一篇关于轴承故障诊断的综述
在设备的故障检测中,有约30%-40%的设备故障是由轴承故障引起的,因此本文将列举有关检测轴承故障使用到的相关数据集,模型和算法。
数据集
现有的数据集,普遍由固定在电机马达上的两个震动检测器获得,并根据需要,分离震动数据在时域和频域上的特征以供网络模型学习。
不同的数据集,区别在于,检测的马达转速不同,环境不同,取样频率不同,一段样本的时长不同等等
(1)Case Western Reserve University (CWRU) Dataset
该数据集拥有多种数据,测量的时候,通过改变轴承的直径,检测的位置,马达的负载和转速,取样的频率等方式,在有限的实际设备中,生成多种有效数据。
CWRU数据集在实际使用中相当大众,是训练网络模型和检测网络性能的基本数据集。
但数据大多来源于实验室内,数据不够广泛,也不够真实。
(2)Paderborn University Dataset
该数据集在搞分辨率和高采样率的条件下,同步检测电机电流和振动信号。被检测的轴承中,26个为故障轴承,6个健康轴承。故障轴承中,12个为人为损坏,14个为加速寿命造成的更实际的损伤。人为的损坏多为人工钻孔或者人工划损;加速寿命所带来的故障数据,在使用上来说,更具真实性,它更多是因为老化而逐渐失去润滑。
它在提供振动信号的同时,也提供相对应的电流信息,促进完善着基于多物理特性的网络学习模型。
(3)PRONOSTIA Dataset
比起检测轴承故障,该数据集更多是用在检测轴承的剩余有效时间(remaining useful life--RUL)。
它主要提供了在不同条件下的,真实的加速老化轴承数据。收集数据的传感器为转子传感器和压力传感器。
在高频率收集振动数据的同时,它也在监测着轴承的温度数据,便于神经网络从多个物理特性确定轴承的RUL。
(4)Intelligent Maintenance Systems (IMS) Dataset
与普通的数据集不同,该数据集记录的不是人工造成损坏或者通过施加轴电流造成的加速老化故障,IMS数据集包含轴承缺陷演化的完整记录。yue
在一次故障出现之前,一个轴承要在2000转速情况下,连续运行30天,共约经历8千6百万次循环。
同样的,该数据集在监控震动信号的同时,也监督着轴承的温度(用来检测马达的润滑程度),适用于检测轴承的RUL。
图表总结

传统机器学习方法(ML)
与DL的自动提取特征,自动学习模式不同。传统的ML往往需要大量的专业知识和复杂的特征工程,也就是专业人员人工操作处理。先对数据集执行深入的探索性数据分析,再由PCA或者其他方法对数据进行降维处理,最后才是特征提取。其中最麻烦的还是人工的步骤,不同领域的专业知识交叉并不多,在不同的领域研究问题,往往需要多个该领域的专业人员进行手动特征提取,这导致研究成本的增大。
(1) Artificial Neural Networks (ANN)
人工神经网络基本可以算是最原始的神经网络,该网络训练的时候,以定子电流和电机转速测量作为输入(这种方法还需要一个额外的速度编码器来收集电机速度信号作为额外的输入),以预测的轴承条件作为输出。数据集也是在实验室里头,用不同的工况条件采集出来的,35个训练数据,70个测试数据。最终得出的准确率达到了 94.7% 。
(2)Principle Component Analysis (PCA)
PCA算法多用于对数据进行降维,通过计算原始数据集中的信息可用度,去除冗余信息,向用户提供这个对象的低维投影,作为网络模型的输入,这有助于缩短网络模型的训练时间和降低网络训练所需要的计算量。
实验证明,使用PCA提取出来的降维特征学习,要比用原始数据直接学习效果更好,准确率能从88%提升到98%。
(3)K-Nearest Neighbors (k-NN)
它是一种无参数的方法,常用于分类或者回归。通过数据最近的K个邻居的投票,最终决定该数据的类型。故障检测中,采用该方法来确定轴承的故障具体属于哪一个故障类。
(4)Support Vector Machines (SVM)
支持向量机是一种监督学习模型,它分析用于非概率分类或回归分析的数据。同样用于给轴承故障进行分类。
ML目前遇到的问题:
1.滑动:当前故障检测是假定滚动件和轴承滚道之间不发生滑动的基础上实现的,但在现实情况下,这种滑动并不少见
2.频率相互影响:多种故障同时发生时,会互相造成影响,从而模糊单一故障的信息频率。
3.外界的震动:在真实的环境下,除了被检测的轴承,很可能还有其他震动进行干扰,而普通ML的抗噪能力不强。
4.故障的可观察性:有些故障出现的时候,不会产生单独的震动频率,有的故障对震动频率没有明显的影响,依靠震动频率作为检测主体的ML,对于轴承故障检测不够全面。
5.灵敏度:在不同的环境条件下,各故障类型的灵敏度也不一样,在真正投入使用之前,需要收集在不同环境下,各故障类型的灵敏度。
由于ML的难以解释,准确率不稳定,抗噪健壮性不强等特点,ML没有大量投入使用,并逐渐被后来的DL所取代。
基于深度学习的方法(DL)
DL是从ML发展而来的一个机器学习的子集。DL的出现可以主要归功于以下几个因素:
1.数据爆炸:DL学习需要大量的带标签数据,新一代的传感器能收集更多,更广泛的数据,而且得益于CWRU等公开数据集的出现,使得大量带标签数据的获取变得容易,这扩展了DL的输入,促进了DL的发展。(在小数据训练和测试中,DL和ML的性能相差并不大,但随着数据量的增加,二者的准确度也会逐渐区分开来)

2.算法优化:对于DL模型研究加深,能够更高效地训练网络,并达到更高的准确率,实现更快的速度、更好的收敛性。例如,ReLU等算法有助于加速收敛速度;dropout和池等技术有助于防止过拟合等。
3.硬件的进化:DL学习过程需要的计算量相当庞大,也就是学习时间长,导致效率低。高性能GPU的出现,可以显著加速这一训练过程。它强大的计算能力,极大地缩减了DL模型训练的时间,提高了工作效率。(例如,NVIDIA Tesla V100张量核心gpu现在可以比传统cpu更快地解析pb级数据)
DL的出现,迅速取代了传统的,繁琐的ML,相对于ML,DL有以下几个优势:
1.准确率更佳:虽然DL的计算函数比起ML要复杂得多,但DL在解决包括语音、语言、视觉、游戏等多个领域问题方面的表现明显优于ML。
2.自动特征提取:在ML中,特征提取这一环节需要人工实现,并且需要在该领域,拥有一定水平知识的专业人员。而DL中,我们只需要简单地把数据输入到模型中,模型就能自动的更改权重,实现特征自动提取和学习功能。这即减少了特征提取的人工成本,也提高了提取学习效率。
3.可转移性:ML往往是针对某一特殊情景具体制定的,而DL中的模型和技术通常具有通用性,例如,卷积神经网络、循环神经网络和长短期记忆。同一种技术,不需要作过多的改变,只需要更改参数和初始条件,模型就可以简单的转移到另一个领域中使用。
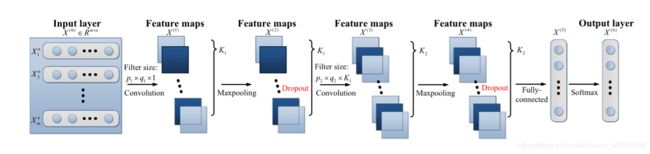
(1) Convolutional Neural Network (CNN)
分为输入层,隐藏层和输出层。低层隐藏层负责获取表面特征,高层隐藏层负责获取高级特征。
CNN擅长处理二维输入,因此在把数据输入到模型之前,需要将不同加速度计获取的一维时域原始数据叠加成二维矢量形式,再作为输入数据传输到模型中。
在CNN中,卷积和池化操作合称为一层,二维数据先通过卷积核卷积,再由池化函数过滤,最后通过一个激活函数(通常为ReLu或sigmoid)激发之后传给下一层。
CNN除了在故障检测中有良好的表现,在健康预测方面也有不错的效果,可以识别一些早期的不良症状和显性特征频率,如润滑退化 (传统的ML很难检测出润滑退化这种相对隐形或早期故障特征)。
CNN变种:
1. an adaptive CNN (ADCNN)
最大的特点是能够自适应动态改变学习率。采用1个ADCNN的故障模式确定组件和3个ADCNNs的故障大小评估组件,以及具有最大池化的3层CNNs。
ADCNN在识别滚动元素缺陷和识别缺陷大小方面具有较好的准确性。
它在CNN传统结构的基础上,增加了错位层,相对于没加错位层的CNN,准确率从83.39%增加到了96.32%。
2.a CNN based on LeNet-5
基于LeNet-5的CNN,它包含2个交替卷积池层和2个全连接层。填充用来控制学习特征的大小,零填充用来防止尺寸损失。改进后的CNN架构能够提供更好的特征提取能力,测试集的准确率达到惊人的99.79%。而ADCNN只有98.1%,SVM为87.45%,ANN为67.70%。
3.a deep fully convolutional neural network(DFCNN)
数据在使用前先转换到光谱上,以便于后面的提取,采用了4层的卷积池化层。准确率达到了99.22%,带PSO的线性SVM只有94.28%,传统SVM为91.43%。
4.a multi-scale CNN(MS-DCNN)
为了节省CNN训练所需的时间,MS-DCNN使用了大小各不相同的卷积核来卷积,来提取不同大小的特征。
9层1-D CNN,2-D CNN,和MS-DCNN准确率分别为98.57%,95.25%,99.27%。在准确率有少量提高的同时,MS-DCNN的参数个数只有52172个,1-D CNN为171606,2-D CNN为213206。
抗噪能力,健壮性和时间复杂度,参数个数就像天平两端 ,很难实现二者兼得
5.Dempster-Shafer theory CNN(IDS-CNN)
IDS-CNN的提出,是为了克服不同负载对故障检测精准度的影响。功能的实现在于,IDS-CNN增加了一个基于基尼系数改进的距离矩阵。
6.LiftingNet
LiftingNet,是为了减少轴承速度变化对精准度的影响,它包括分离层,预测层,上升层,池化层和全连接层。用转速在1720到1797的CWRU数据集测试模型,准确率达到了99.63%。用区分度大的数据测试(转子的频率分别为10,20,30,40Hz),准确率为93.19%,比传统SVM算法准确率搞了14.38%。
7.Pythagorean spatial pyramid pooling(PSPP)
同样是减少轴承转速变化带来影响,通过测试已经可以在转子不同速率的运作下,保持高的准确率。
8.an adaptive overlapping CNN(AOCNN)
普通的CNN在数据输入前,需要先将采集的一维数据,重叠变为二维数据形式。而AOCNN,可以直接把采集的一维原始数据,直接作为输入。
它有一个重叠层,用于对原始振动数据进行采样,在自适应卷积层把原始数据分割为一段段的样本后,在当前层滤波器会对这些样本进行过滤,以获取当前的特征。
通过测试,AOCNN能在检测准确性保持在99.61%的基础上,把实际使用的数据压缩到5%到20%。
即简化了数据维度转化的过程,也降低了实际使用的数据量,减少了模型训练所需要的时间。
CNN的优势:
1.更好的抗噪能力和健壮性:CNN对于同种ANN,在信噪比较低的环境下,准确率增加了25%左右。
2.与传统的ANN相比,CNN几乎不需要神经元链接。
CNN的缺陷:
1.需要的层数往往较多,计算量较大
2.需要大量的已标注数据
有多种的CNN变种,在具体使用时,选择合适的CNN,例如数据量大,就选择能减少参数量,加快运算的CNN;所处环境信噪比较低,就选择抗噪能力强,健壮性强的CNN等。
(2)Auto-encoders
最初时,自编码器被作为ANN的一个非监督预训练方法使用。后来,自动编码器可以作为一种无监督的特征学习方法和一种贪婪的分层神经网络预训练方法使用。
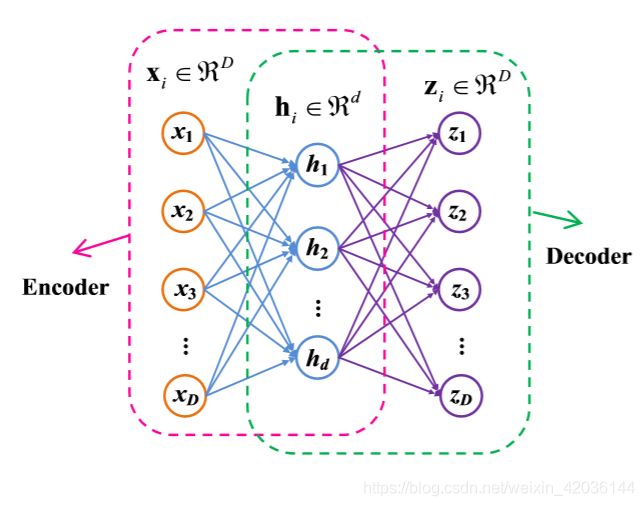
它是一种以重构输入向量为目标的无监督学习方法,现在常用于作为特征提取或者数据降维功能使用。
它由ANN来训练,组成为一个编码器,一层隐藏层和一个解码器,编码器的输出作为解码器的输入。ANN取其原始输入和输出之间的均方误差作为损失函数,目的时通过解码器,还原编码器的输入数据。
ANN的使用:
1.extreme learning machine (ELM)
将自动编码器的自动特征提取能力与ELMs的高训练速度相结合,准确率达到了99.83%(其他传统的ML方法:SVM (WPD-SVM) (94.17%), EMD-SVM (82.83%), WPDELM (86.75%) and EMD-ELM (81.55%))。且运算时间只需要其他方法的60%到70%。
2.stacked denoising auto-encoder (SDA)
和CNN相比,自动编码器的抗噪声能力不强,需要对它的构造作一些处理,以加强其抗噪能力和健壮性。
SDA由三个堆叠在一起的自动编码器组成。为了达到分类性能和训练速度的平衡,使用了三个隐藏层,分别为100、50和25单元。
用CWRU的15%噪声(人为噪声)比例的条件下,SDA的准确率达到了91.79%,比传统SAE的精准度提高了3%到10%。
3.a deep wavelet autoencoder (DWAE) with extreme learning machine (ELM)
将微波函数作为模型的激活函数,用微波自动编码器来进行有效的特征提取。
在此基础上,构造了一个具有多个WAE的DWAE来增强无监督特征学习能力,并采用ELM作为输出分类器。
最终检测准确率达到了95.20%,不仅超越了传统的ML方法(BPNN (85.43%) ,SVM (87.97%),在DL算法里头,也是相当优秀的(the standard DAE with Softmax (89.70%) ,the standard DAE with ELM (89.93%))
4. SAE-LCN (local connection network)
传统SAE的两个缺陷:
1.SAE倾向于提取相似或冗余的特征,这增加了模型的复杂性,而且准确性并没有提高。
2.所学习的特征可能具有位移变特性
为了解决这两个问题,SAE-LCN出现了。SAE-LCN由一个输入层,一个本地层,一个特征层,一个输出层组成。
具体来说,该方法在局部层从输入信号中局部学习特征,然后在特征层中获取位移不变特征,最后在输出层识别一个10类分类问题的轴承健康状况
准确率达到了99.92%,比起EMD, ensemble NN和其他的DL方法,高了1%到5%的准确率。
5.Gath-Geva (GG)
通过引入模糊最大似然估计(FMLE)来确定一个样本属于每个聚类的似然值。
使用8层SDAE从振动信号中提取有用特征,利用GG来识别不同类型的故障。
最差情况下的分类准确率为93.3%,比基于EMD的经典特征提取方案高出近10%。
AE的优势:
1.不需要已标注的数据
2.许多AE变种算法都拥有优秀的抗噪能力和健壮性
AE的缺陷:
1.需要预训练这一步骤
2.模型训练有可能会因错误的消失受到影响
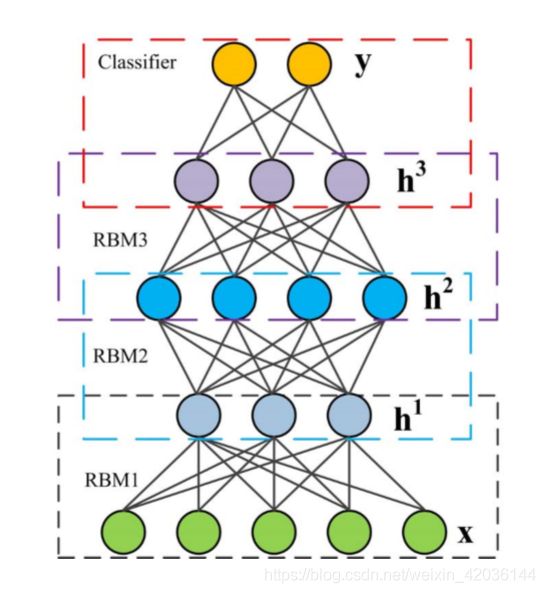
(3) Deep Belief Network (DBN)
深度信念网络可以看作是简单的无监督网络的组合
子网络由一个输入层,一个隐藏层组成,每个子网络的隐藏层,作为下个子网络的输入层(在最上面的两层有无定向连接,允许无监督和监督的网络训练方法)
这种架构形成了快速的叠层间的非监督训练程序
它是一种相当高效的DL算法,在自然语言处理和药物探索方面已经得到重大关注,并于2017年首次用来进行故障诊断
该方法多用于给类型分类
DBN的使用:
1.SAE和DBN结合使用
采用了多传感器振动数据融合技术,把振动在时域和频域上的数据融合起来,使用两层SAE作特征提取,3层DBN作最终分类方法。
准确率达到了97.82%,完全超过了单纯的SAE架构
2.DBN-feed-forward neural network(FNN)
采用DBN作为特征提取方法,FNN作为RUL的预测。
数据的采集:两个垂直于轴的加速器安装在轴承外壳上,以102.4kHz的频率采样,持续两秒
实验证明,当轴承处于故障状态时,该方法的RUL预测相当准确
DBN的优势:
1.创新地提出了一种逐层贪婪学习策略来初始化网络
DBN的缺陷:
1.由于该方法需要两个阶段:初始化阶段和采样阶段,这导致计算代价提高,训练时间增长
(4)Recurrent Neural Network(RNN)
不同于前馈神经网络,RNN以一个循环的方式加工输入数据
每一个输入都会影响嵌套部分中的参数,因此过去的输入会通过改变嵌套参数的方式影响未来的输出

它是一种能够分析一维数据序列或时间数据流的神经网络,适用于输出依赖于以前计算的应用程序
但在模型训练学习中,因为嵌套过程很多,经常造成梯度爆炸,受此限制,RNN在一段时间内并没有得到很好的应用
后来新出现的LSTM架构,重新激活了RNN的应用
LSTM比起RNN,新增了一个“遗忘机制”,对于过去数据的参数影响,每次循环会通过一次权重判断,评判过去数据的影响是否还具有价值,有价值就保留,没有价值就将其遗忘。
因此LSTM克服了梯度爆炸的问题,且在记忆方面和建立时间数据依赖性上有很好的表现
RNN的使用:
1.RNN based health indicator(RNN-HI)
采集到的频域数据,通过related-similarity(RS)方法,计算当前数据初始数据点的数据相似度,根绝计算出的关联性和单调性进行数据特征提取,并将其作为RNN的输入
然后由RNN嵌套循环输入数据,输出数据,最终评估该轴承的RUL
实验证明该模型方法可行,而且性能优于基于SOM的方法
2.LSTM和一维CNN结合
该模型架构组成包括,一维CNN层,最大池化层,LSTM层,并最后采用softmax函数作为最终分类手段
通过实验,该架构的最优准确度达到了99.6%
3.a deep recurrent neural network (DRNN)
具有堆叠的递归隐藏层和LSTM单元
采用均方误差作为损失函数,并采用随机梯度下降法作为模型学习计算优化器
此外,还采用了自适应学习来提高训练性能
在1,750 rpm和1,797 rpm的测试集上,该模型方法的平均准确率分别为94.75%和96.53%
RNN的优势:
1.它是一个有历史记忆的网络,过去的参数和输入,能对未来的输出造成影响
2.能够建模时间依赖性
3.能够接收可变长度的输入:由于网络在理论上是可以无限循环的,它是一种嵌套的模式,因此可以接受可变长度的输入
RNN的缺陷:
1.由于梯度消失/爆炸导致的频繁学习问题:由于循环网络过于庞大,并且信息之间相关联度很高,在模型训练学习的时候,经常会出现数据计算量爆炸的情况
(5)Generative Adversarial Network (GAN)
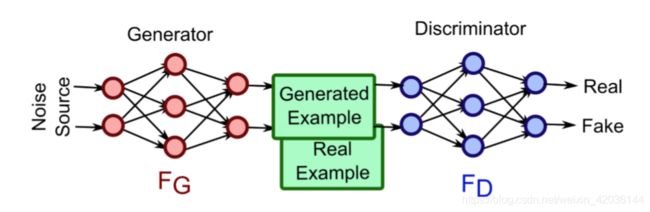
该网络最初设计是为了生成模拟真实照片的图像,网络模型由一个生成器和一个鉴别器组成
生成器用于模拟给出的输入数据,生成一个“假的”数据信号;生成器的输出为一个加工假信号,一个原始真信号,将这两个信号传给鉴别器,作为鉴别器的输入;鉴别器需要学习分辨出两个数据信号,哪个是真正的原始数据,哪个是经过加工模拟的虚假数据
此处对抗就是指生成器和鉴别器的对抗,生成器需要学习精进“造假”的技术,不能让鉴别器识别出自己造出的信号为假;鉴别器则需要增强鉴别能力,精准鉴别出哪个是原始信号,哪个是加工的假信号
在普遍情况下,数据会显现出一种不平衡性,也就是大多数情况下,设备是健康良好的,只有极少数的时候,设备会呈现故障状态,这就导致了数据的不平衡。而GAN强大的数据生成能力,就能很好地解决这种情况,经过训练,最终生成平衡地数据
通常应用于标签数据稀缺应用程序中的数据扩充(平衡数据),或以半监督的方式应用于分类问题
GAN的使用:
1.deep convolution GAN (DCGAN) with imbalanced dataset
生成器和鉴别器各由4层卷积层组成,使用的数据集是原始且不平衡的振动数据
经过DCGAN网络对抗学习,最终得到一个数据平衡的数据集。将处理过数据集作为输入传输给SVM来进行故障诊断分类
实验证明,DCGAN平衡数据的效果,比其他方法更优秀,包括随机过采样、随机欠采样和合成少数过采样技术
2.categorical adversarial autoencoder(CatAAE)
该方法主要依靠GAN强大的数据生成能力和数据分类鉴别能力,通过对抗性的训练过程来训练编码器
经过在不同信噪比环境下测试,CatAAE的性能要优于K均值算法
GAN的优势:
1.使用方便,在转移该技术模型到不同领域时,几乎不用做任何修改
2.不会引入确定性偏差
3.训练不需要蒙特卡洛近似
4.不一定需要已标注的数据训练,网络可以根据数据中的规律,推断出数据的类型
GAN的缺陷:
1.训练是不稳定的,它需要找到一场比赛的纳什均衡
2.很难学会生成离散数据,比如文本
(6)Deep Learning based Transfer Learning
ML和DL模型训练,经常需要大量的已标注数据,但在实际情况下,这样的数据却很难得到,主要有三个方面的困难:
1.要获得故障数据,必然要让机器在故障的情况下,继续运行,而这可能会造成较为严重的后果
2.无法确定机器要花费多久才会故障,在机器故障,获取数据之前,可能会需要耗费大量的时间
3.操作条件以及环境的差异都会造成数据的大幅度变化,很难获得不同条件环境下的大规模数据
当前大多共享使用的数据都是在实验里获取的,这导致数据往往缺少真实性,很多在实验室数据中准确率很高的模型方法,一到真实环境下,就变得乏力
因此需要一种迁移研究,收集数据中不变的根本特性,把在实验室数据中获取的数据特征,迁移到真实环境中去
迁移学习的使用:
1.domain adaptation
域适应方法通过探索领域不变特征,建立了从源领域到目标领域的知识转移,它利用源域的标记数据和目标域的未标记数据,减小两个域之间的分布差异
将域适应方法和当前已有的优异DL方法结合起来,就能在保持非凡的自动特征学习能力的同时赋予了领域迁移能力
2.WDCNN和AdaBN结合
WDCNN的第一层卷积层中,用到了大小对64X64的大卷积核,有强大的抗频域噪声能力
WDCNN提取目标域信号的均值和方差,作为输入信号传输给AdaBN,以实现域适应
实验测试时,用CWRU数据集中的一种操作情况下的数据训练WDCNN,而用另一种情况下的数据测试验证它的分析检测能力。实验结果得到,该模型平均的准确率达到了95.9%,超过了FFT-DNN方法(78.1%)
(7)一些其他方法
1.Variational Autoencoders
它使用变分推断来生成数据的潜在表示形式,然后对潜在变量和数据本身强加一个分布
该方法拥有数据降维的能力,它能从高维数据中提取特征,从而生成一个相关度高,有效性强的低维数据
研究实验证明,该方法的降维能力和期望已经超过了PCA方法
2.Capsule Neural Networks
它具有较强的通过胶囊模块识别特征位置和方位关系的能力,同时,该模型结构相对简单,参数较少,显著提高了其泛化能力
3.Siamese Neural Networks
该模型设计用于将签名验证作为图像匹配问题来解决
实际使用时,需要将相同或不同类别的样本对纳入其中,模型通过测量两个特征向量输出的距离来确定它们的相似性
由于签名认证,成功失败都是一次性的,因此该方法主要钻研一次性检测能力,而不是多次检测准确率
用于故障轴承诊断的深度学习算法讨论
1.自动提取特征和自动学习
在ML中,特征的提取需要人工操作,并且要求该人员拥有特定领域的专业知识,这导致ML算法在实际使用中所花费的时间成本和人力成本过高
DL算法对比ML算法,除了准确率大量提升以外,最重要的进步,是特征提取和学习自动化
DL自动化即降低了实验的成本,也加速了实验的进程和模型的性能
2.准确率不能作为判断模型性能的唯一指标
准确率一直是判断模型性能的首要指标,但在实际应用中,单指标判断方法很多时候显得片面。有多个现实原因和要求,证明不能只用准确率作为判断模型性能的唯一指标
(1)模型应用范围要广
有些DL模型在某个特定环境下的准确率能达到99%,但一旦实验条件改变,信噪比发生变化,准确率就会大幅度下滑。在实际使用中,环境是多变的,考察一个模型性能的时候,判断它在多个环境下,是否还能保持高准确度非常重要
(2)不平衡采样
在数据采集的过程中,设备故障的情况是极少的,更多时候设备处于健康状态,这就导致了样本数据的严重不平衡,健康数据和故障数据的比例远远达不到1:1。应该引入其他指标,如精度、召回率和f1评分,以提供更多的细节来评估故障识别网络的可靠性
此外,由于采样数据有限,采集的数据不一定能包含实际设备故障的全部或者大部分特征。在这种情况下,只使用准确率这单一指标就显得有些不妥。
(3)数据随机性
不同的模型方法,使用的数据集不同,提取的数据特征特点不同,数据集所处环境也不同。就算是用的同一个数据集,其中用来学习和测试验证性能的具体数据,数据量大小和比例都不一样。
条件不同,实验得出的性能肯定有差异,这时就需要更多方面的性能指标去阐述模型的性能
(4)准确性饱和
现有的大多算法,基本上在各自的数据集上,准确度都能达到95%以上。如果只看准确度,很难区分出多个算法之间的性能差异。并且在实验室采取的,或者人工造成设备故障的数据,有个通用的毛病是数据不够真实。在这种数据下达到的高准确率模型,在实际的应用中不一定能够保持好的性能,要考察一个模型的性能,还需要测试该模型是否能在多个环境下保持高的准确率。
算法选择的建议,遇到的挑战以及未来前进的方向
1.算法选择的建议
(1)根据环境选择
在室内,噪音较小,简单的ML算法就足够了,有较好的准确率,并且效率高
如果是在室外,或者噪音比较多,就要用DL算法,DL比起ML算法,有更好的抗噪能力
(2)根据传感器选择
CNN善于处理二维的数据,如果要使用CNN,那就要用两个垂直的传感器采集数据
反过来也一样,如果现场即能测量设备振动信号,又能测量设备温度,那就可以选择能处理多物理特性的网络,最大限度地完整利用数据
(3)根据数据选择
如果数据量较小,可以考虑使用ML即可
数据量较大,就用DL算法,充分利用大数据的优势,提高算法性能和整体准确率
数据不平衡的情况,可以使用GAN网络进行数据的扩充,数据平衡之后,再把数据作为神经网络的输入进行学习
2.遇到的挑战
(1)知识特征迁移
现有的数据有很多是在实验室获取的,有些甚至是人工造成的故障,与真实的环境相差甚远。因此需要知识迁移,把实验室中提取到的特征,训练好的模型,迁移到现实数据中,实现模型的泛用
(2)有限的被标注数据
有标注的数据在当前环境中是少数,更多的时候,是直接采集的一大堆没有标注的原始数据。逐个给数据标注实在是太费时间和成本,而且就算人工标注,也很难判断某个轴承在当前时刻有怎么样的损坏,属于哪一个类别,这就需要模型要有给未标注数据分类,直接处理未标注数据的能力
(3)数据不平衡
设备多数情况下是健康良好的,只有极少数情况下才处于故障状态,因此健康数据和故障数据的比例是严重不平衡的。这时需要采用类似GAN的算法,对原始数据进行模仿填充,把不平衡数据填充为平衡数据
(4)噪声数据
在真实的情况环境下,采集的数据除了被测轴承的振动外,还会有各式的噪声混杂在一起。进行学习的模型必须要具有抗噪能力才能精准地获得真正地数据
3.未来方向
(1)迁移学习
把在实验室数据中训练得到的数据特征,转移到现实情况中,实现同一个模型可以在实验室中训练,在现实条件下测试检验使用
(2)半监督学习
当前标记数据有限,半监督学习可以充分利用有限的标记数据和大量的无标签数据
(3)数据扩充
使用类GAN的方法,对少量的或者不平衡的数据进行扩充,得到比例平衡的大量数据
(4)小样本学习
另一种解决数据不足的问题,更快更效率地对少量数据进行学习
(5)可解释性
对已有的模型的原理进行更好的解释,增强模型的可改写性
(6)传感器融合
部署多种类型的传感器,如测压元件、电流传感器、声发射传感器等,通过对数据地多方面检测,获取数据地在不同领域地多个特征,充分利用数据的同时,也缓解了噪声对数据的影响