Paddle目标检测作业三——YOLO系列模型实战
作者:xiaoli1368
日期:2020/09/26
邮箱:[email protected]
前言
本文是在学习《百度AIStudio_目标检测7日打卡营》并完成作业三的笔记,主要总结了YOLO系列模型实战中遇到的各种坑以及个人思考。
课程链接:
-
目标检测7日打卡营
-
作业三:YOLO系列模型实战
要求:基于PaddleDetection中的YOLO系列算法,完成印刷电路板(PCB)瑕疵数据集的训练与评估任务。要求在验证集上采用IoU=0.5,area=all的mAP作为评价指标,得分=mAP * 100,范围[0,100],分数越高模型效果越好,及格线是60分。鼓励大家使用GPU训练,CPU训练的结果不纳入排行榜。
文章目录
-
- 前言
- Baseline的运行
- 可调参数总结
- 锚框聚类的分析
- 学习率与迭代次数分析
- Backbone分析
- 其它优化
- 各种bug
Baseline的运行
直接运行baseline版本的notebook:
# 解压数据集和PaddleDetection源码
!tar -xf data/data52914/PCB_DATASET.tar -C ~/work/
!tar -xf data/data52899/PaddleDetection.tar -C ~/work/
# 安装所需的环境
%cd ~/work/PaddleDetection
!pip install -r requirements.txt
!pip install pycocotools
# 开始训练
!python -u tools/train.py -c ../yolov3_darknet_baseline.yml --eval --use_vdl=true --vdl_log_dir=vdl_dir/scalar
结果如下,可以发现mAP只有0.42(第二行末尾):
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.129
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.420
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.029
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.322
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.141
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.014
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.064
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.246
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.249
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.375
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.268
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.014
terminate called without an active exception
关于上述结果中相关指标的讨论,可以参考链接:https://github.com/matterport/Mask_RCNN/issues/663
可调参数总结
当前可以调整的参数主要包括:
- 最大训练轮数(max_iters)
- 学习率(LearningRate)相关参数,包括base_lr和milestones
- 聚类锚框的size
- backbone
- 网络中其它参数
初始参数如下:
- max_iters: 2669
- num_classes: 6
- base_lr: 0.00025
- milestones: [1779, 2372]
锚框聚类的分析
1.为什么要手工设置聚类锚框
因为根据YOLO3的原理可知,如果预先设定的Anchor大小适配当前数据集,可大幅提升mAP。
2.如何实现锚框聚类
这里paddleDetection直接给出了python脚本工具,路径为:PaddleDetection\tools\anchor_cluster.py,说明链接如下:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/tutorials/Custom_DataSet.md#3%E7%94%9F%E6%88%90anchor,其中调用命令为:
python tools/anchor_cluster.py -c configs/ppyolo/ppyolo.yml -n 9 -s 608 -m v2 -i 1000
3.如何选取参数
参数表如下:
| 参数 | 用途 | 默认值 | 备注 |
|---|---|---|---|
| -c/–config | 模型的配置文件 | 无默认值 | 必须指定 |
| -n/–n | 聚类的簇数 | 9 | Anchor的数目 |
| -s/–size | 图片的输入尺寸 | None | 若指定,则使用指定的尺寸,如果不指定, 则尝试从配置文件中读取图片尺寸 |
| -m/–method | 使用的Anchor聚类方法 | v2 | 目前只支持yolov2/v5的聚类算法 |
| -i/–iters | kmeans聚类算法的迭代次数 | 1000 | kmeans算法收敛或者达到迭代次数后终止 |
| -gi/–gen_iters | 遗传算法的迭代次数 | 1000 | 该参数只用于yolov5的Anchor聚类算法 |
| -t/–thresh | Anchor尺度的阈值 | 0.25 | 该参数只用于yolov5的Anchor聚类算法 |
4.关于-s参数
可以直接使用各个参数的默认值来运行,即:
python tools/anchor_cluster.py -c configs/ppyolo/ppyolo.yml -n 9 -s 608 -m v2 -i 1000
但是在这里我对-s参数产生了疑问,并且在阅读源代码后我想当然地认为·-s·应该选择图片的真实大小(然而并非如此),源码片段如下:
# anchor_cluster.py line:307
parser.add_argument(
'--size',
'-s',
default=None,
type=str,
help='image size: w,h, using comma as delimiter')
这里我先使用了真实图片的size作为-s参数,即[3056, 2464],输出的9种锚框大小为:
2020-09-24 23:51:56,730-INFO: 9 anchor cluster result: [w, h]
2020-09-24 23:51:56,730-INFO: [39, 54]
2020-09-24 23:51:56,730-INFO: [65, 58]
2020-09-24 23:51:56,730-INFO: [51, 87]
2020-09-24 23:51:56,730-INFO: [104, 54]
2020-09-24 23:51:56,730-INFO: [80, 80]
2020-09-24 23:51:56,730-INFO: [61, 127]
2020-09-24 23:51:56,730-INFO: [148, 68]
2020-09-24 23:51:56,730-INFO: [110, 109]
2020-09-24 23:51:56,730-INFO: [179, 145]
并且可以通过对比真实图片标注中的bbox大小,来粗略分析聚类锚框是否正确,以下是在PaddleDetection/dataset/PCB_DATASET/Annotations/val.json中的三个样本:
"bbox": [1693, 238, 28, 35]
"bbox": [1236, 716, 84, 92]
"bbox": [1529, 1077, 124, 124]
结果显示好像聚类出的9种聚类后的anchor基本上覆盖了数据集中的不同大小的bbox,于是直接在yml文件中仅修改anchor后,进行训练,然而得到了较差的结果(基本上位于0.3-0.4之间)
5.正确的锚框
这里通过阅读源码,大体上了解了锚框聚类的原理,以及-s参数的选择,源码位于:PaddleDetection/tools/anchor_cluster.py中,锚框聚类的基本流程如下:
- 使用ArgsParser处理命令行参数,后续进行合理性检测
- 根据参数配置,决定调用YOLOv2AnchorCluster或者YOLOv5AnchorCluster
- 注意这两个class都继承自BaseAnchorCluster,其中有两个核心参数
- self.shape(记录了数据集图片的真实size构成的list,如[[3056, 2464], …)
- self.whs(记录了数据集标注bbox的hw构成的list,如[0.01930628 0.0275974], …[,注意已经归一化到[0, 1])
- 而命令行中输入的
-s参数被保存为了self.size - 后续的核心聚类函数为
calc_anchors- 其中首先进行的操作就是:
self.whs = self.whs * np.array([self.size]) - 因此通过whs归一化然后再次放大这样的一个过程,真实标注的bbox的hw可以等比例对应到输入size为604的图片上
- 其中首先进行的操作就是:
因此,-s参数给定的图片size指的是锚框真正作用到的图片尺寸,而非真实的数据集图片尺寸,由YOLO原理可知,原始图片会存在resize的过程,并且在yml文件中的批处理转换也制定了大小:
batch_transforms:
- !RandomShape
sizes: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608]
因此这里在生成聚类锚框时-s参数保持baseline中的608才是正确的,此时的锚框大小:
2020-09-25 16:09:24,820-INFO: 9 anchor cluster result: [w, h]
2020-09-25 16:09:24,820-INFO: [8, 13]
2020-09-25 16:09:24,820-INFO: [14, 14]
2020-09-25 16:09:24,820-INFO: [10, 21]
2020-09-25 16:09:24,821-INFO: [16, 19]
2020-09-25 16:09:24,821-INFO: [24, 13]
2020-09-25 16:09:24,821-INFO: [12, 31]
2020-09-25 16:09:24,821-INFO: [28, 19]
2020-09-25 16:09:24,821-INFO: [21, 27]
2020-09-25 16:09:24,821-INFO: [36, 36]
使用了正确的锚框后的训练结果:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.065
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.261
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.009
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.246
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.073
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.014
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.037
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.146
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.149
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.325
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.158
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.024
什么情况!mAP只有0.261,此时分析可能的原因有两个:
- 首先,可能时训练次数过少,只有36个epochs,还没有达到最优性能
- 其次,其它参数的设置不合理导致训练效果较差
- 设定锚框中size表示了输入图片的size,这里选择了只能是608,但是yml文件中batck_size存在可随机选择的多个值,这里存在不匹配
6.修改batch_transforms_size
关于学习率以及epoch的修改见下一节,这里查看yml配置文件中关于train的输入图片经过batch_transforms尺寸如下:
batch_transforms:
- !RandomShape
sizes: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608]
因为考虑到size里设置了多个值,因此每次进行批归一化时会随机采取不同的规格的图片,这里可能因为与锚框聚类中的size=608不对应,从而导致mAP下降,因此这里修改为size为单一值608,其它保持不变,训练结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.076
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.327
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.009
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.052
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.082
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.024
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.037
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.181
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.181
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.062
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.194
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.024
可以发现结果略有提升(0.327)但是比起baseline仍有不足,分析可能是迭代次数的问题,或者其它配置不当(后文中指出了)。注意到loss和mAP的曲线图如下:


可以发现结果的曲线图中存在上涨的趋势,因此有必要增大迭代次数了,只是修改锚框已经无法继续优化得到更好的效果。
关于锚框聚类的一些参考链接:
- https://www.cnblogs.com/sdu20112013/p/10937717.html
- https://www.cnblogs.com/sdu20112013/p/10937717.html
- https://www.paddlepaddle.org.cn/searchdoc?q=anchor+cluster&language=zh
- https://blog.csdn.net/weixin_38145317/article/details/90371826
- https://blog.csdn.net/fanzonghao/article/details/102466969
- https://blog.csdn.net/cc__cc__/article/details/104255184?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
学习率与迭代次数分析
首先需要说明深度学习训练中各个参数的含义:
- epoch:纪元数,每经过一个epochs所有的训练集数据都在网络中计算了一遍
- batch_size:批尺寸,由于无法一次性把所有的训练集同时输入网络训练,所以需要分批训练,每批数据样本的个数即为batch_size,配置文件中batch_size=8表示每个取8个训练集图片开始训练
- max_iters:最大训练轮数,每经过一轮iter,就会取batch_size个样本进行训练(配置文件中需要设定)
训练轮数与Epoch转换关系:
- 当输入图片尺寸和批尺寸已知时,二者可以互相转换
- 例如batch_size=8,训练集数量为593,如果要要在单卡GUP上训练36个Epoch,那么max_iters=593x36/8=2669。(因此当max_iters = 2669时,训练了36epochs,如果希望增大训练epochs,则按比例增加max_iters即可)
- 如果想让模型收敛的更好,可以继续增大max_iters,训练2x、3x等模型,但并不是意味着训练轮数越多效果越好,要防止过拟合的出现。
关于学习率:
- 如果GPU卡数变化,依据lr,batch-size关系调整lr: 学习率调整策略
- 学习率的milestones(学习率变化界限)一般与max_iters存在比例关系,一般在总max_iters数的2/3和8/9处进行学习率的调整
- 为保证模型正常训练不出Nan,学习率要根据GPU卡数,batch size变换而做线性变换,比如这里我们将GPU卡数8->1,所以base_lr除以8即可;(这里也可以为了收敛更快,base_lr除以了4)
关于warmup
- 学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种。
- Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
- 由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
最终这里修改的参数为:(baseline的5x)
- max_iters:13345
- snapshot_iter: 500
- base_lr: 0.005(后来改为0.0005,因为学习率太高可能会出现nan的问题)
- milestones: [8895, 11868](后来改为[6000,7000,8000,9000,11000],每次衰减0.5)
结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.089
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.363
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.009
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.057
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.093
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.076
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.046
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.201
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.203
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.062
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.211
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.100
2020-09-25 21:30:55,898-INFO: Best test box ap: 0.10780619463253305, in iter: 7500
2020-09-25 21:31:03,813-INFO: iter: 11520, lr: 0.000050, 'loss': '12.072128', time: 1.004, eta: 0:30:32
2020-09-25 21:31:13,293-INFO: iter: 11540, lr: 0.000050, 'loss': '11.530693', time: 0.466, eta: 0:14:01
2020-09-25 21:31:24,015-INFO: iter: 11560, lr: 0.000050, 'loss': '12.216623', time: 0.535, eta: 0:15:54
2020-09-25 21:31:34,893-INFO: iter: 11580, lr: 0.000050, 'loss': '11.752309', time: 0.545, eta: 0:16:01
2020-09-25 21:31:42,293-INFO: iter: 11600, lr: 0.000050, 'loss': '11.906868', time: 0.371, eta: 0:10:46
2020-09-25 21:31:53,294-INFO: iter: 11620, lr: 0.000050, 'loss': '11.948734', time: 0.549, eta: 0:15:47
2020-09-25 21:32:04,393-INFO: iter: 11640, lr: 0.000050, 'loss': '11.716547', time: 0.555, eta: 0:15:46
2020-09-25 21:32:14,507-INFO: iter: 11660, lr: 0.000050, 'loss': '11.431315', time: 0.511, eta: 0:14:20
2020-09-25 21:32:22,494-INFO: iter: 11680, lr: 0.000050, 'loss': '11.785230', time: 0.394, eta: 0:10:56
2020-09-25 21:32:32,793-INFO: iter: 11700, lr: 0.000050, 'loss': '11.856794', time: 0.520, eta: 0:14:15
2020-09-25 21:32:43,200-INFO: iter: 11720, lr: 0.000050, 'loss': '11.957197', time: 0.516, eta: 0:13:58
2020-09-25 21:32:52,262-INFO: iter: 11740, lr: 0.000050, 'loss': '11.558689', time: 0.461, eta: 0:12:19
可以发现,训练中的mAP并不高,只有0.36,后续不断在0.4-0.3之间徘徊。然而使用eval.py脚本直接对最优模型的路径检测发现结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.260
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.735
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.093
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.164
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.267
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.194
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.095
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.363
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.363
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.163
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.365
达到了0.735,什么情况!为什么之前训练中eval结果就只有0.36?其实这里是另外一个配置导致的,就是yml文件中测试部分evalTest中的batch_transforms_size也需要改为608,否则会导致eval的结果不是正确的结果。
最终修改正确后的log如下:
INFO: iter: 5000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.660
INFO: iter: 5500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.676
INFO: iter: 6000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.700
INFO: iter: 6500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.727
INFO: iter: 7000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.717
INFO: iter: 7500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.729
INFO: iter: 8000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.732
INFO: iter: 8500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.730
INFO: iter: 9000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.728
INFO: iter: 9500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.729
INFO: iter: 10000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.733
INFO: iter: 10500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.731
INFO: iter: 11000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.732
INFO: iter: 11500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.730
INFO: iter: 12000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.732
INFO: iter: 12500 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.732
INFO: iter: 13000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.731
INFO: iter: 13340 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.730
过程曲线如下:
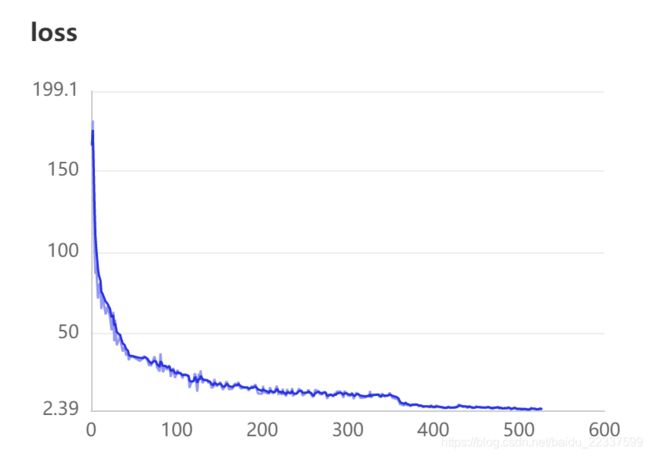

可以发现,随着学习率逐渐趋近于0,loss逐渐趋于稳定,曲线开始收敛,说明网络此时已经无法进一步深入学习,到达了极限,继续增大迭代次数已经没有作用。
参考链接:
- https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/FAQ.md
Backbone分析
通过下图中可以发现,对于backbone使用ResNet50要比DarNet53更优:

因此这对backbone进行调优时,可以选择resnet系列的配置。PaddlePaddle给出了resnet的模型库,这里可以选择的参考配置包括:
- yolov3_mobilenet_v1.md的config文件
- RCNN系列模型参数配置教程,中间涉及到了resnet的config
- yolov3_r50vd_dcn_db_iouaware_obj365_pretrained_coco.yml
- ppyolo.yml
这里选用了ppyolo作为尝试,参考ppyolo.yml来修改baseline.yml,其中迭代次数和学习率修改为:
- max_iters:10676
- snapshot_iter: 500
- base_lr: 0.0025
- milestones: [7117, 9489](后来改为[6000,7000,8000,9000,11000],每次衰减0.5)
结果如下:
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.767
其它优化
本文中提到的优化方式仅包括最为基本的三种方式:
- 聚类锚框(包括batch_transforms_size)
- 学习率与迭代次数
- backbone
最终取得的效果只能说差强人意,如果继续深入的优化,有机会达到0.9+的结果,可行的优化方向包括:
- 调整更优的学习率
- 更加契合的resnet参数配置
- yolo的核心配置(如nms的阈值等待)
各种bug
以下是实际炼丹中遇到的各种bug,记录如下:
- 直接在
baseline.yml中添加resnet配置,报错,无法读取文件,应该是编码问题,可以参考以该文章 - 运行报错,提示feature_map参数冗余,最终选择把feature_map注释掉,才可以正常运行(但是这里暂不明确feature_map的功能,后续待补充)
- 训练中eval的结果很低,但是最终使用eval脚本结果还不错,这是由于eval的batch_transform_szie不对应,导致eval的结果较低
- 出现nan参数值,将学习率调小后解决。报错Log如下:
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/lib/function_base.py:3405: RuntimeWarning: Invalid value encountered in median r = func(a, **kwargs) 2020-09-25 19:47:53,796-INFO: iter: 680, lr: 0.005000, 'loss': 'nan', time: 0.487, eta: 1:42:42 2020-09-25 19:48:03,502-INFO: iter: 700, lr: 0.005000, 'loss': 'nan', time: 0.484, eta: 1:42:04 2020-09-25 19:48:12,448-INFO: iter: 720, lr: 0.005000, 'loss': 'nan', time: 0.456, eta: 1:35:51 2020-09-25 19:48:22,293-INFO: iter: 740, lr: 0.005000, 'loss': 'nan', time: 0.479, eta: 1:40:41 2020-09-25 19:48:32,393-INFO: iter: 760, lr: 0.005000, 'loss': 'nan', time: 0.509, eta: 1:46:49 2020-09-25 19:48:42,602-INFO: iter: 780, lr: 0.005000, 'loss': 'nan', time: 0.515, eta: 1:47:51 2020-09-25 19:48:51,305-INFO: iter: 800, lr: 0.005000, 'loss': 'nan', time: 0.435, eta: 1:30:56 2020-09-25 19:49:01,593-INFO: iter: 820, lr: 0.005000, 'loss': 'nan', time: 0.510, eta: 1:46:27 2020-09-25 19:49:11,693-INFO: iter: 840, lr: 0.005000, 'loss': 'nan', time: 0.505, eta: 1:45:15 2020-09-25 19:49:21,346-INFO: iter: 860, lr: 0.005000, 'loss': 'nan', time: 0.486, eta: 1:41:09 2020-09-25 19:49:29,493-INFO: iter: 880, lr: 0.005000, 'loss': 'nan', time: 0.409, eta: 1:24:57 2020-09-25 19:49:39,193-INFO: iter: 900, lr: 0.005000, 'loss': 'nan', time: 0.485, eta: 1:40:34 loading annotations into memory... Done (t=0.02s) creating index... index created! 2020-09-25 19:46:26,924-WARNING: The number of valid bbox detected is zero. Please use reasonable model and check input data. stop eval!