KOBE FOREVER 基于opencv人脸分割技术,Augmentor数据增量与随机森林的人脸识别技术——So,Is he? Is Kobe
只要还有一个人记得,他就永远活在这个世界 2021-01-27
2020-01-27-2021-01-27
科比的伟大不需要我博主多说,也许看这篇文章的人更多的关心的并不是核心技术而是看我怎么去写科比。其实我并不会去过多的去写科比,因为他依然在这个世界的某个角落,或者说在每一位球迷的心里。
没有一个人不讨厌科比
没有一个人不喜欢科比
博主不能做什么,只是希望用上自己所学的知识,让科比被更多人记住,也不会再出现朋友圈中出现的乌龙而已罢了。
好了,言归正传!
本文主要运用了opencv中自带的人脸识别模型对球星的头部进行剪切提取,然后将提取出的头部图片进行特征提取,标签拆分,在增大数据量的基础上选用随机森林模型进行训练与预测,最后得到验证结果。
一、数据的整合
本文因为时间紧迫,所以临时选取了曾经的四大分位以及篮球之神乔丹与小皇帝詹姆斯这六位球员(其实就是朋友圈中最容易混淆的几位球员)的图片,每位球员各50张图片,共300张图片进行分析,原数据如下:
在操作过程中不可能一个文件夹一个文件夹去读取操作,所以希望将这六个文件夹的数据放在一个文件夹下,在python中如下操作:
import os##导入os库,用于读取文件夹子目录
from PIL import Image#导入Image,用于读取图片和处理图片
import matplotlib.pyplot as plt#用于读取图片
#对数据集进行打姓名标签
name=os.listdir('C:\\Users\\dell\\Desktop\\球星\\')#原始文件夹每一个文件夹的名称
for i in range(len(name)):##读取每个文件夹下的文件夹名称
picture=os.listdir('C:\\Users\\dell\\Desktop\\球星\\'+name[i])#读取每个文件夹下的子文件夹
for j in range(len(picture)):#读取每个子文件夹的图片
a=Image.open('C:\\Users\\dell\\Desktop\\球星\\'+name[i]+'\\'+picture[j])#打开每一张图片
a.save('C:\\Users\\dell\\Desktop\\球星1\\'+str(j)+'_'+name[i]+'.png')
#重新命名图片名称,打上每一个人的标签,即标准化图片名称(数量_球星名.png)然后导出到一个文件夹下
其结果如下:

至此完成图片的整合部分。
二、面部图片的剪裁
原始的图片噪音太多,而我们主要是需要面部的特征来识别球星,所以,这里采用opencv中自带的一个人脸面部定位的模型进行剪裁图片,得到每张图片的面部小图
import cv2#导入cv2库,主要目的是用库里面的训练好的模型进行人脸的割取
a=os.listdir('C:\\Users\\dell\\Desktop\\球星1\\')#每一张图片的名字
for i in a:
img = cv2.imread("C:\\Users\\dell\\Desktop\\球星1\\"+i)#用cv2读取每一张图片
img1=Image.open('C:\\Users\\dell\\Desktop\\球星1\\'+i)#用Image打开每一张图片
classifier = cv2.CascadeClassifier("E:\\1\\Lib\\site-packages\\cv2\\data\\haarcascade_frontalface_default.xml")#cv2中的自有的人脸识别模型
faces = classifier.detectMultiScale(img, scaleFactor=1.1, minNeighbors=3, minSize=(200, 200))#对人脸进行识别,输出人脸所在的方框坐标
for face in faces:#循环读取坐标
x, y, w, h = face#坐标点
corp=img1.crop([x,y,x+h,y+w])#对人脸进行裁剪
if len(faces) > 0:#如果有坐标点,也就是识别出来有人脸
corp.save('C:\\Users\\dell\\Desktop\\球星2\\'+i)#进行保存
得到的结果如下:

这样一来就得到了所有球星的面部小图,但是因为原始图片的问题,300张图在剪切操作后只剩下不到100张图,因为在面部剪切时,得不到面部特征的时候不会输出图片,所以考虑增大图片量。
三、数据增量
在这里采用Augmentor库进行数据的增量处理,操作过程如下:
import Augmentor#导入数据增量的库,因为原始数据太少,所以需要数据增量
p=Augmentor.Pipeline('C:\\Users\\dell\\Desktop\\球星2\\')#在文件夹下创建一个存放输出文件的文件夹
p.rotate(probability=0.1,max_left_rotation=25,max_right_rotation=10)#对图片进行旋转
p.flip_left_right(probability=0.8)##左翻转
p.flip_top_bottom(probability=0.4)#右翻转
p.crop_by_size(probability=0.3,width=100,height=100)#进行图片的剪裁
p.sample(2000)#决定增量的图片为2000张
得到结果如下:
这下数据量就有2000张图了,就可以开始建模操作了。
四、建立模型
在建立模型之前需要对每张图片的标签进行提取,这里运用正则库将其图片名中的类别提取出来
import re#导入正则库来分割图片名字的类别标签
import pandas as pd#数据处理的pandas库
label=[''.join(re.findall('球星2_original_.*?_(.*?)\.',i)) for i in os.listdir('C:\\Users\\dell\\Desktop\\球星2\\output\\')]#分割类别标签
得到结果如下:
得到类别标签后,将每张图片给标准化后变成二维矩阵,即把每张图片导入进来后进行灰度处理,尺寸处理后将图片维度拉成1×图片长*宽的一条矩阵,然后把每张图片放进一个大矩阵中进行分析。
import numpy as np#导入数据处理库
zo=np.zeros((len(label),57600))#创建一个和label一样长,57600列的空矩阵用来装数据(240*240=57600)
a=os.listdir('C:\\Users\\dell\\Desktop\\球星2\\output\\')#输出文件夹的子图片目录
for i in range(len(a)):#循环读取
#读取图片并且转化为灰度图片,转化格式为240*240,且转化维度为(1,576000)
zo[i]=np.array(Image.open('C:\\Users\\dell\\Desktop\\球星2\\output\\'+a[i]).convert('L').resize((240,240))).reshape((1,57600))
结果如下:

其中每一行就是一张图片的特征。
接下来划分训练集测试集:
from sklearn.model_selection import train_test_split#测试集训练集的划分
x1,x2,y1,y2=train_test_split(zo,label,test_size=0.2)#进行划分
接下来进行模型的建立:
from sklearn.ensemble import RandomForestClassifier#随机森林
from sklearn.metrics import accuracy_score,confusion_matrix#准确率和混淆矩阵
R=RandomForestClassifier().fit(x1,y1)#模型训练
accuracy_score(y2,R.predict(x2))#模型预测精度
confusion_matrix(y2,R.predict(x2))#混淆矩阵
得到的结果如下:
准确度:

混淆矩阵:

看得出来效果很不错。
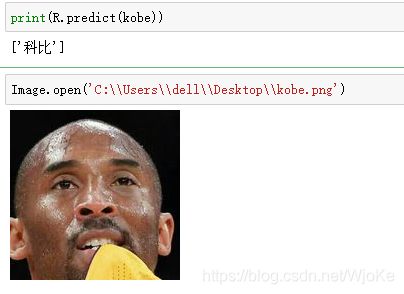
最后测试一下到底能不能将老大给识别出来!!!
#测试
kobe=np.array(Image.open('C:\\Users\\dell\\Desktop\\kobe.png').convert('L').resize((240,240))).reshape((1,57600))
print(R.predict(kobe))
Image.open('C:\\Users\\dell\\Desktop\\kobe.png')