进化计算-进化策略(Evolutionary Strategies,ES)前世今生与代码共享

获取更多资讯,赶快关注上面的公众号吧!
文章目录
-
- 24.1 发展
- 24.2 与遗传算法的异同
- 24.3 不可重组进化策略
-
- 24.3.1 二元ES:(1+1)-ES
- 24.3.2 多元ES:( μ + λ \mu+\lambda μ+λ)-ES和( μ , λ \mu,\lambda μ,λ)-ES
- 24.4 可重组进化策略
- 24.5 自适应进化策略
-
- 24.5.1 各向同性自适应
- 24.5.2 非各向同性自适应
- 24.5.3 相关自适应
- 24.6 开源代码
-
- 24.6.1 Normal-ES
- 24.6.2 Adaptive-ES
【智能优化算法系列】
- 群体智能和进化计算-介绍
- 群体智能之粒子群优化(PSO)
- 群体智能之人工蜂群算法及其改进(ABC)
- 群体智能之蜘蛛猴优化算法(SMO)
- 群体智能优化算法之蚁群优化算法(ACO)
- 群体智能优化算法之布谷鸟搜索(CS)
- 群体智能优化算法之萤火虫群优化算法(Glowworm Swarm Optimization,GSO)
- 群体智能优化算法之萤火虫算法(Firefly Algorithm,FA)
- 智能优化算法天牛须搜索算法(Beetle Antennae Search Algorithm,BAS)
- 群体智能优化算法之蝙蝠算法(Bat Algorithm,BA)
- 群体智能优化算法之人工鱼群优化算法(Artificial Fish Swarm Algorithm,AFSA)
- 群体智能优化算法之蟑螂算法((Cockroach Swarm Optimization,CSO)
- 群体智能优化算法之猫群算法(Cat Swarm Optimization)
- 群体智能优化算法之细菌觅食优化算法(Bacterial Foraging Optimization Algorithm,BFOA)
- 群体智能优化算法之烟花算法(Fireworks Algorithm,FWA)
- 群体智能优化算法之总结
- 进化计算-进化算法
- 进化计算-遗传算法-入门级最好教程
- 进化计算-遗传算法之史上最全选择策略
- 进化计算-遗传算法之史上最直观交叉算子(动画演示)
- 第二十一章 基于鹰栖息(eagle perching)的无模型优化
- 群体智能优化算法之萤火虫算法(Firefly Algorithm,FA)-看了还不会提刀来找我
- 群体智能优化算法之鲸鱼优化算法(Whale Optimization Algorithm,WOA)
- (本文)进化计算-进化策略(Evolutionary Strategies,ES)前世今生与代码共享
ES的首个版本在每一代上只操作一个子代,因为那时并没有种群对象。
—Hans-Paul Schwefel
24.1 发展
上世纪60年代,欧洲人在柏林工业大学(Technical University of Berlin)率先尝试了EAs,当时有三名学生试图在风洞中找到最理想外形,以减少空气阻力。这些学生Ingo Rechenberg, Hans-Paul Schwefel和Peter Bienert,发现使用解析法很难解决他们的问题。因此,他们想出了一个主意,尝试随机改变外形,选择效果最好的,然后重复这个过程,直到找到解决问题的好办法。
Rechenberg的第一本关于进化策略(ES)的出版物,也被称为进化策略,出版于1964年。有趣的是,第一个ES实现是实验性的,由于计算资源不足,无法进行高保真度仿真,只能通过实验获得适应度函数,并在物理硬件上实现变异。Rechenberg在1970年获得了博士学位,之后以书的形式出版了他的作品。Schwefel于1975年获得博士学位,随后写了几本关于ES的书。自1985年以来,他一直在多特蒙德大学执教。
24.2 与遗传算法的异同
进化策略和遗传算法算是同时代的产物,但是早期的ES只是简单的二元形式(每代一个个体),Schwefel首先在计算机上模拟了不同版本的ES,之后又提出了多元ES/可重组ES和自适应ES。早期的ES与二元GA实际上存在着本质的不同,主要体现在两个方面:
- ES使用实数值进行编码,而非0-1编码;
- 早期的ES没有类似交叉这样的算子。
除此之外,早期ES工作原理其实是和只有选择和变异的实值遗传算法是非常类似的,因此在意识到两者之间惊人的相似之处之后(虽然在相隔非常遥远的两个地方分别提出),最近的ES研究已经引入了类交叉算子。在接下来的小节中,我们将描述这些方法。
24.3 不可重组进化策略
首先描述部分不使用重组算子的不同ES。
24.3.1 二元ES:(1+1)-ES
这是所有ES中最简单的形式,每一次迭代中,一个父代通过高斯变异算子 N ( 0 , σ ) \mathbf{N}(0, \sigma) N(0,σ)生成一个子代,下面给出了最小化问题的伪代码。
Step1:选择一个初始解 x \mathbf{x} x和变异强度 σ \sigma σ
Step2:通过变异创建一个解:
y = x + N ( 0 , σ ) \mathbf{y}=\mathbf{x}+\mathbf{N}(0, \sigma) y=x+N(0,σ)
Step3:如果 f ( y ) f(\mathbf{y}) f(y)< f ( x ) f(\mathbf{x}) f(x),则将 x \mathbf{x} x替换为 y \mathbf{y} y。
Step4:如果满足终止条件,算法停止,否则执行Step2。
这里所有的决策变量都以具有相同变异强度的正态分布进行变异从直观上看,该算法能否找到近似最优解在很大程度上取决于所选的 σ \sigma σ值。Rechenberg提出了著名的“1/5 success rule”,即变异强度需要在代与代之间不断被修改:
成功变异与所有变异的比率应该是1/5,如果比率大于1/5,则应增加变异强度,否则就降低变异强度。
如果变异的后代比父代的解更好,则将变异定义为成功的。如果观察到许多成功的变异,这表明解存在于搜索空间中的一个更好的区域。因此,应该增加变异强度,从而希望能找到更接近最优解的更好的解。通过计算n次试验中成功变异的数量Ps,Schwefel提出将因子 c d c_{d} cd=0.817用于 σ \sigma σ更新规则:
σ t + 1 = { c d σ t , if p s < 1 / 5 1 c d σ t , if p s > 1 / 5 σ t , if p s = 1 / 5 \sigma^{\mathrm{t}+1}=\left\{\begin{array}{ll} \mathrm{c}_{\mathrm{d}} \sigma^{\mathrm{t}}, & \text { if } p_{\mathrm{s}}<1 / 5 \\ \frac{1}{\mathrm{c}_{\mathrm{d}}} \sigma^{\mathrm{t}}, & \text { if } p_{\mathrm{s}}>1 / 5 \\ \sigma^{\mathrm{t}}, & \text { if } p_{\mathrm{s}}=1 / 5 \end{array}\right. σt+1=⎩⎨⎧cdσt,cd1σt,σt, if ps<1/5 if ps>1/5 if ps=1/5
24.3.2 多元ES:( μ + λ \mu+\lambda μ+λ)-ES和( μ , λ \mu,\lambda μ,λ)-ES
利用最优变异强度和1/5 success rule可以使得ES优于简单的蒙特卡洛方法,但是在多元ES中引入种群方法可以使ES更进一步。在ES中引入多个成员有两种方法,首先讨论“加法”策略,其中 μ \mu μ(>1)个父代通过仅使用变异来创建 λ \lambda λ个子代。如图1所示为其原理,下面给出其伪代码:
多元ES:( μ + λ \mu+\lambda μ+λ)-ES
Step1:初始化具有 μ \mu μ个解 x ( i ) , i = 1 , 2 , … , μ \mathbf{x}^{(i)}, i=1,2, \ldots, \mu x(i),i=1,2,…,μ的初始种群,和变异强度 σ \sigma σ。
Step2:创建 λ \lambda λ个变异解,每次生成第 j j j个子代时,都从 μ \mu μ个父代中随机选择一个 i i i:
y ( j ) = x ( i ) + N ( 0 , σ ) \mathbf{y}^{(j)}=\mathbf{x}^{(i)}+\mathbf{N}(0, \sigma) y(j)=x(i)+N(0,σ)
Step3:将父代和子代合并成一个新的父代种群 P P P, P P P中选择最好的 μ \mu μ个解,以保证种群大小不变:
P = ( ∪ j = 1 λ { y ( j ) } ) ∪ ( ∪ i = 1 μ { x ( i ) } ) P=\left(\cup_{j=1}^{\lambda}\left\{\mathbf{y}^{(j)}\right\}\right) \cup\left(\cup_{i=1}^{\mu}\left\{\mathbf{x}^{(i)}\right\}\right) P=(∪j=1λ{ y(j)})∪(∪i=1μ{ x(i)})
Step4:如果满足终止条件,算法停止,否则执行Step2。

图1 ( μ + λ \mu+\lambda μ+λ)-ES原理
对于许多优化问题来说,建议 λ / μ ≈ 5 \lambda / \mu \approx 5 λ/μ≈5。由于在选择操作中同时使用了父代种群和子代种群,因此( μ + λ \mu+\lambda μ+λ)-ES是一个精英算法。尽管保留精英是必要的,但这一步骤并不能控制精英主义的程度。在某些问题中,新的成功变异很难实现,在( μ + λ \mu+\lambda μ+λ)-ES中的搜索将停滞不前。为了避免出现这个问题,提出了一种新的( μ , λ \mu,\lambda μ,λ)-ES,它与( μ + λ \mu+\lambda μ+λ)-ES仅在Step3存在不同,不再是在选择之前将父代和子代组合,而是只使用子代,因而选择之前的种群 P P P为 P = ( ∪ j = 1 λ { y ( j ) } ) P=\left(\cup_{j=1}^{\lambda}\left\{\mathbf{y}^{(j)}\right\}\right) P=(∪j=1λ{ y(j)})。为了能够保证种群大小不变,需要满足 λ ≥ μ \lambda \geq \mu λ≥μ。通过这种方式,就忽略了父代个体,( μ , λ \mu,\lambda μ,λ)-ES取决于寻找更优子代的能力,因此( μ , λ \mu,\lambda μ,λ)-ES是一种非精英方法,图2为其原理。

图2 ( μ , λ \mu,\lambda μ,λ)-ES
如果从父代中选择部分较优的个体,剩余的从子代中选择,从而构成新的种群,这种策略通过人为控制的方式引入精英策略,可以认为是( μ + λ \mu+\lambda μ+λ)-ES和( μ , λ \mu,\lambda μ,λ)-ES之间一种很好的折中。要实现这种策略,可以为每个父代个体设置一个生命周期 k k k( ≥ 1 \geq 1 ≥1),当父代存活大于 k k k代时,选择过程中将不再考虑该个体,从而允许新的子代进入新的种群。当 k k k=1时,其实就是( μ , λ \mu,\lambda μ,λ)-ES,而当 k = ∞ k=\infty k=∞时就是( μ + λ \mu+\lambda μ+λ)-ES。
24.4 可重组进化策略
在可重组进化策略中,首先选择一组父代个体进行重组以寻找一个新解,之后对该解采用之前介绍的变异操作。重组时并不是选择两个父代或所有父代,而是随机选择 ρ ∈ [ 1 , μ ] \rho \in[1,\mu] ρ∈[1,μ]个父代,当 ρ = 1 \rho =1 ρ=1时说明没有重组。重组方式主要有两种:中间和离散。在中间重组算子中, ρ \rho ρ个选择的平均解向量计算如下:
y = 1 ρ ∑ i = 1 ρ x ( i ) \mathbf{y}=\frac{1}{\rho} \sum_{i=1}^{\rho} \mathbf{x}^{(i)} y=ρ1i=1∑ρx(i)
很明显,如果在每次重组中使用所有父代给体 ρ = μ \rho=\mu ρ=μ,该方式有聚集在当前种群中心聚集的趋势。在种群包含真正最优值的问题中,这可能是一个很好的策略。
在离散重组中,每个决策变量都是从 ρ \rho ρ个父代中随机选择的,例如可由下列四个解推导出一个离散重组解( ρ = μ \rho=\mu ρ=μ):
P a r e n t 1 : x 1 ( 1 ) x 2 ( 1 ) x 3 ( 1 ) x 4 ( 1 ) x 5 ( 1 ) x 6 ( 1 ) P a r e n t 2 : x 1 ( 2 ) x 2 ( 2 ) x 3 ( 2 ) x 4 ( 2 ) x 5 ( 2 ) x 6 ( 2 ) P a r e n t 3 : x 1 ( 3 ) x 2 ( 3 ) x 3 ( 3 ) x 4 ( 3 ) x 5 ( 3 ) x 6 ( 3 ) P a r e n t 4 : x 1 ( 4 ) x 2 ( 4 ) x 3 ( 4 ) x 4 ( 4 ) x 5 ( 4 ) x 6 ( 4 ) R e c o m b i n a n t : x 1 ( 2 ) x 2 ( 3 ) x 3 ( 4 ) x 4 ( 2 ) x 5 ( 4 ) x 6 ( 3 ) \begin{aligned} &\begin{array}{llllll} Parent1:& x_{1}^{(1)} & x_{2}^{(1)} & x_{3}^{(1)} & x_{4}^{(1)} & x_{5}^{(1)} & x_{6}^{(1)} \\ Parent2:& x_{1}^{(2)} & x_{2}^{(2)} & x_{3}^{(2)} & x_{4}^{(2)} & x_{5}^{(2)} & x_{6}^{(2)} \\ Parent3:& x_{1}^{(3)} & x_{2}^{(3)} & x_{3}^{(3)} & x_{4}^{(3)} & x_{5}^{(3)} & x_{6}^{(3)} \\ Parent4:& x_{1}^{(4)} & x_{2}^{(4)} & x_{3}^{(4)} & x_{4}^{(4)} & x_{5}^{(4)} & x_{6}^{(4)} \\ Recombinant:& x_{1}^{(2)} & x_{2}^{(3)} & x_{3}^{(4)} & x_{4}^{(2)} & x_{5}^{(4)} & x_{6}^{(3)} \end{array}\\ \end{aligned} Parent1:Parent2:Parent3:Parent4:Recombinant:x1(1)x1(2)x1(3)x1(4)x1(2)x2(1)x2(2)x2(3)x2(4)x2(3)x3(1)x3(2)x3(3)x3(4)x3(4)x4(1)x4(2)x4(3)x4(4)x4(2)x5(1)x5(2)x5(3)x5(4)x5(4)x6(1)x6(2)x6(3)x6(4)x6(3)
该算子类似于遗传算法中的均匀交叉过程,利用该方法可以得到已有解的不同决策变量组合。
完整的算法流程如下:
可重组ES: ( μ / ρ + λ ) − E S (\mu / \rho+\lambda)-ES (μ/ρ+λ)−ES
Step1:初始化具有 μ \mu μ个解 x ( i ) , i = 1 , 2 , … , μ \mathbf{x}^{(i)}, i=1,2, \ldots, \mu x(i),i=1,2,…,μ的初始种群,和变异强度 σ \sigma σ。
Step2:创建 λ \lambda λ个变异解,每个解使用从 μ \mu μ个父代中随机选择 ρ \rho ρ个按如下方式:
1. 通过 ρ \rho ρ个父代个体的中间重组或离散重组,计算重组解 y \mathbf{y} y。
2. 对重组解进行变异:
y ( j ) = y ( i ) + N ( 0 , σ ) \mathbf{y}^{(j)}=\mathbf{y}^{(i)}+\mathbf{N}(0, \sigma) y(j)=y(i)+N(0,σ)
Step3:将父代和子代合并成一个新的父代种群 P P P, P P P中选择最好的 μ \mu μ个解,以保证种群大小不变:
P = ( ∪ j = 1 λ { y ( j ) } ) ∪ ( ∪ i = 1 μ { x ( i ) } ) P=\left(\cup_{j=1}^{\lambda}\left\{\mathbf{y}^{(j)}\right\}\right) \cup\left(\cup_{i=1}^{\mu}\left\{\mathbf{x}^{(i)}\right\}\right) P=(∪j=1λ{ y(j)})∪(∪i=1μ{ x(i)})
Step4:如果满足终止条件,算法停止,否则执行Step2。
对于 ( μ / ρ , λ ) − E S (\mu / \rho, \lambda)-\mathrm{ES} (μ/ρ,λ)−ES,在上述算法的Step3中,只使用子代种群来创建新种群。
24.5 自适应进化策略
自适应是一种使进化算法更灵活、更接近自然进化的现象,在ES中引入自适应有三种不同的方式:
- 分层管理的基于种群的元进化策略
- 自适应的协方差矩阵(CMA)确定概率分布的变异
- 自适应控制参数的显式使用
元进化策略使用了两层的ES:顶层对策略参数(如变异强度)进行优化,然后再将策略参数用于优化底层的真实目标函数;第二种方法(CMA)记录一定迭代次数的种群历史,计算目标变量之间的协方差和方差信息,随后的搜索工作受到这些方差值的影响;这么我们主要讨论第三种自适应ES,其中策略参数(方差 σ i 2 \sigma_{i}^{2} σi2和协方差 C i j 2 C_{i j}^{2} Cij2)与决策变量一起显式编码,并在每一代中使用预定义的更新规则进行更新。基本上有三种不同的实现。
24.5.1 各向同性自适应
在这种自适应ES中,所有变量使用一个变异强度 σ \sigma σ,除了 n n n个对象变量外,种群成员还会用到策略参数 σ \sigma σ。决策变量和变异强度的对数更新规则如下:
σ ( t + 1 ) = σ ( t ) exp ( τ 0 N ( 0 , 1 ) ) x i ( t + 1 ) = x i ( t ) + σ ( t + 1 ) N i ( 0 , 1 ) \begin{aligned} \sigma^{(t+1)} &=\sigma^{(t)} \exp \left(\tau_{0} N(0,1)\right) \\ x_{i}^{(t+1)} &=x_{i}^{(t)}+\sigma^{(t+1)} N_{i}(0,1) \end{aligned} σ(t+1)xi(t+1)=σ(t)exp(τ0N(0,1))=xi(t)+σ(t+1)Ni(0,1)
其中 N ( 0 , 1 ) N(0,1) N(0,1)和 N i ( 0 , 1 ) N_{i}(0,1) Ni(0,1)是均值为0标准差为1的一维正太分布。参数 τ 0 \tau_{0} τ0为学习参数,应该设置为 τ 0 ∝ n − 1 / 2 \tau_{0}\propto n^{-1 / 2} τ0∝n−1/2,n为变量向量的维度。上述更新需要规则需要有一个 σ \sigma σ的初始值,可以设置为 σ ( 0 ) = ( x i ( U ) − x i ( L ) ) / 12 \sigma^{(0)}=\left(x_{i}^{(U)}-x_{i}^{(L)}\right) / \sqrt{12} σ(0)=(xi(U)−xi(L))/12.
24.5.2 非各向同性自适应
这里每个变量使用不同的变异强度 σ i \sigma_{i} σi,因此,这类自适应ES能够学习适应每个变量对目标函数的贡献不相等的问题。除了n个目标变量外,决策变量向量中还包含n个策略参数。决策变量和变异强度的对数更新规则如下:
σ i ( t + 1 ) = σ i ( t ) exp ( τ ′ N ( 0 , 1 ) + τ N i ( 0 , 1 ) ) x i ( t + 1 ) = x i ( t ) + σ i ( t + 1 ) N i ( 0 , 1 ) \begin{aligned} \sigma_{i}^{(t+1)} &=\sigma_{i}^{(t)} \exp \left(\tau^{\prime} N(0,1)+\tau N_{i}(0,1)\right) \\ x_{i}^{(t+1)} &=x_{i}^{(t)}+\sigma_{i}^{(t+1)} N_{i}(0,1) \end{aligned} σi(t+1)xi(t+1)=σi(t)exp(τ′N(0,1)+τNi(0,1))=xi(t)+σi(t+1)Ni(0,1)
其中 τ ′ ∝ ( 2 n ) − 1 / 2 \tau^{\prime} \propto(2 n)^{-1 / 2} τ′∝(2n)−1/2, τ ∝ ( 2 n 1 / 2 ) − 1 / 2 \tau \propto\left(2 n^{1 / 2}\right)^{-1 / 2} τ∝(2n1/2)−1/2。
24.5.3 相关自适应
在相关自适应中,除了 n n n个变异强度,在每个解中还有至多 ( n 2 ) \left(\begin{array}{l}n \\ 2\end{array}\right) (n2)个协方差,因此对于每个解需要更新 ( ( n 2 ) + n ) \left(\left(\begin{array}{l}n \\ 2\end{array}\right)+n\right) ((n2)+n)个外生策略参数,从而这种类型的自适应ES可以适应于决策变量( x \mathbf{x} x)存在相关的问题中。Schwefel(1981)提出,可以用与每一对坐标对应的旋转角度来代替协方差。在一个相关问题中(决策变量之间是非线性相互作用的),任务是找到所有成对的坐标旋转和在每个旋转的坐标系中的解的分布,从而使目标函数在新的坐标系中完全不相关。因此,我们对 n n n个决策变量、 n n n个变异强度 σ i \sigma_{i} σi和 ( n 2 ) \left(\begin{array}{l}n \\ 2\end{array}\right) (n2)个旋转角度( α j \alpha_{j} αj)提出了如下更新规则:
σ i ( t + 1 ) = σ i ( t ) exp ( τ ′ N ( 0 , 1 ) + τ N i ( 0 , 1 ) ) α j ( t + 1 ) = α j ( t ) + β α N j ( 0 , 1 ) x ( t + 1 ) = x ( t ) + N ( 0 , C ( σ ( t + 1 ) , α ( t + 1 ) ) ) \begin{aligned} \sigma_{i}^{(t+1)} &=\sigma_{i}^{(t)} \exp \left(\tau^{\prime} N(0,1)+\tau N_{i}(0,1)\right) \\ \alpha_{j}^{(t+1)} &=\alpha_{j}^{(t)}+\beta_{\alpha} N_{j}(0,1) \\ \mathbf{x}^{(t+1)} &=\mathbf{x}^{(t)}+\mathbf{N}\left(0, C\left(\sigma^{(t+1)}, \alpha^{(t+1)}\right)\right) \end{aligned} σi(t+1)αj(t+1)x(t+1)=σi(t)exp(τ′N(0,1)+τNi(0,1))=αj(t)+βαNj(0,1)=x(t)+N(0,C(σ(t+1),α(t+1)))
其中 N ( 0 , C ( σ ( t + 1 ) , α ( t + 1 ) ) ) \mathbf{N}\left(0, C\left(\sigma^{(t+1)}, \alpha^{(t+1)}\right)\right) N(0,C(σ(t+1),α(t+1)))为均值为0,协方差矩阵为 C C C的正太分布的相关变异向量。参数 β α \beta_{\alpha} βα固定等于0.0873(或5°)。当角度 α j \alpha_{j} αj超出范围[ − π , π -\pi,\pi −π,π],它会被重新映射到该范围内,即如果 ∣ α j ∣ > π \left|\alpha_{j}\right|>\pi ∣αj∣>π,则 α i = α j − 2 π ⋅ α j / ∣ α j ∣ \alpha_{i}=\alpha_{j}-2 \pi \cdot \alpha_{j} /\left|\alpha_{j}\right| αi=αj−2π⋅αj/∣αj∣。旋转角度随机初始化为0~180°之间的值。
24.6 开源代码
代码实现了常规的ES,包括(1+1)-ES、( μ + λ \mu+\lambda μ+λ)-ES和( μ , λ \mu,\lambda μ,λ)-ES,以及自适应的ES,下面以一个具体的优化问题为例,讲解一下代码。完整代码点击“这里”查看。
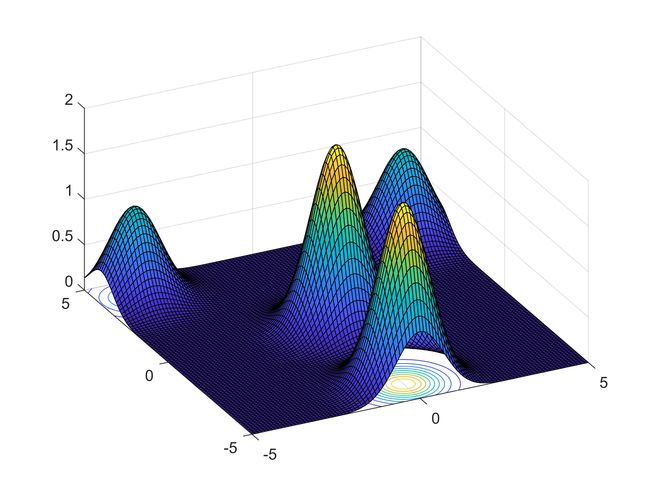
测试中使用的目标函数(最大化)方程和图像分别如下:
exp(-(x-4)^2-(y-4)^2)+exp(-(x+4)^2-(y-4)^2)+2*exp(-x^2-(y+4)^2)+2*exp(-x^2-y^2)
24.6.1 Normal-ES
- 初始参数设置。主要设置父代种群数量 popNum,子代种群数量childNum,是否合并种群concatParentandChild,最大迭代次数 maxGen,求解问题维度 dim和目标函数 objectiveFun 等。
// 新建目标函数
ObjectiveFun objectiveFun = new ObjectiveFun();
ESNormal es = ESNormal.builder().popNum(20).childNum(100).concatParentandChild(true).maxGen(500).dim(2)
.objectiveFun(objectiveFun).build();
es.start();
- 种群初始化。根据设定的父代种群大小,建立相应数量的个体,在目标函数自变量的取值范围内随机确定每个个体的编码。
@Override
public void initPop() {
// TODO Auto-generated method stub
System.out.println("**********种群初始化**********");
population = new ArrayList<>();
for (int i = 0; i < popNum; i++) {
population.add(new Individual(new Code(this.dim, objectiveFun.getRange())));
}
}
- 对父代个体进行正太分布变异,获得新的子代个体。根据是否合并种群属性concatParentandChild,确定返回种群大小。
@Override
public List makeNewIndividuals(List population) {
// TODO Auto-generated method stub
List children = new ArrayList<>();
try {
for (int i = 0; i < this.childNum; i++) {
int parentInd = random.nextInt(population.size());
Individual parent = population.get(parentInd);
Individual child = parent.clone();
double[] newCode = IntStream.range(0, this.dim)
.mapToDouble(
ind -> child.getCode().getCode()[ind] + Math.sqrt(mutStrength) * random.nextGaussian())
.toArray();
child.getCode().setCode(newCode);
children.add(child);
}
// 判断是否合并父代和子代,且如果为(1+1)-ES必须合并
if (concatParentandChild || (this.childNum == 1 && this.popNum == 1)) {
children.addAll(population);
}
} catch (CloneNotSupportedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return children;
}
- 淘汰部分较劣个体。计算种群中每个个体的适应度值,计算成功变异比率,根据是否concatParentandChild淘汰不同的个体。
@Override
public Individual killBadIndividuals(List population) throws Exception {
Individual bestIndividual = null;
// 解码
for (Individual individual : population) {
individual.setFitness(this.getObjectiveFun().getObjValue((individual.getCode().getCode())));
}
// 如果为(1+1)-ES,需要进行自适应调整变异强度
if (popNum == 1 && childNum == 1) {
// 最大化目标的化,判断是不是成功变异,要判断子代适应度是否大于父代适应度
if (this.getObjectiveFun().getDirection() == ObjectiveFun.Max) {
if (population.get(0).getFitness() > population.get(1).getFitness()) {
successMut++;
}
} else {
if (population.get(0).getFitness() < population.get(1).getFitness()) {
successMut++;
}
}
}
if ((this.iterator + 1) % G == 0) {
// 大于0.2则增加变异强度
if (successMut / G > 0.2) {
this.mutStrength = this.mutStrength / 0.817;
} else if (successMut / G < 0.2) {
this.mutStrength = this.mutStrength * 0.817;
}
successMut = 0;
}
// 首先进行排序
Collections.sort(population);
// 在(μ,λ)-ES中必须保证μ<λ
if (popNum > population.size()) {
throw new Exception("请重新设置父代种群大小(μ)和子代种群大小(λ),以保证μ<λ,一般要求5μ=λ !!!");
}
// 如果是最大化问题,则取前λ个个体(因为排序是按照适应度值从大到小排列的)
if (this.getObjectiveFun().getDirection() == ObjectiveFun.Max) {
this.population = population.subList(0, popNum);
bestIndividual = population.get(0);
} else {
this.population = population.subList(population.size() - 1 - popNum, population.size() - 1);
bestIndividual = population.get(population.size() - 1);
}
return bestIndividual;
}
- 更新迭代器。迭代次数加 1。
public void incrementIter() {
iterator++;
}
- 循环。循环执行步骤 2~5,直到迭代次数达到设定的最大迭代次数。
while (this.iterator < maxGen) {
List newPopulation = this.makeNewIndividuals(population);
Individual bestIndividual = killBadIndividuals(newPopulation);
incrementIter();
System.out.println("**********第" + iterator + "代最优解:" + bestIndividual + "**********");
}
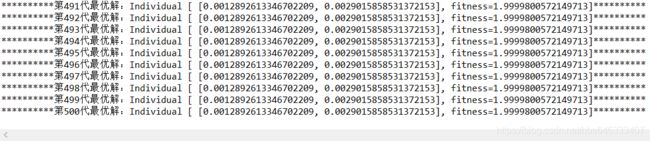
最终实验结果如下:
24.6.2 Adaptive-ES
Adaptive-ES主要是引入了交叉操作,并在每个维度上进行变异概率的自适应,其他流程和Normal-ES基本相同。
- 初始参数设置。主要设置父代种群数量 popNum,子代种群数量childNum,是否合并种群concatParentandChild,最大迭代次数 maxGen,交叉方式recombination,求解问题维度 dim和目标函数 objectiveFun 等。
// 新建目标函数
ObjectiveFun objectiveFun = new ObjectiveFun();
ESAdaptive es = ESAdaptive.builder().popNum(20).crossNum(20).childNum(100).concatParentandChild(true)
.maxGen(500).dim(2).recombination(new RecombinationIntermediate()).objectiveFun(objectiveFun).build();
es.start();
- 种群初始化。根据设定的父代种群大小,建立相应数量的个体,在目标函数自变量的取值范围内随机确定每个个体的编码。
@Override
public void initPop() {
// TODO Auto-generated method stub
System.out.println("**********种群初始化**********");
population = new ArrayList<>();
for (int i = 0; i < popNum; i++) {
population.add(new Individual(new Code(this.dim, objectiveFun.getRange())));
}
}
- 对父代个体进行交叉,然后进行变异,获得新的子代个体。根据是否合并种群属性concatParentandChild,确定返回种群大小。
@Override
public List makeNewIndividuals(List population) {
// TODO Auto-generated method stub
List children = new ArrayList<>();
try {
for (int i = 0; i < this.childNum; i++) {
List selectedParentsIndividuals = random.ints(crossNum, 0, population.size())
.mapToObj(ind -> population.get(ind)).collect(Collectors.toList());
Individual newIndividual = this.recombination.crossover(selectedParentsIndividuals);
double t0 = Math.pow(2 * this.dim, -0.5);
double t = Math.pow(2 * Math.pow(this.dim, 0.5), -0.5);
double random0 = random.nextGaussian();
double[] newMutStrength = IntStream.range(0, this.dim)
.mapToDouble(ind -> newIndividual.getCode().getMutStrength()[ind]
* Math.pow(Math.E, t0 * random0 + t * random.nextGaussian()))
.toArray();
double[] newCode = IntStream.range(0, this.dim).mapToDouble(
ind -> newIndividual.getCode().getCode()[ind] + Math.sqrt(mutStrength) * random.nextGaussian())
.toArray();
newIndividual.getCode().setCode(newCode);
newIndividual.getCode().setMutStrength(newMutStrength);
children.add(newIndividual);
}
// 判断是否合并父代和子代,且如果为(1+1)-ES必须合并
if (concatParentandChild || (this.childNum == 1 && this.popNum == 1)) {
children.addAll(population);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return children;
}
- 淘汰部分较劣个体。计算种群中每个个体的适应度值,计算成功变异比率,根据是否concatParentandChild淘汰不同的个体。
@Override
public Individual killBadIndividuals(List population) throws Exception {
Individual bestIndividual = null;
// 解码
for (Individual individual : population) {
individual.setFitness(this.getObjectiveFun().getObjValue((individual.getCode().getCode())));
}
// 首先进行排序
Collections.sort(population);
// 在(μ,λ)-ES中必须保证μ<λ
if (popNum > population.size()) {
throw new Exception("请重新设置父代种群大小(μ)和子代种群大小(λ),以保证μ<λ,一般要求5μ=λ !!!");
}
// 如果是最大化问题,则取前λ个个体(因为排序是按照适应度值从大到小排列的)
if (this.getObjectiveFun().getDirection() == ObjectiveFun.Max) {
this.population = population.subList(0, popNum);
bestIndividual = population.get(0);
} else {
this.population = population.subList(population.size() - 1 - popNum, population.size() - 1);
bestIndividual = population.get(population.size() - 1);
}
return bestIndividual;
}
- 更新迭代器。迭代次数加 1。
public void incrementIter() {
iterator++;
}
- 循环。循环执行步骤 2~5,直到迭代次数达到设定的最大迭代次数。
while (this.iterator < maxGen) {
List newPopulation = this.makeNewIndividuals(population);
Individual bestIndividual = killBadIndividuals(newPopulation);
incrementIter();
System.out.println("**********第" + iterator + "代最优解:" + bestIndividual + "**********");
}
最终实验结果如下:

完整代码:https://github.com/hanbaoan123/OptimizationAlgorithmLib.git