吴恩达机器学习支持向量机的MATLAB实现(对应ex6练习)
前言:本章作业有两个实现,一个是分类问题,有点类似于之前做过的分类,但是不同在这里是使用SVM实现。对于SVM的思想配套视频已经讲的比较清楚了,在练习中也是直接给出了关键代码,我们需要实现的只是部分。另一个是垃圾邮件的分类,也是使用SVM实现,这部分自己敲的内容很少。总之,本节很多关键代码吴恩达都直接给出,需要自己动手实现的都不难,重点是阅读这些核心代码。
gaussianKernel.m
这里先给出高斯核计算的公式,在MATLAB中实现只需要将数据带入公式即可,没有任何技巧性可言。
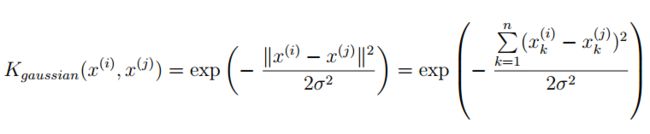
MATLAB中代码体现如下:
function sim = gaussianKernel(x1, x2, sigma)
%RBFKERNEL returns a radial basis function kernel between x1 and x2
% sim = gaussianKernel(x1, x2) returns a gaussian kernel between x1 and x2
% and returns the value in sim
% Ensure that x1 and x2 are column vectors
x1 = x1(:); x2 = x2(:);%将行向量转换为列向量
% You need to return the following variables correctly.
sim = 0;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the similarity between x1
% and x2 computed using a Gaussian kernel with bandwidth
% sigma
%
%直接套用高斯核的公式
sim = exp(-sum((x1 - x2) .* (x1 - x2)) / (2 * sigma * sigma));
% =============================================================
enddataset3Params.m
在使用高斯核训练时有两个关键的参数:C和σ。在这部分,通过使用枚举的方法并结合交叉验证集合选择出最合适的C值和σ值。此间提供的枚举集合为eg = [0.01; 0.03; 0.1; 0.3; 1; 3; 10; 30]。C和σ的值在这个集合中不同组合有8²=64种,最后选择这64种的最优搭配。
function [C, sigma] = dataset3Params(X, y, Xval, yval)
%DATASET3PARAMS returns your choice of C and sigma for Part 3 of the exercise
%where you select the optimal (C, sigma) learning parameters to use for SVM
%with RBF kernel
% [C, sigma] = DATASET3PARAMS(X, y, Xval, yval) returns your choice of C and
% sigma. You should complete this function to return the optimal C and
% sigma based on a cross-validation set.
%
% You need to return the following variables correctly.
C = 1;
sigma = 0.3;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the optimal C and sigma
% learning parameters found using the cross validation set.
% You can use svmPredict to predict the labels on the cross
% validation set. For example,
% predictions = svmPredict(model, Xval);
% will return the predictions on the cross validation set.
%
% Note: You can compute the prediction error using
% mean(double(predictions ~= yval))
%
eg = [0.01; 0.03; 0.1; 0.3; 1; 3; 10; 30];
error = 1;
for i = 1 : size(eg,1);
for j = 1 : size(eg,1);
model = svmTrain(X,y,eg(i),@(x1, x2) gaussianKernel(x1, x2, eg(j)));
predictions = svmPredict(model, Xval);% returns a vector of predictions using a trained SVM model
tempErr = mean(double(predictions ~= yval));%预测值与真实值相同则为0,否则为1
if tempErr < error;
error = tempErr;
C = eg(i);
sigma = eg(j);
end
end
end
% =========================================================================
endprocessEmail.m
这部分主要是对邮件的内容进行处理,需要有正则表达式的基础知识。整个函数的思路还是比较清楚的,通过将一封邮件中的每个单词与词汇表中的单词作比较,如果邮件中的单词存在于词汇表中,则将该单词用词汇的序号代替,否则不用管。下面给出核心代码。
for i = 1 : length(vocabList);
if strcmp(str,vocabList{i});
word_indices = [word_indices;i];
end
end
emailFeatures.m
这部分是为一封邮件产生一个特征向量,向量的维数是n*1,其中n为词汇表的单词数目(1899)。如果邮件中的单词在词汇表中有出现那么将特征向量中对应的位置设为1,否则为0.这里这样做得目的是为了在进行数据训练时便于找出垃圾邮件中常包含的单词和之后进行邮件的分类。
function x = emailFeatures(word_indices)
%EMAILFEATURES takes in a word_indices vector and produces a feature vector
%from the word indices
% x = EMAILFEATURES(word_indices) takes in a word_indices vector and
% produces a feature vector from the word indices.
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);%生成一个n行1列的矩阵
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return a feature vector for the
% given email (word_indices). To help make it easier to
% process the emails, we have have already pre-processed each
% email and converted each word in the email into an index in
% a fixed dictionary (of 1899 words). The variable
% word_indices contains the list of indices of the words
% which occur in one email.
%
% Concretely, if an email has the text:
%
% The quick brown fox jumped over the lazy dog.
%
% Then, the word_indices vector for this text might look
% like:
%
% 60 100 33 44 10 53 60 58 5
%
% where, we have mapped each word onto a number, for example:
%
% the -- 60
% quick -- 100
% ...
%
% (note: the above numbers are just an example and are not the
% actual mappings).
%
% Your task is take one such word_indices vector and construct
% a binary feature vector that indicates whether a particular
% word occurs in the email. That is, x(i) = 1 when word i
% is present in the email. Concretely, if the word 'the' (say,
% index 60) appears in the email, then x(60) = 1. The feature
% vector should look like:
%
% x = [ 0 0 0 0 1 0 0 0 ... 0 0 0 0 1 ... 0 0 0 1 0 ..];
%
%
for i = 1 : length(word_indices);
x(word_indices(i)) = 1;
end
% =========================================================================
end