利用sklearn实现adaboost,以单一分类树为例
0普通决策树
0.1生成数据
sklearn提供了随机数据生成的功能:
make_regression 生成回归模型的数据
make_multilabel_classification生成分类模型数据
用make_blobs生成聚类模型数据
用make_gaussian_quantiles生成分组多维正态分布的数据
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_gaussian_quantiles
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
# n_samples(生成样本数), n_features(样本特征数)--x1数组列数,noise(样本随机噪音)
x1, y1 = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
# 二维正态分布,生成数据按照分位数分为两类,500个样本点,2个特征样本,y=0,1
x2, y2 = make_gaussian_quantiles(mean=(3, 3), n_samples=500, n_features=2, n_classes=2)
# 二维正态分布,生成数据按照分位数分为两类,500个样本点,2个特征样本均值(正态分布均值(3,3)),y=0,1
# 将两组数据合成为一组
x_data = np.concatenate((x1, x2), axis=0) # 进行数组列拼接
y_data = np.concatenate((y1, 1 - y2)) # y2里1-1=0,1-0=1,为了提高分类难度
0.2建立决策树模型
model = DecisionTreeClassifier(max_depth=3)
model.fit(x_data, y_data)
0.3生成等高线图
# 获取值的范围
x1_min, x1_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
x2_min, x2_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
x1_range = np.arange(x1_min, x1_max, 0.02)
x2_range = np.arange(x2_min, x2_max, 0.02)
xx, yy = np.meshgrid(x1_range, x2_range)
predict = model.predict(np.c_[xx.ravel(), yy.ravel()])
z = predict.reshape(xx.shape)
cs = plt.contourf(xx, yy, z)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
结果
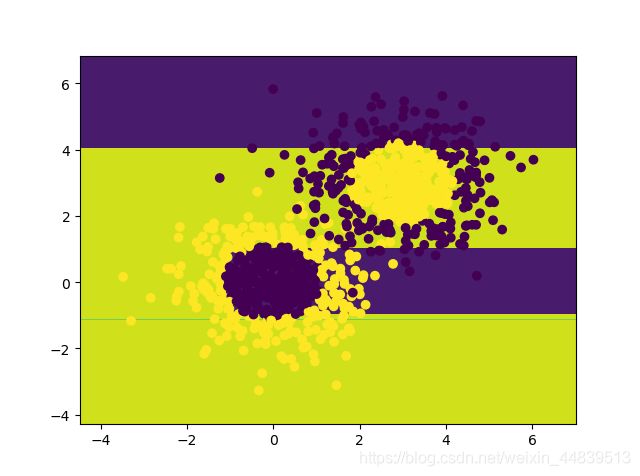
0.4精度
# 模型的准确度
print(model.score(x_data, y_data))
0.771
可见单一决策树模型精度有待提高
1 Adaboost
# 加入adaboost
model2 = AdaBoostClassifier(model, n_estimators=10) # 将原先模型代入adaboost,迭代次数为10
1.1训练模型
model2.fit(x_data, y_data)
1.2生成等高线图
x1min, x1max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
x2min, x2max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
x1range = np.arange(x1min, x1max, 0.02)
x2range = np.arange(x2min, x2max, 0.02)
xx, yy = np.meshgrid(x1range, x2range)
z1 = model2.predict(np.c_[xx.ravel(), yy.ravel()])
z1 = z1.reshape(xx.shape)
a = plt.contourf(xx, yy, z1)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
1.3精度
print(model2.score(x_data, y_data))
0.983
1.4结果
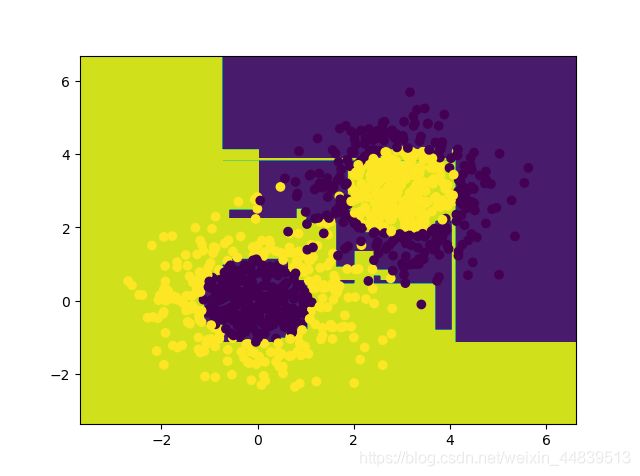
可见精度有所提高。