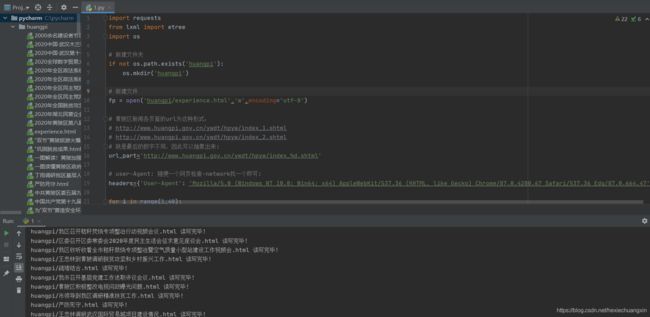
Python爬虫爬取:武汉市黄陂区人民政府中的黄陂要闻页面
首先声明:爬取的内容为公开信息
我们先看一下页面:
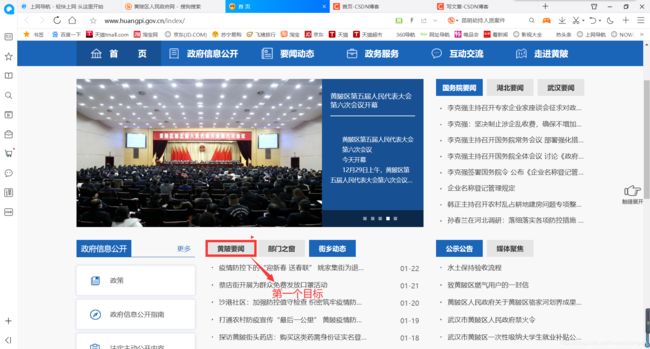
点击黄陂要闻,进入另一个页面:
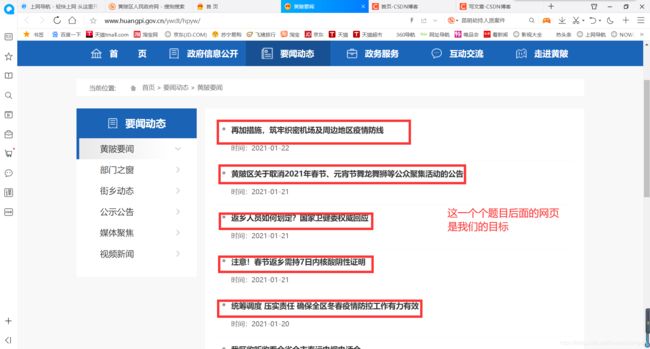
先简要分析一下:
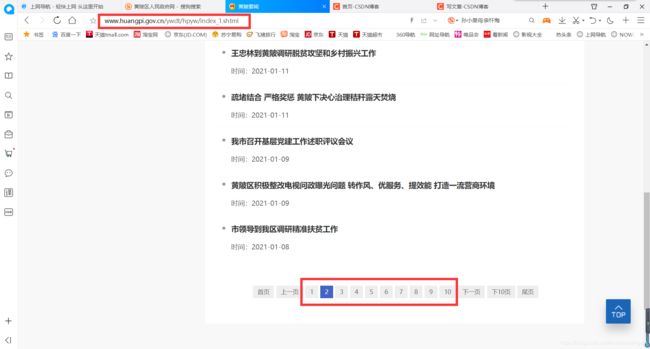
这个新闻页面有好多页,实际上不只图中显示的10页,而是有40多页。每一页的网址格式相似,每张页面里面的主要内容在 < a > 标签里面。如图:
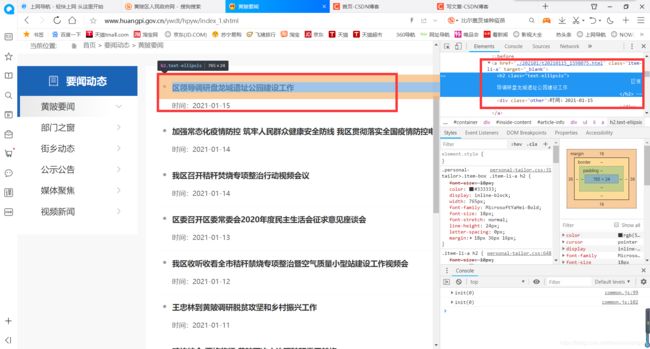
我们使用xpath方法提取出来就行,再对< a >标签中的地址进行请求数据。
完整代码如下:
import requests
from lxml import etree
import os
# 新建文件夹
if not os.path.exists('huangpi'):
os.mkdir('huangpi')
# 黄陂区新闻各页面的url为这种形式:
# http://www.huangpi.gov.cn/ywdt/hpyw/index_1.shtml
# http://www.huangpi.gov.cn/ywdt/hpyw/index_2.shtml
# 就是最后的数字不同,因此可以抽象出来:
url_part='http://www.huangpi.gov.cn/ywdt/hpyw/index_%d.shtml'
# user-Agent: 随便一个网页检查-network找一个即可:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
for i in range(1,40):
url=format(url_part%i) # 组合为一个完整的url
response=requests.get(url=url,headers=headers,proxies={
"https":"115.207.226.40:9999"}) #添加代理ip
response.encoding='utf-8' # 进行'utf-8'编码,或者出来是乱码
html_data=response.text # 响应的文本数据
tree=etree.HTML(html_data) # 用网页数据实例化etree对象
li_list=tree.xpath('//div[@class="personal-tailor"]/ul/li') # 提取新闻页中的li标签
for li in li_list: # 遍历li标签
href=li.xpath('./a/@href')[0] # 从li标签中提取href属性
title='huangpi/'+li.xpath('./a/h2/text()')[0].split()[0]+'.html' # 从li标签中提取新闻题目并改为完整路径
detail_url='http://www.huangpi.gov.cn/ywdt/hpyw/'+href[1:] # href中的网址并不完整,这里变完整
response2 = requests.get(url=detail_url, headers=headers, proxies={
"https": "115.207.226.40:9999"})
response2.encoding = 'utf-8'
html = response2.text
with open(title, 'w',encoding='utf-8') as fp: # 持久化存储
fp.write(html)
print(title, '读写完毕!')
print('全部读写完毕!')
运行效果: