【Python】Windows10+RTX-3080+安装Tensorflow2-gpu版本成功安装指南(2020.12更新)
文章目录
-
-
- 前言
- 一、安装Anaconda
- 二、查看驱动
- 三、安装CUDA
- 四、安装cuDNN
- 五、测试CUDA
- 六、tensorflow安装
-
前言
台式机换了个RTX-3080的显卡,要重新装机并配置tensorflow的环境,踩了超多的坑,现在记录一下成功的经历,真的太不容易了…我系统用的Windows,网上大多数人用的都是Linux系统,但是我不想再花时间去学一个系统了。网上说30系列显卡只支持cuda11及以上,这里也不尝试cuda10了。而且我之前自己搭网络用的tf2.0,本文也不尝试安装tf1.0的版本了。先列出我最后成功的版本:
- 系统:Windows10
- 显卡:RTX-3080
- 驱动:456.43
- cuda:CUDA11.1.0_win10_network
- cudnn: cudnn-11.1-windows-x64-v8.0.5.39
- tensorflow:tf-nightly-gpu 2.5.0.dev20201217
一、安装Anaconda
打开清华镜像站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
我下了个最新的版本:Anaconda3-2020.11-Windows-x86_64.exe
安装过程,我这次做出的改动有:
1.安装Install for:“All Users”
2.直接自动添加环境变量了,即勾选了“Add Anaconda3 to the system PATH environment variable”
二、查看驱动
RTX3080采用了新的Ampere架构GA102-200,那么显卡驱动也必然是需要最新的,可以参考cuda与驱动对应的关系:

想要装CUDA 11.1的话,驱动版本要在456.38以上。想要看自己的驱动版本的话,可以在cmd中输入:
nvidia-smi
可以看到驱动版本是456.55,还显示了CUDA版本为11.1。

也可以不提前安装驱动,CUDA11安装里面自带了驱动,因为我后面卸载重装了,就直接用的CUDA11安装的驱动(自动安装的版本为456.43),如下所示:

三、安装CUDA
-
到链接: 英伟达官网下载对应的CUDA版本。
我下载的版本是CUDA11.1.0 ,选择"Windows;x86_64;10;exe(network)" -
安装CUDA:双击执行下载的exe文件,会先解压文件到临时目录(不是安装目录),保持默认即可.【我不知道可不可以下到别的里面,就照着博客下了】

- 这里需要选择自定义安装:
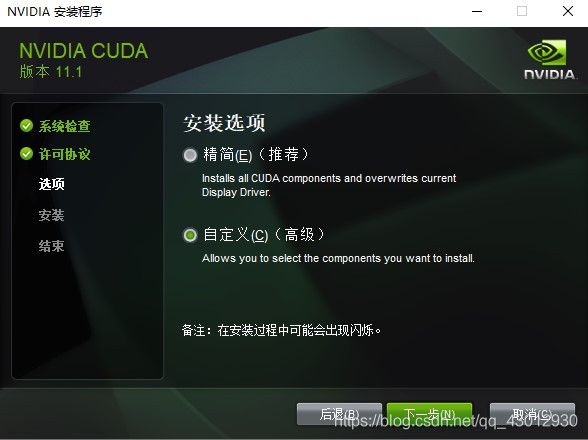
- 自定义安装选项,不勾选“Visual Studio Integration”,勾选的话后面会有个什么提示,所以又退回这步不勾选了。
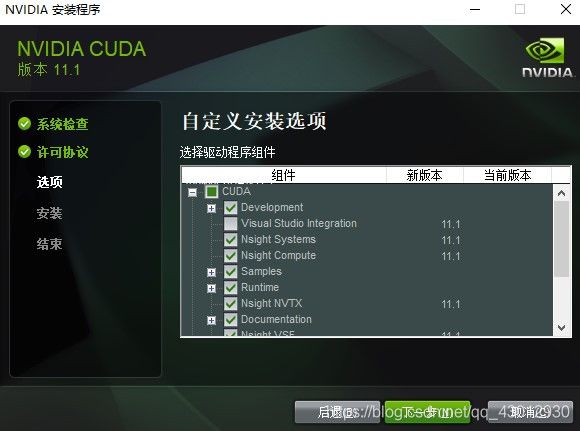
- 这三个地址十分重要,后续我们将进行环境变量的配置,不要改变路径。
- 之后等待安装,遇到了下面的情况

Installed:
- Nsight Monitor
Not Installed:
- Nsight for Visual Studio 2019
Reason: VS2019 was not found
- Nsight for Visual Studio 2017
Reason: VS2017 was not found
- Nsight for Visual Studio 2015
Reason: VS2015 was not found
- Integrated Graphics Frame Debugger and Profiler
Reason: see https://developer.nvidia.com/nsight-vstools
- Integrated CUDA Profilers
Reason: see https://developer.nvidia.com/nsight-vstools
不知道有没有什么问题,先继续往下吧。
- 配置CUDA环境变量
网上很多说要环境变量>系统变量>Path中手动添加路径的,我整合了好多条:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin【自动配的】
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\libnvvp【自动配的】
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\extras\CUPTI\lib64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\common\lib\x64
但最后发现,其实不用手动配置,用自动配的前两条也可以运行程序啊…不知道为什么那么多人都说要配置路径…
- 我们可以验证一下cuda是否成功,按win+R 输入cmd,输入命令:
nvcc -V
得到如下的结果:
四、安装cuDNN
到链接: 英伟达.下载与CUDA 11.1 对应的cuDNN v8.0.5,这里需要我们注册一个账号,然后登录下载,下载时一定注意与CUDA的版本对应。
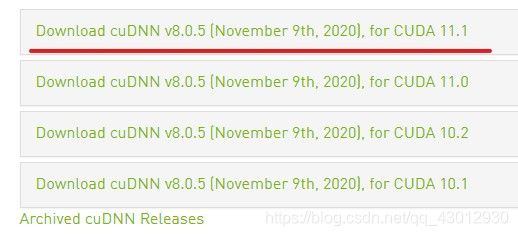
下载之后,解压缩,将CUDNN文件夹中的各自的bin、clude、lib文件夹中的内容,直接复制添加到CUDA的刚刚安装目录的对应相同名字的文件夹下。
五、测试CUDA
网上还有个测试CUDA的版本,cmd中输入
cd /d C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\extras\demo_suite
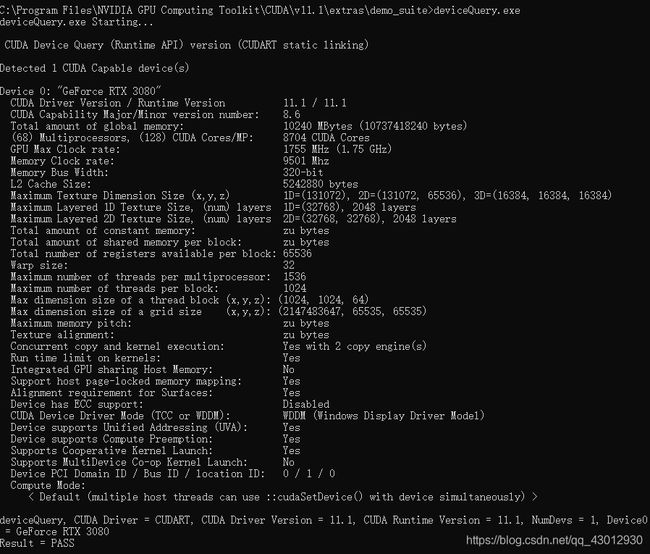
再执行deviceQuery.exe,得到以下界面
再运行bandwidthTest.exe :
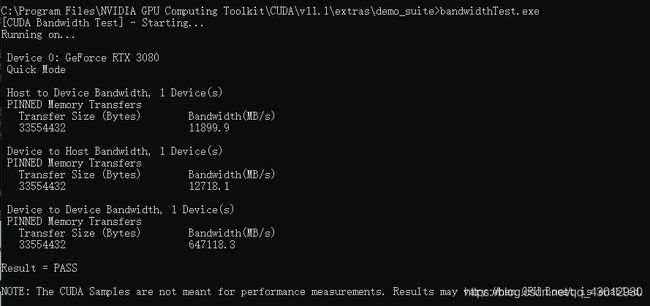
如果以上两步都返回了**Result=PASS**,那么就算成功啦。
六、tensorflow安装
我安装了网上广为流传的tensorflow2.4.0RC2版本后跑测试网络会报下面的错误,我尝试了各种各样的方法(甚至把所有驱动卸载了重装,T.T 其实没必要的),都没解决。
2020-12-20 11:15:42.219809: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
Epoch 1/10
2020-12-20 11:15:42.487403: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublas64_11.dll
2020-12-20 11:15:43.135561: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublasLt64_11.dll
2020-12-20 11:15:43.144181: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll
2020-12-20 11:15:43.777376: E tensorflow/stream_executor/cuda/cuda_dnn.cc:336] Could not create cudnn handle: CUDNN_STATUS_NOT_INITIALIZED
2020-12-20 11:15:43.779852: E tensorflow/stream_executor/cuda/cuda_dnn.cc:340] Error retrieving driver version: Unimplemented: kernel reported driver version not implemented on Windows
2020-12-20 11:15:43.783883: E tensorflow/stream_executor/cuda/cuda_dnn.cc:336] Could not create cudnn handle: CUDNN_STATUS_NOT_INITIALIZED
2020-12-20 11:15:43.786378: E tensorflow/stream_executor/cuda/cuda_dnn.cc:340] Error retrieving driver version: Unimplemented: kernel reported driver version not implemented on Windows
Traceback (most recent call last):
File "test1.py", line 37, in
model.fit(train_x,train_y,epochs=10,batch_size = 100)
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\keras\engine\training.py", line 1100, in fit
tmp_logs = self.train_function(iterator)
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\def_function.py", line 828, in __call__
result = self._call(*args, **kwds)
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\def_function.py", line 888, in _call
return self._stateless_fn(*args, **kwds)
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\function.py", line 2943, in __call__
filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\function.py", line 1919, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\function.py", line 560, in call
ctx=ctx)
File "D:\Anaconda\envs\tf2-gpu\lib\site-packages\tensorflow\python\eager\execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node sequential/conv2d/Conv2D (defined at test1.py:37) ]] [Op:__inference_train_function_785]
Function call stack:
train_function
最后我发现直接装 tf-nightly-gpu 版本就行了(害,之前折腾那么久)
pip install tf-nightly-gpu -i https://mirrors.aliyun.com/pypi/simple
最后运行了测试代码,运行时长为:23.91809916496277 s,自己笔记本电脑RTX-1650的运行时长为:42.80683422088623 s,还是快了不少…可能是nightly版本的问题吧,等以后正式版出来后性能应该会提升更多?先这样用着吧,反正比我的小破本快很多了。另外试了个自己的程序运行时长分别为1129.412543296814s,1843.4407227039337 s,还是快了一些的。
附上测试代码:
import tensorflow as tf
import time
begin = time.time()
n_classes = 10
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(
32,(5,5),activation = tf.nn.relu, input_shape = (28,28,1)),
tf.keras.layers.MaxPool2D((2,2),(2,2)),
tf.keras.layers.Conv2D(64,(3,3),activation = tf.nn.relu),
tf.keras.layers.MaxPool2D((2,2),(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024,activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(n_classes)
])
model.summary()
mnist = tf.keras.datasets.mnist
(train_x, train_y),(test_x,test_y) = mnist.load_data()
train_x = train_x/255. *2 -1
test_x = test_x/255. *2 -1
train_x = tf.expand_dims(train_x, -1).numpy()
test_x = tf.expand_dims(test_x, -1).numpy()
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-5),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_x,train_y,epochs=10,batch_size = 100)
model.evaluate(test_x, test_y)
end = time.time()
print('It cost',end-begin,'s')