python图片表格转excel表格_python提取图片内容并转换成对应表格的markdown代码
本节我们将介绍使用python识别一张图片中的内容,并试着得到一张表格,当然并不是类似于Excel的表格,而是该表格的markdown代码。
注:原创内容,转载请标明出处!
相关工具的安装
本次实验环境:win10,Pycharm2019.3。
安装相关库既可以使用命令行,也可以使用Pycharm自带的工具。
打开cmd命令行或者powershell。
首先安装PIL:
pip install Pillow
![]()
这是已经安装好PIL的示意图。
之后,安装pytesseract:
pip install pytesseract

这是已经安装好pytesseract的示意图。
接下来,安装Tesseract-OCR,注意对应系统。
环境配置,输入
tesseract
tesseract -v
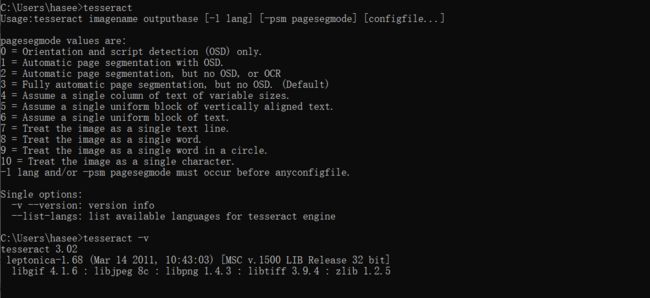
如果正常输出,表示配置成功了(我在实际操作时,安装完成后自动配置了系统变量),如果没有,找到之前安装的路径:
例如:

G:\Program Files (x86)\Tesseract-OCR
将该路径添加到系统变量中
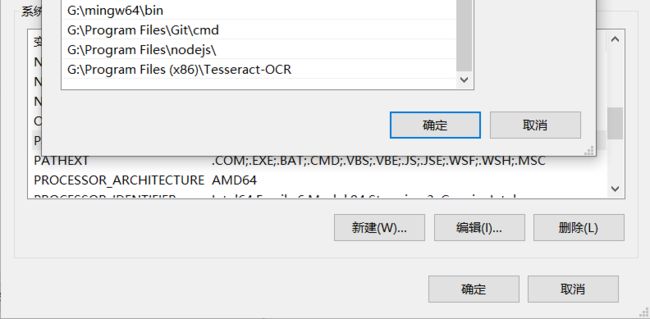
如果你想做英文之外的识别,Tesseract-OCR是没有带其他语言包的,你可以去下载其他语言包。
这里我添加了简体中文的语言包,但是使用的是自带的英文语言包。
同时,我们还需要一项配置,找到python安装路径下的pytesseract.py,我这里的路径是
G:\Python37\Lib\site-packages\pytesseract
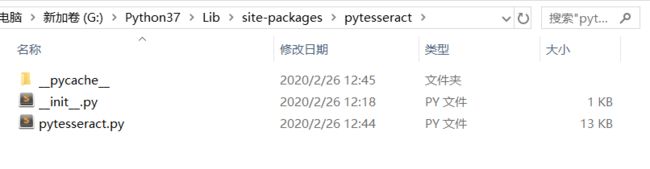
打开该路径下的pytesseract.py文件。
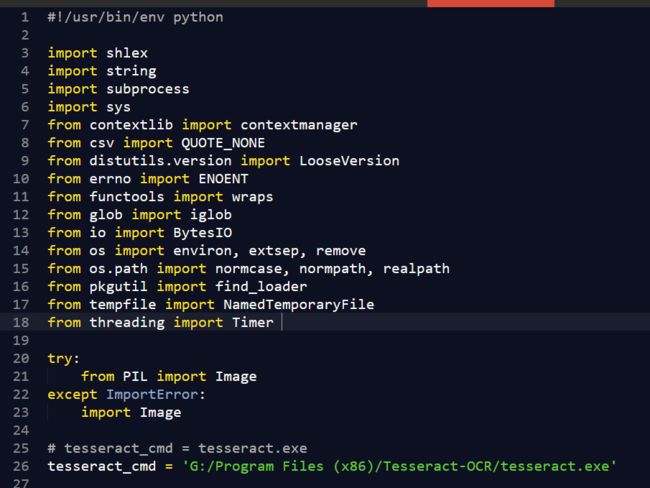
将其中的
tesseract_cmd = tesseract.exe
替换为你之前安装Tesseract-OCR的路径。
tesseract_cmd = 'G:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
简单测试
这是一张图:

先简单演示一下:
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
# 注意图片路径和名称
path = "3.jpg"
# lang参数指定了语言包,你可以下载相应的语言包,这里使用自带的英文包
content = pytesseract.image_to_string(Image.open(path), lang="eng")
print(content)
由于数据有些多,我只列出一部分。
90
70
50
40
130
70
90
20
120
110
100
30
...
70
60
80
60
80
60
50
50
60
60
60
60
这里呢,我们的工作就完成了大部分了,接下来我们试着将它转换一个对应表格的markdown代码。
转换
我们得到的结果是一个字符串,离我们实际的表格内容还有一段距离,也不难,做些数据处理就可以了。
markdown表格的语法:
| 左对齐 | 居中对齐 | 右对齐 |
| :-----| :----: | ----: |
| 内容 | 内容 | 内容 |
| 内容 | 内容 | 内容 |
这里直接上程序了:
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
path = "3.jpg"
text = pytesseract.image_to_string(Image.open(path), lang="eng")
text_list = text.split()
rows = 12
lists = 6
md_text = []
list_name = ["语文", "数学", "英语", "物理", "化学", "生物"]
md_text.append(["|"])
for name in list_name:
md_text[0].append(str(name) + "|")
md_text[0] = "".join(md_text[0])
direction = ["中", "中", "中", "中", "中", "中"]
md_text.append(["|"])
for d in direction:
if str(d) == "左":
md_text[1].append(":----|")
if str(d) == "中":
md_text[1].append(":----:|")
if str(d) == "右":
md_text[1].append("----:|")
md_text[1] = "".join(md_text[1])
for r in range(rows):
res = "|"
for l in range(lists):
res += (text_list[r + l * rows] + "|")
md_text.append(res)
file = open("3.txt", "w")
for m in md_text:
file.write(m + "\n")
file.close()
print(md_text)
结果:
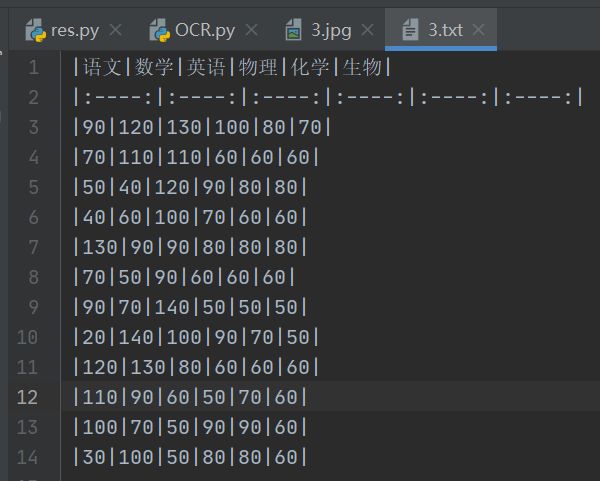
['|语文|数学|英语|物理|化学|生物|', '|:----:|:----:|:----:|:----:|:----:|:----:|', '|90|120|130|100|80|70|', '|70|110|110|60|60|60|', '|50|40|120|90|80|80|', '|40|60|100|70|60|60|', '|130|90|90|80|80|80|', '|70|50|90|60|60|60|', '|90|70|140|50|50|50|', '|20|140|100|90|70|50|', '|120|130|80|60|60|60|', '|110|90|60|50|70|60|', '|100|70|50|90|90|60|', '|30|100|50|80|80|60|']
看看文件内容。
看看渲染结果:
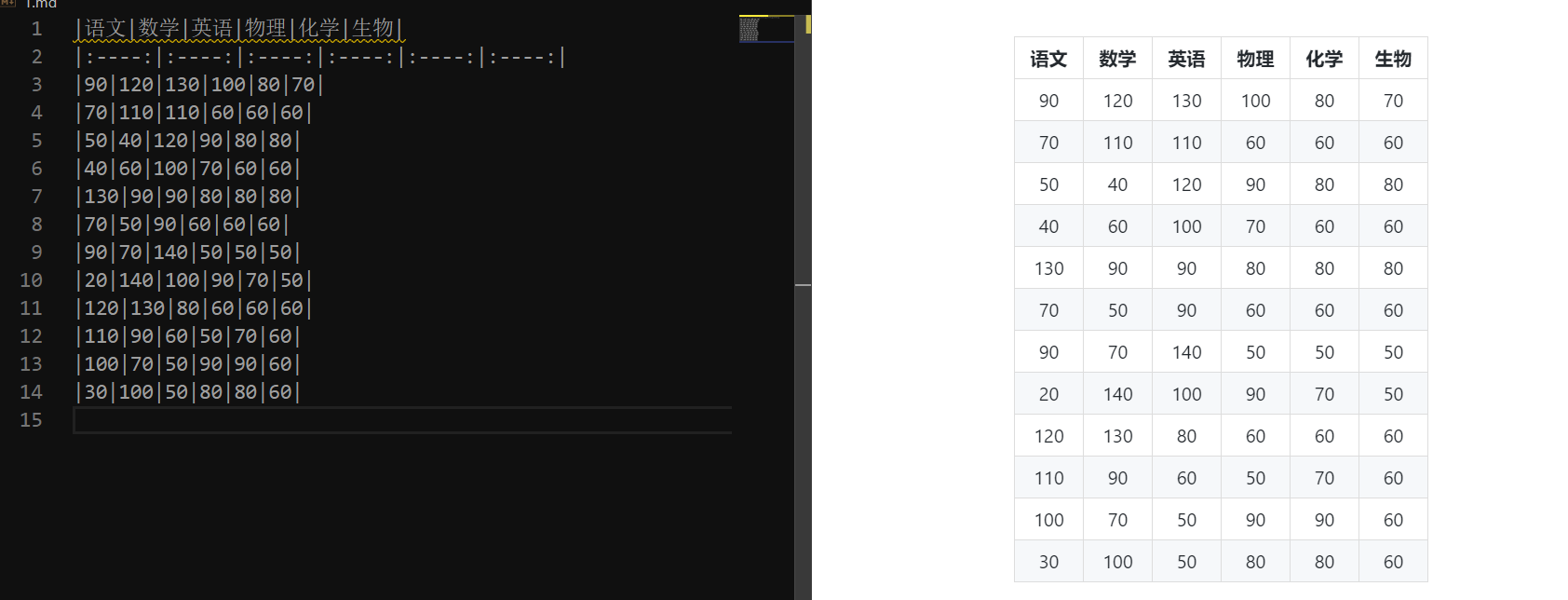
结果还不错,当然我们并没有训练样本,所以对于稍微复杂一点的图片,可能识别结果就不好了。
之后我以这个为基础,写一个带GUI的程序,界面如下:
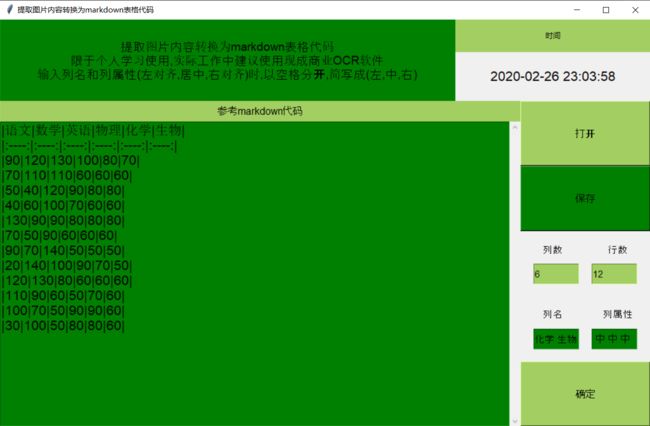
完整带GUI程序的github仓库地址。