Paddle2.0让你成为诗词大师-PaddlePoetry

项目地址:https://github.com/ZMpursue/LSTM_Write_Poetry
本教程将通过一个示例对LSTM进行介绍。通过搭建训练LSTM网络,我们将训练一个模型来生成唐诗。本文将对该实现进行详尽的解释,并阐明此模型的工作方式和原因。并不需要过多专业知识,但是可能需要新手花一些时间来理解的模型训练的实际情况。为了节省时间,请尽量选择GPU进行训练。
1 简介
本项目基于paddlepaddle2.0,结合长短期记忆(Long short-term memory, LSTM),以唐诗为数据集通过监督学习的方式,训练生成唐诗。
参考文档:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
1.1 LSTM解决什么问题?
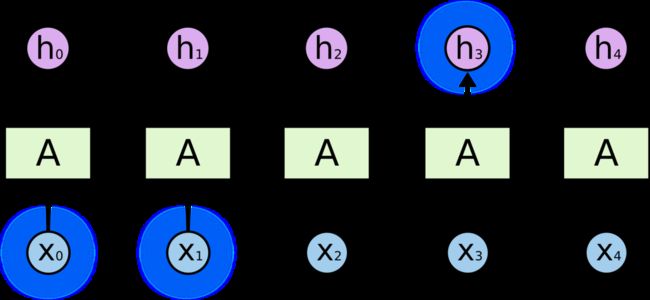
RNN突出的优点之一就是可以用来连接先前的信息到当前的任务上,有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果试着预测 “the clouds are in the ___ ” 最后的词,我们并不需要任何其他的上下文下一个词显然就应该是sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以充分使用先前信息来预测。
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
LSTM的出现为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
1.2 什么是LSTM?
Long Short Term 网络,一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过专门的设计来避免长期依赖问题。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
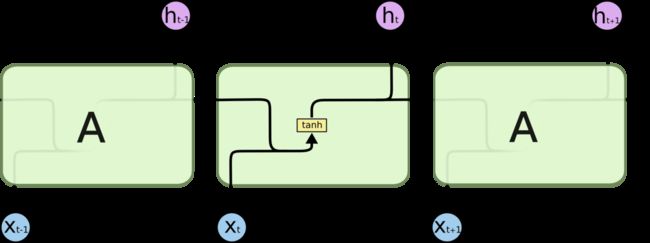
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。

现在,我们先来熟悉一下图中使用的各种元素的图标。

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
1.3 LSTM核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
1.4 LSTM详解
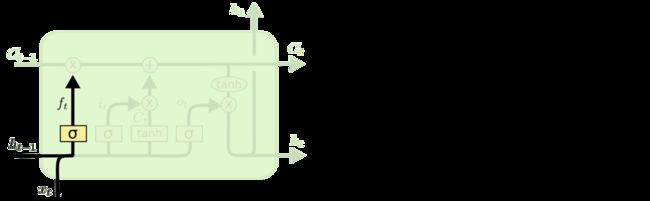
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为遗忘门层完成。该门会读取 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出一个在 0 到 1 之间的数值给每个在细胞状态 C t − 1 C_{t-1} Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”。让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
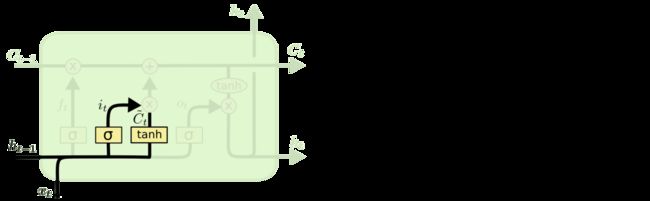
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称输入门层决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gg7pFr6E-1607831223631)(https://latex.codecogs.com/svg.latex?\tilde{C}t)]会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
现在是时候去更新上一个状态值 C t − 1 C_{t−1} Ct−1了,将其更新为 C t C_t Ct。前面的步骤以及决定了应该做什么,我们只需实际执行即可。
我们将上一个状态值乘以 f t f_t ft,以此表达期待忘记的部分。之后我们将得到的值加上 i t ∗ C ~ t i_t*\tilde{C}_t it∗C~t。这个得到的是新的候选值, 按照我们决定更新每个状态值的多少来衡量.
在语言模型的例子中,对应着实际删除关于旧主题性别的信息,并添加新信息,正如在之前的步骤中描述的那样。

最后,我们需要决定要输出的内容。此输出将基于我们的单元状态,但将是过滤后的版本。首先,我们运行一个Sigmoid层,该层决定要输出的单元状态的哪些部分。然后,我们通过激活函数Tanh(将值规范化介于−1和1之间)并乘以Sigmoid的输出,这样我们就只输出我们决定的部分。
对于语言模型示例,由于它只是看到一个主语,因此可能要输出与动词相关的信息,以防万一。例如,它可能输出主语是单数还是复数,以便我们知道如果接下来是动词,则应将动词以哪种形式组合。

2 定义超参数
from paddle.io import Dataset
import paddle.fluid as fluid
import numpy as np
import paddle
class Config(object):
num_layers = 3 # LSTM层数
data_path = 'work/tang_poem.npz' # 诗歌的文本文件存放路径
lr = 1e-3 # 学习率
use_gpu = True # 是否使用GPU
epoch = 20
batch_size = 4 # mini-batch大小
maxlen = 125 # 超过这个长度的之后字被丢弃,小于这个长度的在前面补空格
plot_every = 1000 # 隔batch 可视化一次
max_gen_len = 200 # 生成诗歌最长长度
model_path = "work/checkpoints/model.params.50" # 预训练模型路径
prefix_words = '欲穷千里目,更上一层楼' # 不是诗歌的组成部分,用来控制生成诗歌的意境
start_words = '老夫聊发少年狂,' # 诗歌开始
model_prefix = 'work/checkpoints/model.params' # 模型保存路径
embedding_dim = 256 # 词向量维度
hidden_dim = 512 # LSTM hidden层维度
3.定义DataLoader
数据集由唐诗组成,包含唐诗57580首125字(不足和多余125字的都被补充或者截断)、ix2word以及word2ix共三个字典存储为npz格式
paddle.enable_static()
datas = np.load(Config.data_path,allow_pickle=True)
data = datas['data']
#加载映射表
ix2word = datas['ix2word'].item()
word2ix = datas['word2ix'].item()
class dataset(Dataset):
def __init__(self, data):
super(dataset,self).__init__()
self.data = data
def __getitem__(self, idx):
poem = data[idx]
return poem
def __len__(self):
return len(self.data)
train_dataset = dataset(data)
poem = paddle.static.data(name='poem', shape=[None,125], dtype='float32')
if Config.use_gpu:
device = paddle.set_device('gpu')
places = paddle.CUDAPlace(0)
else:
device = paddle.set_device('cpu')
places = paddle.CPUPlace()
paddle.disable_static(device)
train_loader = paddle.io.DataLoader(
train_dataset,
places=places,
feed_list = [poem],
batch_size=Config.batch_size,
shuffle=True,
num_workers=2,
use_buffer_reader=True,
use_shared_memory=False,
drop_last=True,
)
4.定义网络
网络由一层Embedding层和三层LSTM层再通过全连接层组成
- input:[seq_len,batch_size]
- 经过embedding层,embeddings(input)
- output:[batch_size,seq_len,embedding_size]
- 经过LSTM,lstm(embeds, (h_0, c_0)),输出output,hidden
- output:[batch, seq_len, hidden_size]
- Reshape再进过Linear层判别
- output:[batch*seq_len, vocabsize]
import paddle.fluid
class Peom(paddle.nn.Layer):
def __init__(self,vocab_size,embedding_dim,hidden_dim):
super(Peom, self).__init__()
self.embeddings = paddle.nn.Embedding(vocab_size,embedding_dim)
self.lstm = paddle.nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=Config.num_layers,
)
self.linear = paddle.nn.Linear(in_features=hidden_dim,out_features=vocab_size)
def forward(self,input_,hidden=None):
seq_len, batch_size = paddle.shape(input_)
embeds = self.embeddings(input_)
if hidden is None:
output,hidden = self.lstm(embeds)
else:
output,hidden = self.lstm(embeds,hidden)
output = paddle.reshape(output,[seq_len*batch_size,Config.hidden_dim])
output = self.linear(output)
return output,hidden
5.训练过程
- 输入的input为(batch_size,seq_len)
- 通过input_,target = data_[:,:-1],data_[:,1:]将每句话分为前n-1个字作为真正的输入,后n-1个字作为label,size都是(batch_size, seq_len-1)
- 经过网络,得出output:((seq_len-1)*batch, vocab_size)
- 通过label经过reshape将target变成((seq_len-1)*batch)
损失函数为:crossEntropy,优化器为:Adam
loss_= []
def train():
model = Peom(
len(word2ix),
embedding_dim = Config.embedding_dim,
hidden_dim = Config.hidden_dim
)
# state_dict = paddle.load(Config.model_path)
# model.set_state_dict(state_dict)
optim = paddle.optimizer.Adam(parameters=model.parameters(),learning_rate=Config.lr)
lossf = paddle.nn.CrossEntropyLoss()
for epoch in range(Config.epoch):
for li,data in enumerate(train_loader()):
optim.clear_grad()
data = data[0]
#data = paddle.transpose(data,(1,0))
x = paddle.to_tensor(data[:,:-1])
y = paddle.to_tensor(data[:,1:],dtype='int64')
y = paddle.reshape(y,[-1])
y = paddle.to_tensor(y,dtype='int64')
output,hidden = model(x)
loss = lossf(output,y)
loss.backward()
optim.step()
loss_.append(loss.numpy()[0])
if li % Config.plot_every == 0:
print('Epoch ID={0}\t Batch ID={1}\t Loss={2}'.format(epoch, li, loss.numpy()[0]))
results = list(Config.start_words)
start_words_len = len(Config.start_words)
# 第一个词语是' ]])
input = paddle.reshape(input,[1,1])
hidden = None
# 若有风格前缀,则先用风格前缀生成hidden
if Config.prefix_words:
# 第一个input是,后面就是prefix中的汉字
# 第一个hidden是None,后面就是前面生成的hidden
for word in Config.prefix_words:
output, hidden = model(input, hidden)
input = paddle.to_tensor([word2ix[word]])
input = paddle.reshape(input,[1,1])
# 开始真正生成诗句,如果没有使用风格前缀,则hidden = None,input = ' :
del results[-1]
break
results = ''.join(results)
print(results)
paddle.save(model.state_dict(), Config.model_prefix)
train()
6.Loss变化过程
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 6))
x = np.arange(len(loss_))
plt.title('Loss During Training')
plt.xlabel('Number of Batch')
plt.plot(x,np.array(loss_))
plt.savefig('work/Loss During Training.png')
plt.show()
7.生成唐诗
7.1 模式一 <首句续写唐诗>
例如:”老夫聊发少年狂“
老夫聊发少年狂,嫁得双鬟梳似桃。
青丝长发娇且红,輭舞脸低时未昏。
娇嚬欲尽一双转,笑语千里相竞言。
朝阳上去花欲尽,花时且落花前过。
秾雨霏霏满地晓,红妆白鸟飞下郭。
灯前织女嫁新租,袖里垂纶舞袖舞。
罗袖焰扬簷下樱,一宿十二花绵绵。
西施夹道春风暖,嫩粉萦丝弄金蘂。
7.2 模式二<藏头诗>
例如:”夜月一帘幽梦春风十里柔情“
夜半星初洽,月明星未稀。
一缄琼烛动,帘外玉环飞。
幽匣光华溢,梦中形影微。
春风吹蕙笏,风绪拂莓苔。
十月涵金井,里尘氛祲微。
柔荑暎肌骨,情酒围唇肌。
# 给定首句生成诗歌
def generate(model, start_words, prefix_words=None):
results = list(start_words)
start_words_len = len(start_words)
# 第一个词语是' ]])
input = paddle.reshape(input,[1,1])
hidden = None
# 若有风格前缀,则先用风格前缀生成hidden
if prefix_words:
# 第一个input是,后面就是prefix中的汉字
# 第一个hidden是None,后面就是前面生成的hidden
for word in prefix_words:
output, hidden = model(input, hidden)
input = paddle.to_tensor([word2ix[word]])
input = paddle.reshape(input,[1,1])
# 开始真正生成诗句,如果没有使用风格前缀,则hidden = None,input = ' :
del results[-1]
break
results = ''.join(results)
return results
# 生成藏头诗
def gen_acrostic(model, start_words, prefix_words=None):
result = []
start_words_len = len(start_words)
input = paddle.to_tensor([word2ix['' ]])
input = paddle.reshape(input,[1,1])
# 指示已经生成了几句藏头诗
index = 0
pre_word = ''
hidden = None
# 存在风格前缀,则生成hidden
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = paddle.to_tensor([word2ix[word]])
input = paddle.reshape(input,[1,1])
# 开始生成诗句
for i in range(Config.max_gen_len):
output, hidden = model(input, hidden)
_,top_index = paddle.fluid.layers.topk(output[0],k=1)
top_index = top_index.numpy()[0]
w = ix2word[top_index]
# 说明上个字是句末
if pre_word in {
'。', ',', '?', '!', '' }:
if index == start_words_len:
break
else:
w = start_words[index]
index += 1
# print(w,word2ix[w])
input = paddle.to_tensor([word2ix[w]])
input = paddle.reshape(input,[1,1])
else:
input = paddle.to_tensor([top_index])
input = paddle.reshape(input,[1,1])
result.append(w)
pre_word = w
result = ''.join(result)
return result
#读取训练好的模型
model = Peom(
len(word2ix),
embedding_dim = Config.embedding_dim,
hidden_dim = Config.hidden_dim
)
state_dict = paddle.load('work/checkpoints/model.params.50')
model.set_state_dict(state_dict)
print('[*]模式一:首句续写唐诗:')
#生成首句续写唐诗(prefix_words为生成意境的诗句)
print(generate(model, start_words="春江潮水连海平,", prefix_words="滚滚长江东逝水,浪花淘尽英雄。"))
print('[*]模式二:藏头诗:')
#生成藏头诗
print(gen_acrostic(model, start_words="夜月一帘幽梦春风十里柔情", prefix_words="落花人独立,微雨燕双飞。"))