基于爬虫的知识图谱快速构建
基于爬虫的知识图谱快速构建
一、项目目标
1.基于关键词爬取数据
2.通过爬取的数据在Neo4j中构建知识图谱
二、项目实现
(一)基于关键词爬取数据
1.任务分析
目标网站:百度百科
目标数据:关键词以及与关键词相关性较强的词汇
2.实现过程
2.1.爬虫框架
import urllib.request
from bs4 import BeautifulSoup
import os
#os用来创建文件夹
import chardet
url = ‘https://baike.baidu.com/item/’
word=urllib.parse.quote(name)
url=url+word
res = urllib.request.urlopen(url)
content = res.read()
‘’‘print(content)’’’
‘’‘print(res.status_code)’’’
soup = BeautifulSoup(content,‘html.parser’)
‘’‘print(soup)’’’
2.2.网页分析
Para _blank
2.3.通过用户输入获取关键词
name=input(“请输入关键字:”)
2.4.爬取数据
通过前面的步骤可以通过关键词访问相应百度百科词条,并爬取到网页文字段落。
2.5.数据分析
通过深入对网页源代码的分析,我发现段落中与关键词相关性较高的词汇大部分都有独立词条,并且以链接的形式写于源代码之中。
于是我再次对数据进行了筛选获取到了这些词汇,并认为这些词汇就是与关键词相关性较强的词汇
(二)通过爬取的数据在Neo4j中构建知识图谱
1.任务分析
Neo4j可以通过格式化的代码实现知识图谱的建立于可视化通过简单的格式化字符串可以建立基于获取关键词的数据的格式化方法
2.Neo4j语法分析
CREATE (le:Person {name:“Euler”}),(db:Person {name:“Bernoulli”}),
(le)-[:KNOWS {since:1768}]->(db)
RETURN le, db
具体过程分为三部分
创建图谱对象
建立对象关系
返回与可视化
cr=’’‘CREATE (ma:Map{name:"’’’+key+’’’"})’’’
ra =’’
re =‘RETURN ma’
num = 1
for i in list:
m_str=‘a%d’%num
cr=cr+’,(’+m_str+’’’:Map{name:"’’’+i+’’’"})’’’
ra=ra+’,(ma)-[:relate]->(’+m_str+’)’
re=re+’,’+m_str
num+=1
jo=cr+ra+re
print(jo)
return jo
三、项目成果
1.百度数据
‘维克托·迈尔-舍恩伯格’,
‘大数据时代’,
‘抽样调查’,
‘Volume’,
‘Velocity’,
‘Variety’,
‘Value’,
‘Veracity’,
‘MapReduce’,
‘IT管理’
2.Neo4jcode
CREATE (ma:Map{name:“大数据”}),(a1:Map{name:“维克托·迈尔-舍恩伯格”}),(a2:Map{name:“大数据时代”}),(a3:Map{name:“抽样调查”}),(a4:Map{name:“Volume”}),(a5:Map{name:“Velocity”}),(a6:Map{name:“Variety”}),(a7:Map{name:“Value”}),(a8:Map{name:“Veracity”}),(a9:Map{name:“MapReduce”}),(a10:Map{name:“IT管理”}),(ma)-[:relate]->(a1),(ma)-[:relate]->(a2),(ma)-[:relate]->(a3),(ma)-[:relate]->(a4),(ma)-[:relate]->(a5),(ma)-[:relate]->(a6),(ma)-[:relate]->(a7),(ma)-[:relate]->(a8),(ma)-[:relate]->(a9),(ma)-[:relate]->(a10)RETURN ma,a1,a2,a3,a4,a5,a6,a7,a8,a9,a10
3.Neo4j可视化
轻量数据(例:大数据)

大量数据(例:印度)
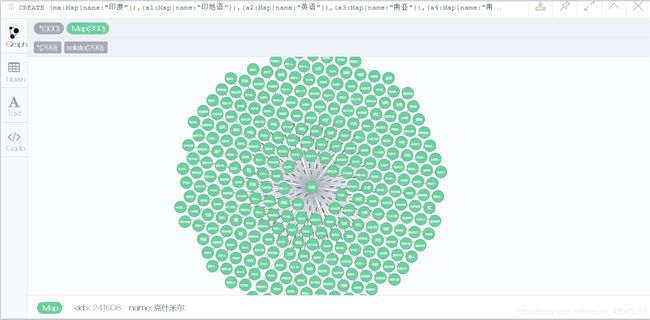
4.源代码
import urllib.request
from bs4 import BeautifulSoup
def GetCreateCode( key, list):
'''example
CREATE (le:Person {name:"Euler"}),(db:Person {name:"Bernoulli"}),
(le)-[:KNOWS {since:1768}]->(db)
RETURN le, db
'''
a = list
num = a.count('\n')
for i in range(num):
a.remove('\n')
for i in range(len(a)):
a[i] = a[i].strip()
num = a.count('')
for i in range(num):
a.remove('')
cr = '''CREATE (ma:Map{name:"''' + key + '''"})'''
ra = ''
re = '\nRETURN ma'
num = 1
for i in a:
m_str = 'a%d' % num
cr = cr + ',(' + m_str + ''':Map{name:"''' + i + '''"})'''
ra = ra + ',(ma)-[:relate]->(' + m_str + ')'
re = re + ',' + m_str
num += 1
jo = cr + ra + re
# print(jo)
return jo
name=input("请输入关键字:")
url = 'https://baike.baidu.com/item/'
word=urllib.parse.quote(name)
# print(url+word,'\n')
url=url+word
res = urllib.request.urlopen(url)
content = res.read()
'''print(content)'''
'''print(res.status_code)'''
soup = BeautifulSoup(content,'html.parser')
'''print(soup)'''
para = soup.find_all('div',class_ = 'para')
#print(para)
data=[]
for i in para:
blank = i.find_all('a',target = '_blank')
for s in blank:
data.append(s.get_text())
code=GetCreateCode(name,data)
print(code)
四、优化
以上代码可以直接实现任务功能但存在复用难度大、功能单一的问题,所以我对实现过程进行模块化创建了一个类库,用于实现模块化的应用,具体功能如下:
百度相关
- 实例 = BTN(关键词) 即可完成百科对象读取
- 实例.ReadToFile(filepath,filename) #将网页源代码写在指定路径的 文件名.txt 文件中
示例 : a.ReadToFile(‘E:/编程项目/py’,filename) - 实例.SaveToFile(self,filepath,filename,data) #将数据写入文件是功能2的拓展
- 实例.GetPara(self) 返回源代码中的 para(段落)类数据
- 实例.GetBlanksFromPara(self) 返回源代码中 para类数据中的 blank类数据
- 获取关键数据GetNames()
Neo4j相关
1.通过关键词直接生成Neo4j代码GetDataFromName(self,name)
2.通过文件生成Neo4j代码GetDataFromFile(self,m_filename)
通过类库可以通过控制台快速获取代码
from BaikeToNeo4j import ZJC_Neo4j as ne
a=ne()
a.GetDataFromFile(‘data/大数据1.txt’)//从文件
a.GetDataFromName(‘大数据’)//从关键字
等等。。。
import urllib.request
from bs4 import BeautifulSoup
import os
#os用来创建文件夹
import chardet
'''
class classname:
'类的帮助信息' 可以通过classname._doc_查看
class_suite 类体(成员、方法、数据)
'''
class ZJC_Baike():
'''
1. 实例 = BTN(关键词) 即可完成百科对象读取
2. 实例.ReadToFile(filepath,filename) #将网页源代码写在指定路径的 文件名.txt 文件中
示例 : a.ReadToFile('E:/编程项目/py',filename)
3. 实例.SaveToFile(self,filepath,filename,data) #将数据写入文件是功能2的拓展
4. 实例.GetPara(self) 返回源代码中的 para(段落)类数据
5. 实例.GetBlanksFromPara(self) 返回源代码中 para类数据中的 blank类数据
6. 获取关键数据GetNames()
'''
url = 'https://baike.baidu.com/item/' #百科的前缀网址
#m_url = [] #存储相关兴趣链接
#m_data = [] #存储相关数据
content=[] #存储网页源代码
def ReadToFile(self,filepath,filename):
m_fname=filepath+'/'+filename+'.txt'
m_fdata=open(m_fname,'a+',encoding='utf-8')
m_fdata.write(self.content)
m_fdata.close()
def SaveToFile(self,filepath,filename,data):
m_fname=filepath+'/'+filename+'.txt'
m_fdata=open(m_fname,'a+',encoding='utf-8')
m_fdata.write(data)
m_fdata.close()
def GetPara(self):
soup = BeautifulSoup(self.content, 'html.parser')
para = soup.find_all('div',class_='para')
return para
def GetBlanksFromPara(self,para):
blanks=[]
for i in para:
blank = i.find_all('a', target='_blank')
blanks.append(blank)
return blanks
def GetBlanksFromPara(self):
blanks=[]
para = self.GetPara()
for i in para:
#print(i)
blank = i.find_all('a', target='_blank')
blanks.append(blank)
return blanks
def __init__(self,name):
self.name=name
word = urllib.parse.quote(name)
# print(url+word,'\n')
url = self.url + word
print(url)
res = urllib.request.urlopen(url)
#print(res)
self.content=res.read()
print(self.content)
#print(res.)
def GetNames(self):
blank = self.GetBlanksFromPara()
m_data = []
for i in blank:
for j in i:
text=j.get_text()
if(text== '\n\n'):
continue
m_data.append(text)
return m_data
class ZJC_Neo4j():
'''
1.通过关键词直接生成Neo4j代码GetDataFromName(self,name)
2.通过文件生成Neo4j代码GetDataFromFile(self,m_filename)
'''
def GetDataFromName(self,name):
m_cbd=ZJC_Baike(name)
return m_cbd.GetNames()
def GetDataFromFile(self,m_filename):
file = open(m_filename,'r',encoding='utf-8')
a=file.readlines()
num=a.count('\n')
for i in range(num):
a.remove('\n')
for i in range (len(a)):
a[i]=a[i].rstrip()
#返回一个字符串末尾的char字符删除不·在字符串中直接操作
return a
def GetCreateCode(self,key,list):
'''example
CREATE (le:Person {name:"Euler"}),(db:Person {name:"Bernoulli"}),
(le)-[:KNOWS {since:1768}]->(db)
RETURN le, db
'''
a=list
num = a.count('\n')
for i in range(num):
a.remove('\n')
for i in range(len(a)):
a[i] = a[i].strip()
num = a.count('')
for i in range(num):
a.remove('')
cr='''CREATE (ma:Map{name:"'''+key+'''"})'''
ra =''
re ='\nRETURN ma'
num = 1
for i in list:
m_str='a%d'%num
cr=cr+',('+m_str+''':Map{name:"'''+i+'''"})'''
ra=ra+',(ma)-[:relate]->('+m_str+')'
re=re+','+m_str
num+=1
jo=cr+ra+re
#print(jo)
return jo