论文阅读笔记(4)——《Language Generation with Multi-Hop Reasoning on Commonsense Knowledge Graph》
基于常识知识图的多跳推理语言生成
-
- 1 Abstract & Introduction
- 2 Related Work
-
- 2.1 Commonsense-Aware Neural Text Generation(常识感知神经文本生成)
- 2.2 Multi-Hop Reasoning on Graph Structure(图结构的多跳推理)
- 3 Methodology
-
- 3.1 Problem Formulation
- 3.2 Generation with Multi-Hop Reasoning Flow(多跳推理流程生成)
-
- 3.2.1 Static Multi-Relational Graph Encoding(静态多关系图编码)
- 3.2.2 Context Modeling with Pre-Trained Transformer(用预先训练好的Transformer进行上下文建模)
- 3.2.3 Dynamic Multi-Hop Reasoning Flow(动态多跳推理流程)
- 3.2.4 Generation Distribution with Gate Control(带门控制的生成分配)
- 3.3 Training and Inference(训练与推论)
- 4 Experiments
-
- 4.1 Datasets and Metrics
- 4.2 Extracting Sub-Graphs as Knowledge Grounding(提取子图作为知识基础)
- 4.3 Implementation Details
- 4.4 Compared Baselines
- 4.5 Automatic Evaluation
- 4.6 Human Evaluation
- 4.7 Ablation Study(消融研究)
- 4.8 Impact of the Size of Training Data(培训数据大小的影响)
- 4.9 Effectiveness of Dynamic Multi-Hop Reasoning(动态多跳推理的有效性)
- 5 Conclusion
1 Abstract & Introduction
本文是 结合常识知识 的文本生成领域的研究。利用知识图谱的结构和语义信息可促进常识性文本生成。在本文中,作者提出了使用 多跳推理流程(GRF) 进行生成的方法,该方法可以在从外部常识知识图谱中提取的多关系路径上启用带有动态多跳推理的预训练模型。实验结果表明在需要推理常识性知识的三个文本生成任务上:故事结尾生成(Mostafazadeh et al., 2016)、溯因自然语言生成(Bhagavatula et al., 2020)和意义生成的解释生成(Wang et al., 2019),本文提出的模型优于现有基准模型。同时,通过模型推断出的推理路径为文本生成提供了可解释性。
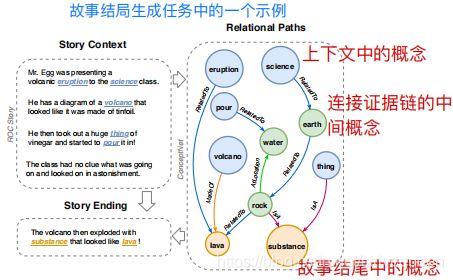
2 Related Work
2.1 Commonsense-Aware Neural Text Generation(常识感知神经文本生成)
2.2 Multi-Hop Reasoning on Graph Structure(图结构的多跳推理)
3 Methodology
3.1 Problem Formulation
关注文本生成任务,其中推理的外部常识知识是必需的。不失一般性,输入源 是一个文本序列x = (x1, x2,···xN),可能由几个句子组成。输出目标 是另一个文本序列y = (y1, y2,···,yM)。为便于推理过程,借助于外部常识知识图G = (V, E) ,其中V表示概念集 ,E表示概念之间的关系。
提取一个子图G = (V, E) 和给定的输入文本 V ⊂ V \mathrm V \subset \mathcal{V} V⊂V和 E ⊂ E E \subset \mathcal{E} E⊂E。
子图由相互连接的从从输入文本中开始的源概念Cx提取的H-hop路径。我们只考虑1-gram表面文本的概念。然后制定任务生成最佳假设yˆ以下哪一个条件概率最大化:
y ^ = argmax y P ( y ∣ x , G ) \hat{\boldsymbol{y}}=\operatorname{argmax}_{\boldsymbol{y}} P(\boldsymbol{y} \mid \boldsymbol{x}, G) y^=argmaxyP(y∣x,G)
3.2 Generation with Multi-Hop Reasoning Flow(多跳推理流程生成)
3.2.1 Static Multi-Relational Graph Encoding(静态多关系图编码)
图神经网络(GNN)框架,如图卷积网络(GCN) (Kipf和Welling, 2017)和graph attention network(GAT) (Velickovic et al., 2018)的研究表明,通过聚合来自本地邻居的节点信息,可以有效地编码图结构数据。
使用非参数合成操作 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)将节点嵌入和关系嵌入结合起来。
给定输入图G = (V,E)和一个GCN的LG层,对于每个节点 v ∈ V v \in V v∈V,我们通过聚合其局部邻居 N ( v ) \mathcal{N}(v) N(v)的信息来更新在l + 1层嵌入的节点,这些邻居包括对节点u和连接关系r。
o v l = 1 ∣ N ( v ) ∣ ∑ ( u , r ) ∈ N ( v ) W N l ϕ ( h u l , h r l ) h v l + 1 = ReLU ( o v l + W S l h v l ) \begin{aligned} \boldsymbol{o}_{v}^{l} &=\frac{1}{|\mathcal{N}(v)|} \sum_{(u, r) \in \mathcal{N}(v)} \mathbf{W}_{N}^{l} \phi\left(\boldsymbol{h}_{u}^{l}, \boldsymbol{h}_{r}^{l}\right) \\ \boldsymbol{h}_{v}^{l+1} &=\operatorname{ReLU}\left(\boldsymbol{o}_{v}^{l}+\mathbf{W}_{S}^{l} \boldsymbol{h}_{v}^{l}\right) \end{aligned} ovlhvl+1=∣N(v)∣1(u,r)∈N(v)∑WNlϕ(hul,hrl)=ReLU(ovl+WSlhvl)
其中 h v 0 {h}_{v}^{0} hv0通过查找单词内嵌初始化, h r 0 {h}_{r}^{0} hr0通过关系类型内嵌初始化。 W N l {W}_{N}^{l} WNl和 W S l {W}_{S}^{l} WSl是两个特定于l层的可学习权值矩阵。我们将组合操作定义为 ϕ ( h u , h r ) = h u − h r \phi\left(\boldsymbol{h}_{u}, \boldsymbol{h}_{r}\right)=\boldsymbol{h}_{u}-\boldsymbol{h}_{r} ϕ(hu,hr)=hu−hr,灵感来自TransE模型(Bordes et al., 2013)。
关系嵌入也通过另一个线性变换来更新。
h r l + 1 = W R l h r l \boldsymbol{h}_{r}^{l+1}=\mathbf{W}_{R}^{l} \boldsymbol{h}_{r}^{l} hrl+1=WRlhrl
最后,得到了对静态图上下文进行编码的节点嵌入 h v L G \boldsymbol{h}_{v}^{L_{G}} hvLG和关系嵌入 h r L G \boldsymbol{h}_{r}^{L_{G}} hrLG,用于译码过程中的动态推理。
3.2.2 Context Modeling with Pre-Trained Transformer(用预先训练好的Transformer进行上下文建模)
采用预先训练好的多层变压器译码器GPT-2模型(Radford et al., 2019)来建模文本序列的上下文依赖关系。模型的输入是源序列和目标序列的串联:s = ( x 1 , ⋯ , x N , [ bos ] , y 1 , ⋯ , y M ) \left(x_{1}, \cdots, x_{N},[\text { bos }], y_{1}, \cdots, y_{M}\right) (x1,⋯,xN,[ bos ],y1,⋯,yM)
h t 0 = e t + p t h t l = T block ( H ≤ t l − 1 ) , l ∈ [ 1 , L D ] P ( s t ∣ s < t ) = softmax ( W L M h t L D + b ) \begin{aligned} \boldsymbol{h}_{t}^{0} &=\boldsymbol{e}_{t}+\boldsymbol{p}_{t} \\ \boldsymbol{h}_{t}^{l} &=\mathrm{T}_{\boldsymbol{}} \operatorname{block}\left(\mathbf{H}_{\leq t}^{l-1}\right), l \in\left[1, L_{D}\right] \\ P\left(s_{t} \mid \boldsymbol{s}_{
其中,et和pt分别为标记嵌入向量和位置嵌入向量。T block是掩蔽自我注意的变压器块。在第t个时间步长 h t L D {h}_{t}^{L_{D}} htLD处的最终隐藏状态作为多跳推理模块的输入, h t L D {h}_{t}^{L_{D}} htLD对上下文信息进行编码。
3.2.3 Dynamic Multi-Hop Reasoning Flow(动态多跳推理流程)
为在生成过程中对图结构进行显式推理,设计了一个动态推理模块,在每一个解码步骤中利用知识图的结构模式和上下文信息沿关系路径传播证据。
模块通过多次更新外部节点与被访问的邻居的得分来广播G上的信息,直到访问了G上的所有节点。最初,Cx中对应概念的节点被赋予1分,其他未访问的节点被赋予0分。
对于未访问的节点 v ∈ V v \in V v∈V,它的节点得分ns(v)是通过聚集来自的证据来计算的Nin(v)表示直接连接v的已访问节点u及其边r的集合。
n s ( v ) = f ( u , r ) ∈ N i n ( v ) ( γ ⋅ n s ( u ) + R ( u , r , v ) ) n s(v)=\underset{(u, r) \in \mathcal{N}_{i n}(v)}{f}(\gamma \cdot n s(u)+R(u, r, v)) ns(v)=(u,r)∈Nin(v)f(γ⋅ns(u)+R(u,r,v))
其中 γ \gamma γ是控制前一跳信息流强度的折扣因素。f(·)是一个聚合器,它将连接节点的分数集合起来。我们考虑两种形式的聚合器:max(·)和mean(·)。我们使用max(·)作为主要结果,在消融研究中使用mean(·)表示结果。
R(u, r, v)是三重关联,它反映了三联体(u, r, v)在当前语境下给出的证据的相关性。我们计算三重相关性如下:
R ( u , r , v ) = σ ( h u , r , v T W sim h t L D ) h u , r , v = [ h u L G ; h r L G ; h v L G ] \begin{aligned} R(u, r, v) &=\sigma\left(\boldsymbol{h}_{u, r, v}^{\mathrm{T}} \mathbf{W}_{\operatorname{sim}} \boldsymbol{h}_{t}^{L_{D}}\right) \\ \boldsymbol{h}_{u, r, v} &=\left[\boldsymbol{h}_{u}^{L_{G}} ; \boldsymbol{h}_{r}^{L_{G}} ; \boldsymbol{h}_{v}^{L_{G}}\right] \end{aligned} R(u,r,v)hu,r,v=σ(hu,r,vTWsimhtLD)=[huLG;hrLG;hvLG]
经过H跳后,通过归一化得到节点的最终分布。
P ( c t ∣ s < t , G ) = softmax v ∈ V ( n s ( v ) ) P\left(c_{t} \mid s_{
其中ct为第t个时间步处所选节点的概念。
直观地,推理模块根据当前的解码器状态,通过考虑三重证据,学习沿路径动态分布。
3.2.4 Generation Distribution with Gate Control(带门控制的生成分配)
用一个软门概率gt表示是否要复制一个概念生成控制权重的两个分布类似于复制机制。
g t = σ ( W g a t e h t L D ) g_{t}=\sigma\left(\mathbf{W}_{g a t e} \boldsymbol{h}_{t}^{L_{D}}\right) gt=σ(WgatehtLD)
最终的输出分布是两个分布gt和1-gt的加权的线性组合。
P ( y t ∣ y < t , x , G ) = g t + N ⋅ P ( c t + N ∣ s < t + N , G ) + ( 1 − g t + N ) ⋅ P ( s t + N ∣ s < t + N ) \begin{aligned} P\left(y_{t} \mid \boldsymbol{y}_{
其中N是输入文本序列的长度。
3.3 Training and Inference(训练与推论)
为了训练所提出的模型,我们最小化产生地面真值目标序列的负对数似然 y gold = ( y 1 , y 2 ⋯ , y M , [ eos ] ) \boldsymbol{y}^{\text {gold }}=\left(y_{1}, y_{2} \cdots, y_{M},[\text { eos }]\right) ygold =(y1,y2⋯,yM,[ eos ])
L g e n = ∑ t = 1 M + 1 − log P ( y t g o l d ∣ y < t g o l d , x , G ) \mathcal{L}_{g e n}=\sum_{t=1}^{M+1}-\log P\left(y_{t}^{\mathrm{gold}} \mid \boldsymbol{y}_{
增加了一个辅助栅损失Lgate来监督一个概念或一个通用词的选择概率。此外,还引入了弱监督Lweak来诱导预测的三重关联,以匹配由宽度优先搜索从源概念得到的启发式边标签到图上ygold中的概念。这两个损失函数都采用二元交叉熵的形式。
最终需要优化的损失是线性组合: L g e n + α L g a t e + β L w e a k \mathcal{L}_{g e n}+\alpha \mathcal{L}_{g a t e}+\beta \mathcal{L}_{w e a k} Lgen+αLgate+βLweak
在推理阶段,模型的输入为(x1,···,xN, [bos])。该模型每次生成一个标签,并将其连接到输入序列以生成下一个标签。生成特殊的结束符号[eos]时,生成过程终止。
4 Experiments
4.1 Datasets and Metrics
故事结尾生成(SEG) 是为一个四句话的故事上下文生成一个合理的结尾。
归纳法自然语言生成(NLG) 是生成一个解释性假说给出两个观察:O1作为原因和O2作为后果。
解释生成(EG) 是在给出一个反事实陈述的情况下生成一个解释,以便进行意义构建。
4.2 Extracting Sub-Graphs as Knowledge Grounding(提取子图作为知识基础)
从G中提取一个子图G = (V,E),它由多个相互连接的路径组成,从输入序列中的源概念Cx开始。为了从输入文本序列中识别概念,使用Spacy3对表层文本的lemmatized形式进行模糊匹配,并过滤掉停止词。跟随Guan等人(2019),只考虑动词和名词作为候选概念,因为发现提取的图与所有匹配的概念相比噪声更大。
具体地说,对以下过程进行迭代
H跳点:从当前子图的节点开始(Cx初始化),搜索每个节点的直接邻居,保留有连通边的topB节点,扩大子图。对于每个候选节点,根据其进入该节点的程度进行选择。候选节点v的进入度定义为当前子图中与v直接连接的节点的数量。直观上,保留了那些经常访问的节点和支持图上信息流的突出概念。
4.3 Implementation Details

4.4 Compared Baselines
Seq2Seq 是一种基于有注意机制的门控循环单元(GRU)的序列-序列模型。我们还利用模型的复制机制(Gu et al., 2016)来生成词汇外的单词。
GPT2-FT 是一个GPT-2模型,在特定任务数据集上进行了微调,并从中进行了模型初始化
Radford等人(2019)。
GPT2-OMCS-FT 是常识增强的GPT-2模型,首先在培训后就开放思想常识(OMCS)语料ConceptNet构造。然后在特定任务的数据集上对模型进行微调。
4.5 Automatic Evaluation
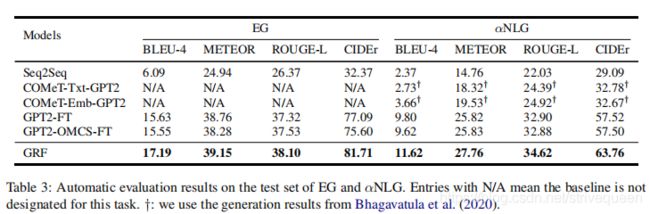
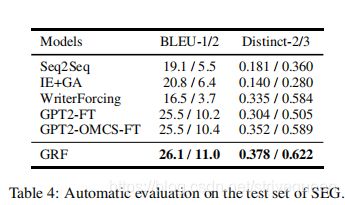
4.6 Human Evaluation
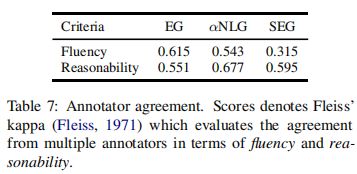
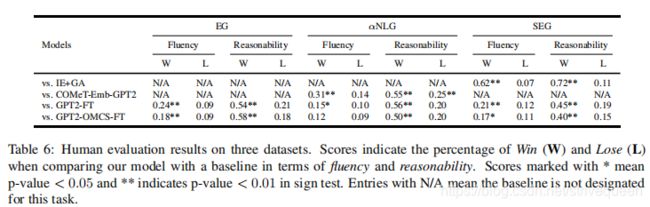 如表6,我们的模型在所有数据集中的两个标准方面显著优于比较基线。具体地说,结合结构常识知识,在产生合理的文本给出的语境中产生显著的改进。
如表6,我们的模型在所有数据集中的两个标准方面显著优于比较基线。具体地说,结合结构常识知识,在产生合理的文本给出的语境中产生显著的改进。
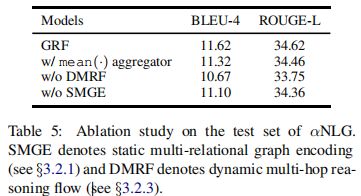
4.7 Ablation Study(消融研究)
所有部件对最终性能有贡献。删除动态推理模块(w/o DMRF)的性能下降幅度最大,说明动态多跳推理在该任务中发挥了主要作用。去掉图表示模块(w/o SMGE)也会降低性能,因为它用关系信息编码图结构,有利于概念选择。我们还展示了使用mean(·)聚合器的推理模块的结果,并观察到与max(·)相比性能有所下降。
4.8 Impact of the Size of Training Data(培训数据大小的影响)
4.9 Effectiveness of Dynamic Multi-Hop Reasoning(动态多跳推理的有效性)

γ \gamma γ控制多跳推理模块中的信息流。如图4所示,当”在0.4和0.6左右时获得最大性能。因此,将模型的所有主要结果设为 γ \gamma γ= 0.5。
5 Conclusion
我们介绍了具有多跳推理流程的生成器,它在文本生成过程中对结构化的常识知识进行了推理。该方法利用外部知识库的结构信息和语义信息,在关系路径上进行动态多跳推理。进行了大量的实验后,经验表明我们的方法在三个文本生成任务上优于现有的将常识知识整合到预先训练过的语言模型的方法。我们还用推理路径证明了我们的方法的可解释性。