pandas学习笔记(4)
时间序列(TimeSeries)
date = pd.date_range(start='2019-01-1', periods=5, freq='d')
print(date)

s= pd.Series(np.random.rand(5), index=date)
print(s)

print(s['2019-01-01'])
print(s['20190101'])
print(s['2019-1'])
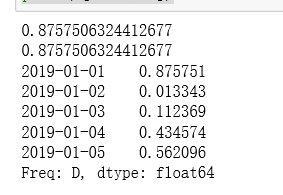
print(s['201901'])

drop_duplicates:去除重复项
c=pd.DataFrame({
'call':[2011,2011,2008,2013,2013],
'age':[5,4,3,2,1],
'sex':['M','F','M','F','M'],
'num':[123,123,123,123,45]
})
print(c)
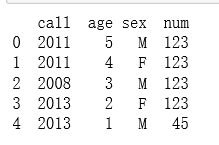
print(c.drop_duplicates(['call']))

分类(Categoricals)
data_list = pd.DataFrame(np.random.randint(0, 20, size=10),columns=['A'])
data_list['B']=['M','F']*5
print(data_list)

bins = [-1,10,21]
new_list=pd.cut(data_list['A'], bins)
print(new_list)
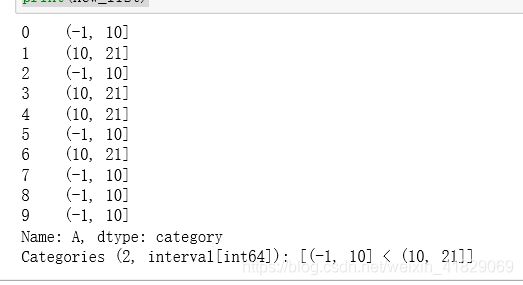
print(pd.value_counts(new_list))

data_list['C'] = pd.cut(data_list['A'],bins, labels=['good','bad'])
print(data_list)

plot()
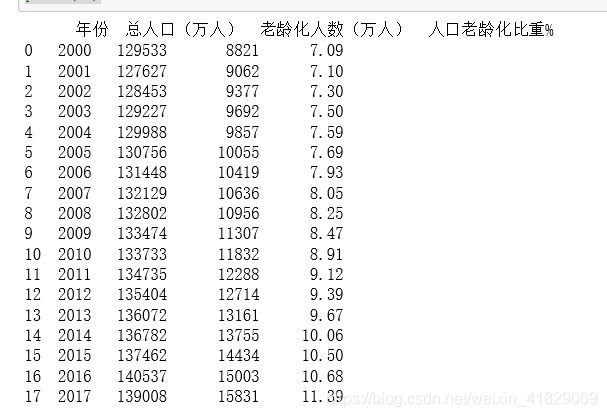
f=open(('D:/学习/day-data/数据.csv'))
df=pd.read_csv(f)
print(df)
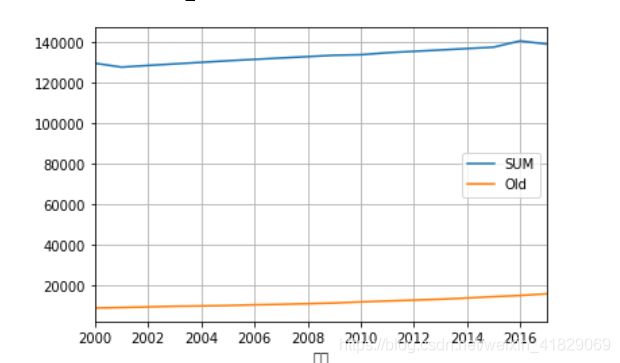
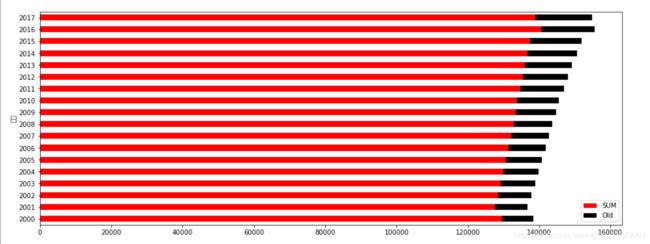
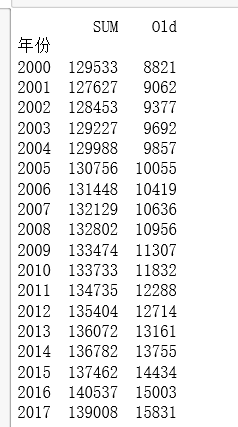
new_df=pd.DataFrame(np.array(df[['总人口(万人)','老龄化人数(万人)']]),index=df['年份'],columns=['SUM','Old'])
print(new_df)
new_df.plot(grid=True)
new_df.plot(kind='barh', stacked=True, figsize=[16,6],colormap='flag')