Python爬虫 高性能异步爬虫 多线程 多进程 线程池 进程池 协程asyncio:async/await
高性能异步爬虫
目的:在爬虫中使用异步实现高性能的数据爬取操作。
单线程串行爬取
单线程下的串行爬取,同步阻塞,效率极其低
get() 方法会阻塞程序的执行,直到请求到数据之后放行
import requests
def get_content(url):
content = requests.get(url=url, headers=headers).content
return content
def parse_content(content):
print(len(content))
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url_list = [
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5094.rar',
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5093.rar',
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5089.rar'
]
for url in url_list:
content = get_content(url)
parse_content(content)
print('over')
异步爬虫
方式
一个进程可以包括一个或多个线程。
- 多线程、多进程(不建议):
好处:可以为相关的阻塞操作单独开启线程或进程,阻塞操作就可以异步执行。
弊端:无法无限制的开启多线程或者多进程,耗费CPU的资源。 - 进程池、线程池(适当的使用):
好处:可以降低系统对进程或者线程的创建和销毁的频率,从而很好的降低系统的开销。
弊端:池中进程或者线程的数量是有上限的。 - 单线程+异步协程(推荐)
好处:可以为相关的阻塞操作单独开启线程或进程,阻塞操作就可以异步执行。
弊端:无法无限制的开启多线程或者多进程,耗费CPU的资源。
多线程、多进程
无
进程池、线程池
1、首先使用单线程串行进行耗时的测试:
import time
def get_name(name):
print('start '+name)
time.sleep(2)
print('end '+name)
if __name__ == "__main__":
start_time = time.time()
name_list = ['a', 'b', 'c', 'd']
for name in name_list:
get_name(name)
end_time = time.time()
print('%d second' % (end_time-start_time))
耗时:8s

2、使用线程池方式:
原则
线程池处理的是阻塞且耗时的操作
使用步骤
首先需要导入线程池模块对应的类
from multiprocessing.dummy import Pool
示例化线程池对象,参数代表多少个线程
pool = Pool(4)
将阻塞方法进行处理,pool.map()返回值就是对应阻塞方法的返回值
pool.map(阻塞方法, 可迭代数据)
如果阻塞对量大于线程池数量,效果就不会太明显。
import time
from multiprocessing.dummy import Pool
def get_name(name):
print('start '+name)
time.sleep(2)
print('end '+name)
if __name__ == "__main__":
start_time = time.time()
name_list = ['a', 'b', 'c', 'd']
pool = Pool(4)
pool.map(get_name, name_list)
end_time = time.time()
print('%d second' % (end_time-start_time))
执行结果:2s

改为2个线程时:
pool = Pool(2)

实战
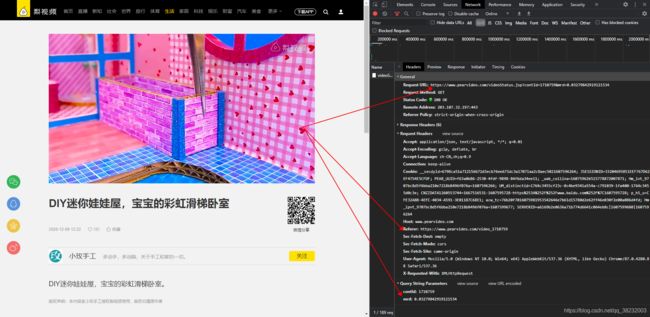
爬取梨视频视屏数据 https://www.pearvideo.com/category_5

import random
import requests
import json
import os
from lxml import etree
from multiprocessing.dummy import Pool
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
def get_data(url):
print(url.split('_')[-1]+' start')
# 请求ajax,获得video的json数据,包含视屏下载的url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Referer': 'https://www.pearvideo.com/'+url}
params = {
'contId': url.split('_')[-1],
'mrd': random.random()
}
page_url = 'https://www.pearvideo.com/videoStatus.jsp'
data = requests.get(url=page_url, params=params, headers=headers).json()
video_url = data['videoInfo']['videos']['srcUrl']
# 头疼竟然伪装真实视屏url
# json-url:https: // video.pearvideo.com/mp4/third/20201210/1607599510419-10008579-101252-hd.mp4
# 真实url:https: // video.pearvideo.com/mp4/third/20201210/cont-1710958-10008579-101252-hd.mp4
video_url = video_url.split('/160')
param = video_url[-1].split('-')
param[0] = 'cont-' + url.split('_')[-1]
video_url = video_url[0]+'/'+'-'.join(param)
video_data = requests.get(url=video_url, headers=headers).content
# 持久化存储
with open('./异步/video/'+url.split('_')[-1]+'.mp4', 'wb') as fp:
fp.write(video_data)
print(url.split('_')[-1]+' download')
if __name__ == "__main__":
if not os.path.exists('./异步/video'):
os.mkdir('./异步/video')
# 获取video界面url
url = 'https://www.pearvideo.com/category_5'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
url_list = tree.xpath('//ul[@id="listvideoListUl"]/li/div[1]/a/@href')
# 线程
pool = Pool(4)
pool.map(get_data, url_list)
# 关闭线程
pool.close()
# 主线程等待子线程结束之后结束
pool.join()
print('over')
单线程+异步协程
协程:3.4出现,以生成器对象为基础。3.6之后简化封装。
- event_loop 事件循环:相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件时,就会调用对应的处理方法。
- coroutine 协程:协程对象,只一个使用async关键字定义的函数,他的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环中,由事件循环调用。
- task 任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程的进一步封装,其中包含任务的各种状态。
- future:代表将来执行或没有执行的任务结果。它与task没有本质的区别。
- async/await 关键字:python3.5用于定义协程的关键字,async定义一个协程,await用于挂起阻塞的异步调用接口。
asyncio 多任务
1、如果协程函数中,出现同步模块的代码,就不能实现异步
import asyncio
import time
async def request(url):
print('start ', url)
# 如果协程函数中,出现同步模块的代码,就不能实现异步
time.sleep(2)
print('end ', url)
url_list = [
'www.baidu.com',
'www.qq.com',
'www.aliyun.com'
]
task_list = []
start_time = time.time()
for url in url_list:
c = request(url)
task = asyncio.ensure_future(c)
task_list.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task_list))
print(time.time()-start_time)

2、异步
import asyncio
import time
async def request(url):
print('start ', url)
# 在asyncio中遇到阻塞操作,必须进行手动挂起 await
await asyncio.sleep(2)
print('end ', url)
url_list = [
'www.baidu.com',
'www.qq.com',
'www.aliyun.com'
]
task_list = []
start_time = time.time()
for url in url_list:
c = request(url)
task = asyncio.ensure_future(c)
task_list.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task_list))
print(time.time()-start_time)

for简化
task_list = [request(url) for url in url_list]
=
task_list = []
for url in url_list:
c = request(url)
task = asyncio.ensure_future(c)
task_list.append(task)
aiohttp模块
requests 模块是同步的,不支持异步
所以协程中使用aiohttp,是基于异步网络请求模块:
pip install aiohttp
同时支持 get()、post()
也支持 headers、params/data、proxy=‘http://ip:prot’
使用aiohttp模块的ClientSession对象,完成异步爬虫任务:
import aiohttp
import asyncio
async def get_content(session, url):
file_name = url.split('/')[-1]
print('开始下载 '+file_name)
async with session.get(url, verify_ssl=False) as response:
content = await response.content.read()
with open('./异步/协程/'+file_name, 'wb') as fp:
fp.write(content)
print('下载完成 '+file_name)
async def main():
async with aiohttp.ClientSession() as session:
url_list = [
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5094.rar',
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5093.rar',
'https://downsc.chinaz.net/Files/DownLoad/moban/202012/moban5089.rar'
]
tasks = [asyncio.create_task(get_content(session, url))
for url in url_list]
await asyncio.wait(tasks)
if __name__ == "__main__":
asyncio.run(main())