node中回去做对Protocol的封装并且对每个新加入本地的节点进行对本节点的回调来做到广播交易和区块,而这一步算是一个函数的注册而已,还没有真正调用。
然后在node启动的时候才会发起真正的回调调用,UDP管理了节点发现和Table对象的刷桶动作;
2、TCP负责启动Server端并把每一个和本地Server端连接的conn封装成peer注册到本地且触发之前的handle回调;TCP还做了,根据k-bucket中抽出部分节点去发起连接(这时候本地node相当于TCP client),如果连接失败这根据该peerID做刷桶动作然后再次抽出部分节点发起连接。
3、启动了service 这时候会启动pm去把交易即区块缓存到之前注册在本地的peer中,交由Hnadle那边在注册里面的 异步协程去实时发送P2P广播。并且会启动fetcher 的loop函数和之前Handle回调里面的 handleMsg函数做呼应,一直在后台相辅相成的处理中P2P的信息往来。并启动了Downloader一直在做同步。
4、启动了各种RPC服务,并注册了各类APIS
下面我们开说一说 fetcher和 downloader部分的逻辑:(待续...)
今天写了一天了先写到这里,因为这里面的逻辑又长又一环套一环十分的难梳理,这个文章还没有写完.......