Python爬虫实战之三 - 基于Scrapy框架抓取Boss直聘的招聘信息
---------------readme---------------
简介:本人产品汪一枚,Python自学数月,对于小白,本文会是一篇比较容易上手的经验贴。当然毕竟是新手,欢迎大牛拍砖、狂喷~
致谢:
本着了解招聘行情,以备不时之需,之所以选择转战Boss,是因为爬完拉钩网之后,发现招聘质量有待商榷;同时也感谢Boss的权威招聘信息,也使2018年的十一假期有一段不错的学习经历收获。
爬取Boss官网(www.zhipin.com)期间,若对Boss造成或小或大的影响,本人深感歉意。本文只为获取招聘信息和交流学习,并无恶意,再次鸣谢。
---------------正文分隔符---------------
开发环境
- MacBook Air (13-inch, Early 2015)
- macOS High Sierra 10.13.6
- 1.6GHZ Inter Core i5
- Python:V 3.7.0
一、兵马未动,粮草先行
(1)、安装Scrapy
使用Mac自带终端安装,使用pip辅助安装。
ps:pip3的安装,可以参见我的另一篇博客:Python自学,番外篇之三 Mac的pip3的安装
在bash中输入命令:pip3 install scrapy
如果pip3安装没有问题,安装scrapy理论上应该很顺利,因为坑都在pip3的安装过程里填完了...
ps:一个scrapy包里面竟然有如此之多的包,也难称作scarpy框架...
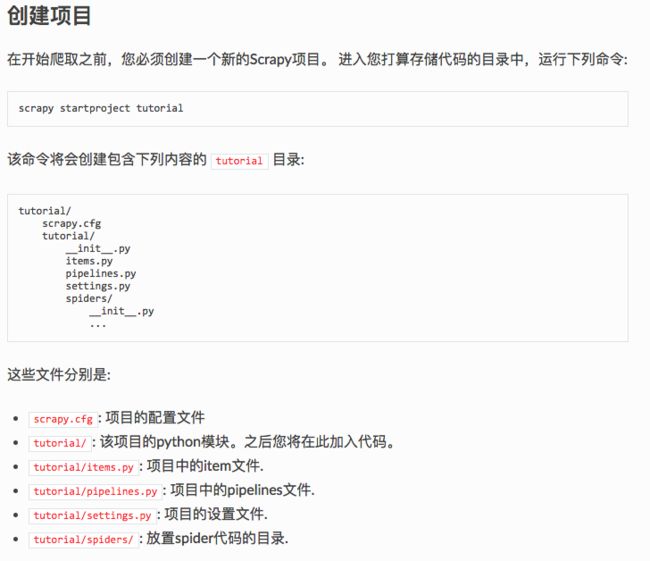
(2)、创建项目
安装完成Scrapy的安装,可以使用命令行创建新项目。
输入命令行:scrapy startproject www_zhipin_com
ps:我是参考经验贴中的教程创建的项目名称,项目的名称(www_zhipin_com)可按需求自定义。

创建项目完成后,在python3中打开该项目。
打开流程如下:python3->file->open,选择刚创建的项目。

导入项目后,可以看到在执行创建项目命令后,Scrapy会为我们自动创建spider所需的标准文件目录。
ps:开始一点点的体会到scrapy的强大,另外,也验证scrapy的安装已经没有问题了。
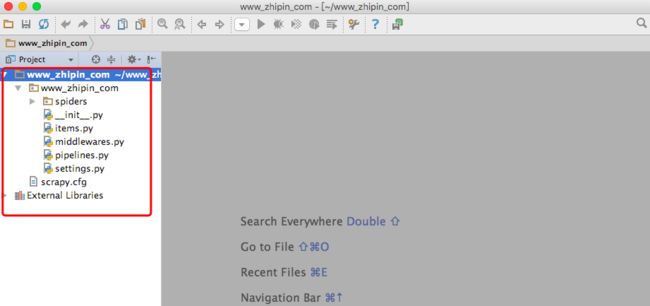
创建的项目,其中的文件作用如下:
- spiders(Python Package):相当于主程序main的package,后续会在该package中创建相应spider的python file目录
- item(Python File):spider项目的item文件,用于设置本次需从页面爬取的要素信息,如:职位名称、薪资水平、平台简称...
- middlewares:spider项目的middlewares文件,主要用于设置防反爬虫的相关策略,例如配置user_agent、代理IP等方法的设定。因本教程是小批量爬取,可以暂时不涉及。
- pipelines:spider项目的pipelines文件,用于编写已爬取的item数据的处理和存储的文件,例如,需将数据去重清洗后,保存至数据库中,则需要在该文件中定义规则和方法
- settings:spider项目的settings文件,顾名思义为配置文件,所有相关的配置信息均在此文件中定义
- scrapy.cfg:spider项目部署的相关文件,因本次不涉及更改其配置,知晓作用即可
看下入门教程给的解释,无力吐槽...
中文夹杂着英文的Scrapy官网地址:Scrapy入门教程,不过依然感激有中文解释...
(3)、创建spider代码文件
在spiders的Python Package文件中创建本次的爬取的Python File文件。
文件名:zhipin_spider (ps:这个命名可随意设置,你高兴就好,给你一个机智的眼神...)
二、备马囤粮,攻城略地
(1)、大战在即,先谋而后动
以产品经理的为例,以列表第一为参考,Boss的页面布局图如下:

ps:VIPKID给的薪水很诱人啊...咳、咳...打完这一仗,回家可以整理下简历了...
我们依次从:微观->中观->宏观,三个视角分析下Boss的html页面布局。
1)、微观视角
单条招聘信息的Html布局如下:
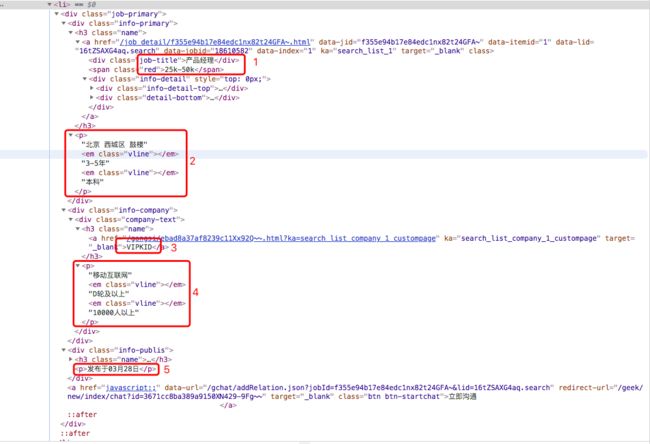
页面的主要信息如下(按出场顺序):
- 招聘职位:产品经理
- 职位薪水:25k-50k
- 公司地址:北京 西城区 鼓楼
- 工作年限:3-5年
- 教育背景:本科
- 平台简称:VIPKID
- 所在行业:移动互联网
- 融资规模:D轮及以上
- 公司规模:10000人以上
- 发布时间:发布于03月28日
如此看来,我们的item相应的要素信息基本有了,详情见Item模块。
2)、中观视角
单页招聘信息的Html布局如下:
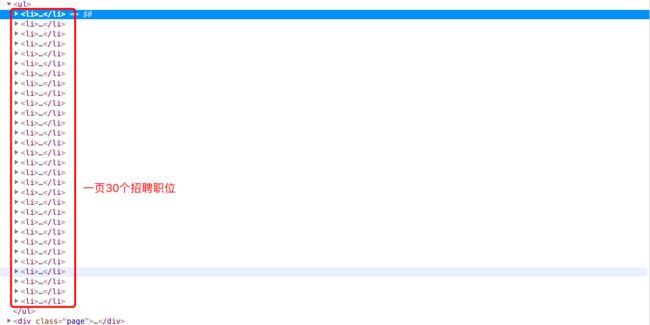
一个ul中包含30个li,对应页面的30个招聘信息,工工整整的码着,就像等待被翻牌一样...呃,脑中瞬间闪过雍正爷和乾隆爷的伟岸形象...
ps:看着这JS代码,想起了今年前半年自学JS的那段时光,一晃18年已过大半。
3)、宏观视角
单此检索查询,Boss只提供了10页的检索信息,这也就意味着,单次一个关键词检索,我们只能获取到300个职位。
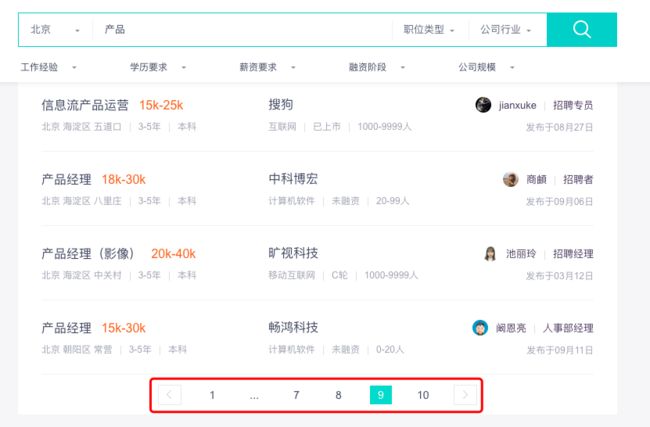
此处有个问题需要思考下:针对这样的宏观视角,我们的spider策略要如何制定?
我是这样思考的,贴出来大家可以讨论下:
首先,从效率的角度,如果关键词限定的范围越宽泛,则单次检索到所需的信息越少,例如,我需要查询的是产品经理及以上职位招聘信息,如果仅输入”产品“这个关键词,检索结果就会充斥着产品专员、产品运营等无效信息,所以从效率来讲,检索精度需越精准越好;
其次,从边界的角度,如果定位精准,就会出现边界限制的困境,很难通过我输入的精准关键词查询到关联的招聘职位,搜索范围就只限于当前的职级限制。
所以,基于此,本次作战的方针如下:单个关键词精准定位,不同领域多职级的轮循。
ps:方针确定,战略布局也就清晰了...
(2)、战略目标(Item)
既然要攻城略地,就需要确认下,哪些城哪片地可以入我等法眼。
在此,就不得不提一下产品的职业病:用户视角。
如果我是应聘者,我会需要以怎样的信息去快速筛选有意向的职位呢?答:首先是职位、薪水、哪个公司,其次是地址、要求、公司规模等。
其实,在微观的Html中已经标明Boss页面中展示的招聘信息,这些信息也是我们本次行动需要斩获的首要目标。
所以,items.py中的要素信息配置如下:
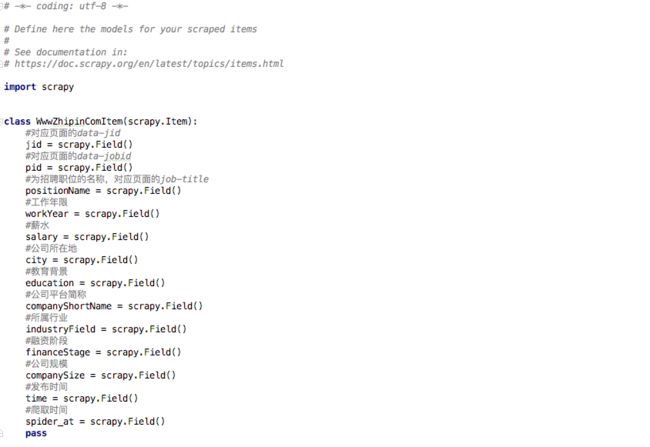


1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class WwwZhipinComItem(scrapy.Item): 12 #对应页面的data-jid 13 jid = scrapy.Field() 14 #对应页面的data-jobid 15 pid = scrapy.Field() 16 #为招聘职位的名称,对应页面的job-title 17 positionName = scrapy.Field() 18 #工作年限 19 workYear = scrapy.Field() 20 #薪水 21 salary = scrapy.Field() 22 #公司所在地 23 city = scrapy.Field() 24 #教育背景 25 education = scrapy.Field() 26 #公司平台简称 27 companyShortName = scrapy.Field() 28 #所属行业 29 industryField = scrapy.Field() 30 #融资阶段 31 financeStage = scrapy.Field() 32 #公司规模 33 companySize = scrapy.Field() 34 #发布时间 35 time = scrapy.Field() 36 #爬取时间 37 spider_at = scrapy.Field() 38 pass
官方入门教程给的Item教程如下:Scrapy官方入门教程
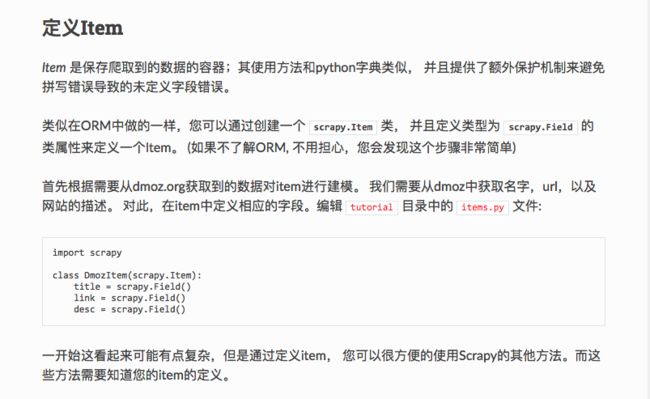
(3)、战略实施
指导方针和战略目标已经搞定,此时便可剑指城池,策马扬鞭,走起~
首先,看下Scrapy官方入门教程是怎么写的。Scrapy官方入门教程

有模板,一切就好办了,按照模版需定义相关name、start_urls和prase等信息,不多说,先粘代码,然后一步一步分解。
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import random 4 import time 5 import datetime 6 from www_zhipin_com.items import WwwZhipinComItem 7 8 9 class ZhipinSpider(scrapy.Spider): 10 11 name = 'zhipin' 12 allowed_domains = ['www.zhipin.com'] 13 start_urls = ['https://www.zhipin.com/'] 14 # 目标是:北京、上海、杭州、广州、深圳、天津,先以北京去验证代码 15 scity = ['c101010100/h_101010100'] 16 positions = ['产品经理'] 17 18 # 爬取的需求:一个scity下,所有positions的10页招聘信息 19 curPage = 1 # 当前spider的页码 20 curScityIndex = 0 # 当前spider的城市索引值 21 curPositionIndex = 0 # 当前spider的岗位索引值 22 23 headers = { 24 'Accept': 'application/json, text/javascript, */*; q=0.01', 25 'Accept-Encoding': 'gzip, deflate, br', 26 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 27 'Cookie': 'lastCity=101010100; JSESSIONID=""; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1538397559; __c=1538397566; __l=r=https%3A%2F%2Fwww.zhipin.com%2F&l=%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3D%25E4%25BA%25A7%25E5%2593%2581%25E7%25BB%258F%25E7%2590%2586%26scity%3D101010100%26industry%3D%26position%3D; t=jPFEjDvhnhIeAV4s; wt=jPFEjDvhnhIeAV4s; __a=7566280.1538397547.1538397547.1538397566.16.2.15.16; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1538457781', 28 'token': 'OPX6QDsGzqpLwns', 29 'Host': 'www.zhipin.com', 30 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 31 'x-requested-with': 'XMLHttpRequest', 32 'Referer': 'https://www.zhipin.com/' 33 } 34 35 # 因url需要scity和position进行多次拼装,且start_requests其必须返回一个可迭代Itearable对象,所以调用url_link进行url拼装,在start_requests中进行可迭代 36 def start_requests(self): 37 return [self.url_link()] 38 39 # 负责处理response并返回处理的数据以及(/或)跟进的URL 40 def parse(self, response): 41 print("request -> " + response.url) 42 job_list = response.css('div.job-list > ul > li') # 提取job-list的ul中的li 43 for job in job_list: 44 item = WwwZhipinComItem() 45 job_primary = job.css('div.job-primary') 46 item['jid'] = job.css( 47 'div.info-primary > h3 > a::attr(data-jid)').extract_first().strip() 48 item['pid'] = job.css( 49 'div.info-primary > h3 > a::attr(data-jobid)').extract_first().strip() 50 item["positionName"] = job_primary.css( 51 'div.info-primary > h3 > a > div::text').extract_first().strip() 52 53 # 直接将salary的格式Xk-Xk,改写成high、low、avg 54 salary = job_primary.css( 55 'div.info-primary > h3 > a > span::text').extract_first().strip() 56 salary_list = salary.replace('k', '000').split('-') 57 58 #将salary进行格式转换之后,我们就可以按照期望salary条件更精准的筛选 59 #假设期望的最低标注是不低于20000,同时可以有的上限不低于25000,不符合条件的招聘直接过滤掉 60 if int(salary_list[0]) < 20000 or int(salary_list[1]) < 25000: 61 continue 62 else: 63 item["salary"] = { 64 'low': int(salary_list[0]), 65 'high': int(salary_list[1]), 66 'avg': int((int(salary_list[0]) + int(salary_list[1])) / 2) 67 } 68 69 info_primary = job_primary.css( 70 'div.info-primary > p::text').extract() 71 item['city'] = info_primary[0].strip() 72 item['workYear'] = info_primary[1].strip() 73 item['education'] = info_primary[2].strip() 74 item['companyShortName'] = job_primary.css( 75 'div.info-company > div.company-text > h3 > a::text' 76 ).extract_first().strip() 77 company_infos = job_primary.css( 78 'div.info-company > div.company-text > p::text').extract() 79 if len(company_infos) == 3: 80 item['industryField'] = company_infos[0].strip() 81 item['financeStage'] = company_infos[1].strip() 82 item['companySize'] = company_infos[2].strip() 83 84 # 将发布时间的格式调整成年月日,目前有三种形式:'发布于03月31日','发布于03月31日','发布于11:31' 85 item_time = job.css('div.info-publis > p::text').extract_first().strip() 86 item_time = item_time.replace("发布于", "2018-") 87 item_time = item_time.replace("月", "-") 88 item_time = item_time.replace("日", "") 89 if item_time.find("昨天"): 90 item_time = str(datetime.date.today() - datetime.timedelta(days=1)) 91 elif item_time.find(":"): 92 item_time = str(datetime.date.today()) 93 item['time'] = item_time 94 95 item['spider_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) 96 yield item 97 98 # 实现城市->职位->页面的层级轮循 99 if self.curScityIndex < len(self.scity): 100 if self.curPositionIndex < len(self.positions): 101 if self.curPage < 10: 102 self.curPage += 1 103 elif self.curPositionIndex < len(self.positions) - 1: 104 self.curPositionIndex += 1 105 self.curPage = 1 106 elif self.curScityIndex < len(self.scity) - 1: 107 self.curScityIndex += 1 108 self.curPositionIndex = 0 109 self.curPage = 1 110 111 # 随机停留时长,俗话说以时间换空间 112 time.sleep(20 + random.randint(30, 50)) 113 yield self.url_link() #返回url_link() 114 115 # 将url拼装,并调用parse 116 def url_link(self): 117 return scrapy.http.Request( 118 self.start_urls[0] + self.scity[self.curScityIndex] + ( 119 '/?query=%s' % self.positions[self.curPositionIndex]) + ( 120 '&page=%d&ka=page-%d' % (self.curPage, self.curPage)), 121 headers=self.headers, # 此处可以引用settings中的headers 122 callback=self.parse 123 )
1)、基础参数的设定
先看下Scrapy官方入门教程中关于Spider类中的介绍。Spider官方入门教程

按照教程我们可以定义Spider中的要素信息如下:
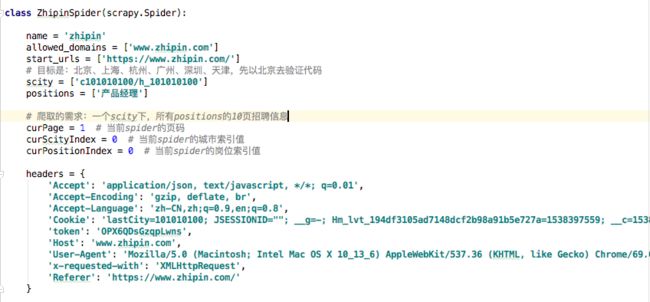
简单说明下,name、allowed_domains和start_urls的定义,这个官网教程已经给解释和参考规则,此处不再赘述。
scity是用来设定需检索的城市的列表,‘c101010100/h_101010100’为Boss链接中的地址参数,代表:北京;
positions是用来定义需检索的职位信息列表,后续可以添加多个职位信息,可针对作战方针进行有针对的spider信息;
curPage、curScityIndex和curPositionIndex三个参数,分别用来标记页面、城市和岗位的当前spider情况,后续parse函数中用到。
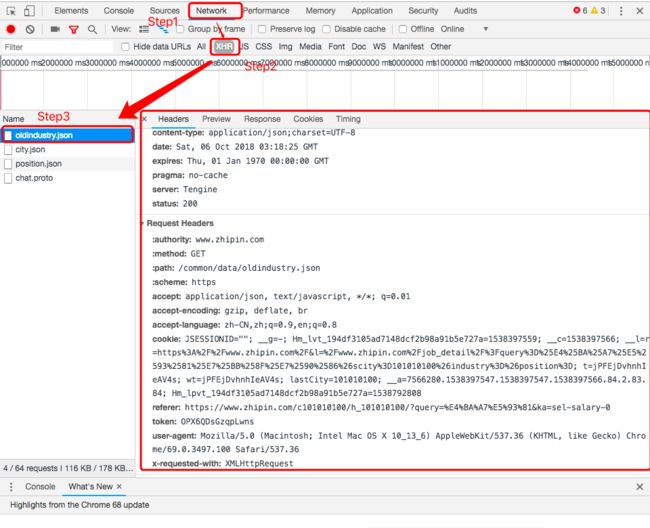
headers,模拟浏览器访问,该部分信息的获取方式如下:
2)、start_requests(self)的方法介绍
在Scrapy官方入门教程中没有用到这个方法,而是直接在start_urls中存入要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写start_requests这个方法了,首先我们看看这个方法的技能:Scrapy官网入门教程

教程中有三点需要注意:
- 该方法必须返回一个可迭代对象
- 当指定了URL时,
make_requests_from_url()将被调用来创建Request对象。 该方法仅仅会被Scrapy调用一次; - 修改最初爬取某个网站的Request对象,我们需要重写(override)该方法
由此可见,我们单独使用该方法可能没有办法满足要求,一会打一枪试一下就明白了。
3)、Boss页面的链接结构
url的结构分为两部分:招聘信息列表页和招聘详情页
①招聘信息列表页
首页:https://www.zhipin.com/?ka=header-home-logo;在顶部检索位置,有四个检索条件可以配置,分别为:
地区:当前默认北京;
内容:待输入项,此处为了更大范围能进行职位的爬取,所以此处输入:‘产品’,可以筛选出经理、高级经理、总监的全部职称的招聘信息
职位类型:全部为空
公司行业:全部为空
检索产品招聘信息后,第一页面的链接为:https://www.zhipin.com/job_detail/?query=产品经理&scity=101010100&industry=&position=
“query=”查询的内容,“scity=”城市,后两个检索条件中的后两个,为空可忽略
当点到第二页后,链接变为:https://www.zhipin.com/c101010100/h_101010100/?query=产品经理&page=2&ka=page-2
对比后,与第一页的链接相差较大,尝试使用第二页面的样式模拟第一页面的请求。
请求链接为:https://www.zhipin.com/c101010100/h_101010100/?query=产品经理&page=1&ka=page-1
可以正常打开第一页面,展示信息与之前的官网链接相同。
所以,第一页和第二页,以及后续的页面,均可以使用相同的url模版来模拟查询招聘信息。
另外,如果需要查询其他地区的招聘信息,则需要变更地区码。
如上海地区链接如下:https://www.zhipin.com/c101020100/h_101020100/?query=产品经理&page=1&ka=page-1
综上所述:
请求招聘信息列表的url公共模版如下:
https://www.zhipin.com'+'/'+'地区码'+'/?query'+'职位'+'&page='+'页码'+'&ka=page-'+'页码'
②招聘详情页
招聘的详细信息,主要存在详情页面展示,例如,职位描述、任职要求、公司简介等信息。
以该链接为例:https://www.zhipin.com/job_detail/cea321961162ff3e1Xd539W-GVE~.html?ka=search_list_3
其中:ka=search_list_3为请求的页面来源标示,所以去掉不影响页面的正常访问。
另为,cea321961162ff3e1Xd539W-GVE~,想一个ID的标示,打开Html源码确认一下。
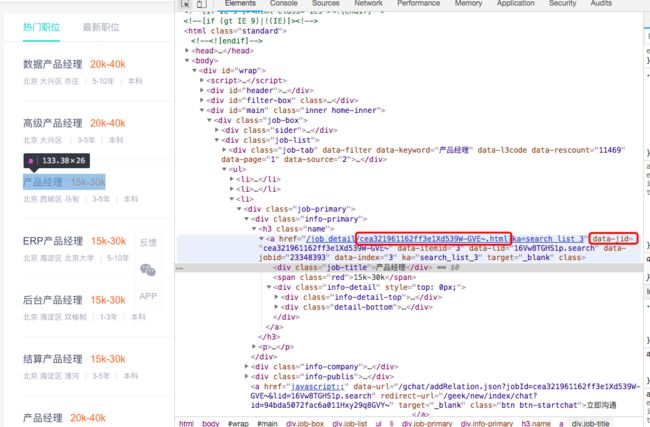
这个ID在Html中定义为data-jid,所以我们可以将详情页的url使用如下规则进行拼装。
请求招聘详情页的url公共模版如下:
'https://www.zhipin.com/job_detail/'+'jid'+'.html'
ps:jid为我们在item.py中定义的要素值,爬取该参数,等后期我们可以有针对性的了解单个有意向的招聘职位时,再进行招聘详情信息的爬取。
4)、重写start_requests(self)方法
根据招聘信息列表的url规则,我们可以对start_requests方法进行重写。
我们直接将参数url的配置方法写在start_requests()中,因其必须返回一个可迭代Itearable对应,所以参考官网教程使用列表(list)的方式'[ ]',将返回内容转换成可迭代对象。

理想总是美好的,但是现实确实残酷的,因为此处有坑,所以我们跳过后续的介绍(parse(self,response)代码见上文的zhipin_spider.py),我们先放一枪整体运行试一下...
运行结果:第一页可以在正常爬取,但是到第二页就报错。
报错报文如下:
所以借鉴参考例子的方式,利用另外一个函数专门来拼装url,将拼装后的url返回至start_requests(),同时使用列表list将返回值包装成可迭代对象,并发起第一次的Request请求。
同时在url_link(self)的callback回调parse,再parse()的callback回调url_link(),实现循环请求我们陆续拼装的url的页面,并爬取页面信息。
调整后的代码如下:

调整完,再执行时,则没有再报该问题。start_requersts(self)重写完成。
另外,此处涉及到一个Requset对象,官网给的用法如下。Scrapy官网入门教程

5)、定义parse(self,response)函数
本次参考例子中的CSS的方法摘取相关的信息,当然很有使用Xpath的方式,这两种方式均可以。
ps:有现成的当然是使用现成的效率高些,下次可以试一下Xpath的方式。Scarpy入门教程推荐Xpath教程
CSS的方式,我对比着Html页面的写了,给出了步骤分解,可供参考。 
有几处地方进行了数据的特殊处理,分别介绍下:
①salary的数据处理
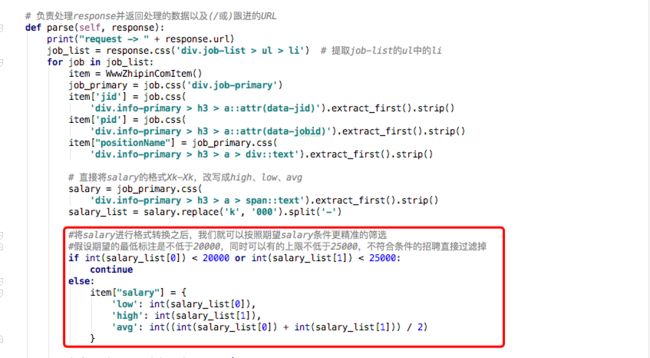
页面中的salary的是Xk-Xk的形式,但是基于个人定制化的需求,将薪水拆分出:high、low、avg三个档位,拆分出来就可以针对薪水进行规则设置。
代码中对low和high的薪水分别进行判断,如果low低于20k,或者high低于25k则直接跳出for循环,继续寻找下个招聘信息,如果符合条件,则将招聘信息按照item设定,同时输出至指定路径。
ps:想想自己的可怜的薪水,说多了都是泪啊...
②招聘信息发布时间
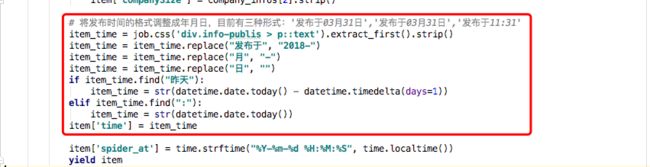
代码中也标注了,发布时间主要分为三种形式,我们将时间统一转换成:年-月-日,也是为后续的数据放方便处理。
③轮循规则

我是按照城市优先、职位次之、页面再次之的顺序轮训。
这样设定,是基于这样的考虑:是按照变换的难易程度来设定嵌套层级。
爬取招聘信息,首先会考虑城市的因素,一般情况下,是会不会轻易更换所在城市,除非一些特殊情况;另外,我们也会尝试去爬取互联网相对发达的城市,可以对比下不同城市的就业情况。另外,在相同城市,会爬取每个职位的10页检索信息,因为Boss一次检索只会返回10页的招聘信息。
总之,anyway...你可以尝试相同职位的不同城市的轮循规则,爬取的数据应该是相同的。
④睡眠?很重要
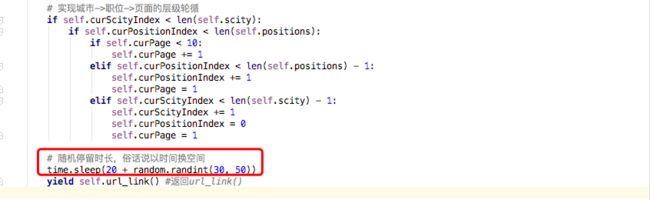
设定的爬取的睡眠时间,如果没有节制的一顿乱射,Boss只会告诉你,你过频了,然后...给你返回403,封你的IP...
设置长的睡眠时间,这也是我为什么没用代理也可以正常爬取的一个原因吧。
ps:我真正看一个页面的招聘列表信息,最多也就1分钟,所以设置1分钟的休眠时间,对Boss来说还是可以接受的...
(4)、好戏,开整
代码已经备好,随时可以发动总攻。Scrapy官方入门教程
但是在执行语句前还又一些小事情需要搞定
1)、设置 UTF-8 编码
为了让爬取到信息以utf-8的形式保存,需要添加一个设置。
在setting.py中添加(ps:在代码执行中也可以添加)
FEED_EXPORT_ENCODING = 'utf-8'
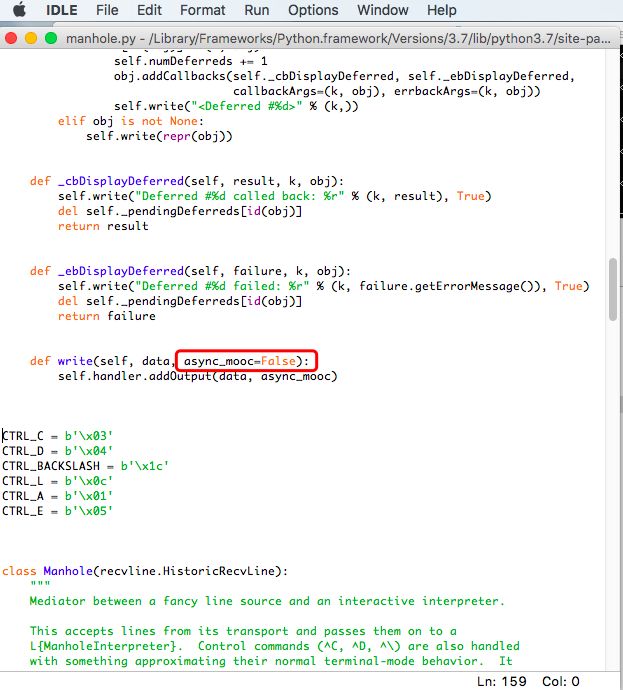
2)、修改async关键字
在首次执行scrapy crawl zhipin -o item.json时,程序报错,报文如下:

错误原因:SyntaxError: invalid syntax
该解决方法参考链接:https://blog.csdn.net/weixin_39405065/article/details/81202240
然后寻找相应的文件夹,路径如下:
Macintosh HD->资源库->Frameworks->Python.framework->Versions->3.7->lib->python3.7->site-packages->twisted->conch->manhole.py
使用安装python3时带的IDLE打开manhole.py文件,按照参考方案中修改async关键字。修改完,command+s保存即可。
万事具备,开整~
在bash中输入:cd www_zhipin_com,然后回车,使命令切到zhipin的项目下
输入:scrapy crawl boss -o item.json,然后回车
然后看着程序开始biubiu的执行,一阵舒爽....
执行的截图如下:
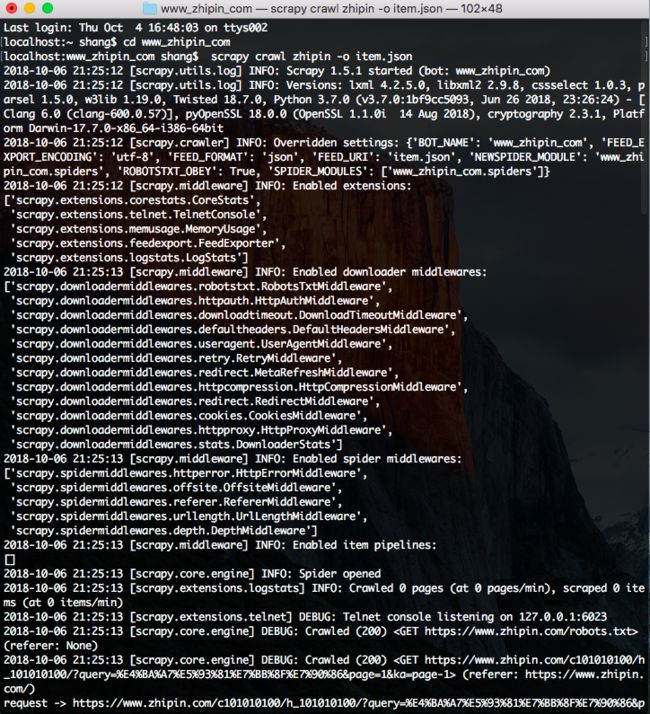
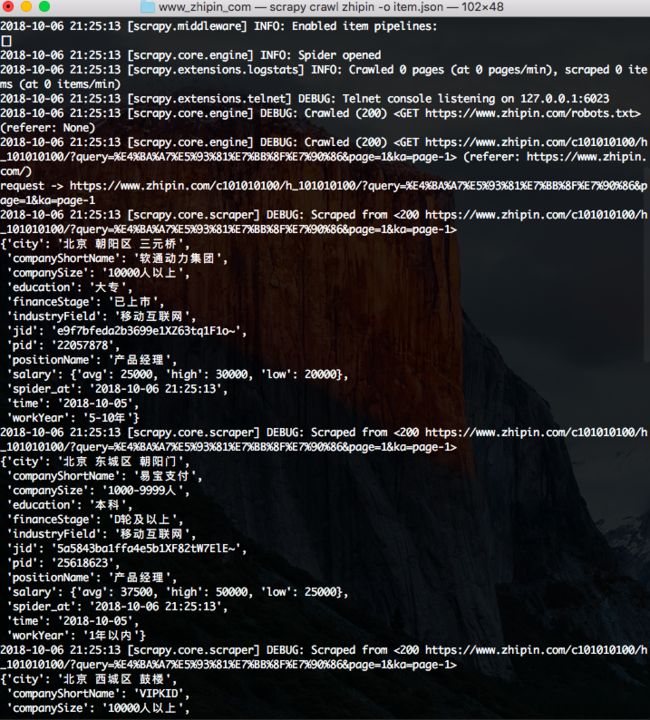
该命令会在程序执行完成后,在项目中生成一个对应的item.json文件。
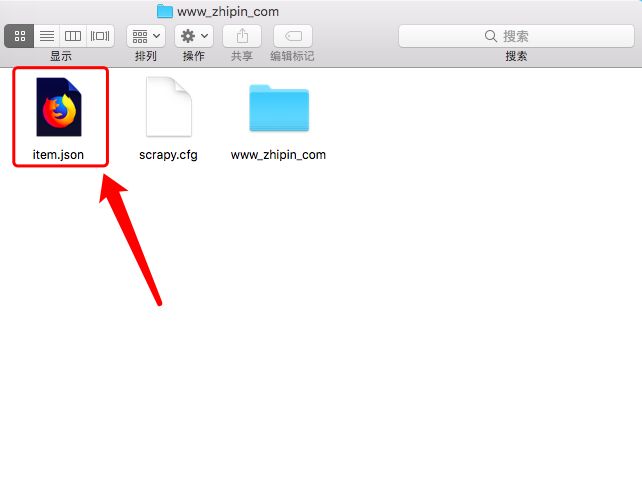
同时,该文件也可以在python3中进行查看。
三、打扫战场
上文只是按照入门教程中提到的最简单的方式保存数据,只是保存到本地的json文件中,保存的数据格式如下:
{
'city': '北京 海淀区 西北旺',
'companyShortName': '爱米欢',
'companySize': '100-499人',
'education': '本科',
'financeStage': 'A轮',
'industryField': 'O2O',
'jid': '79cea95a1818b1591XR409u-GVA~',
'pid': '20286392',
'positionName': '产品经理',
'salary': {
'avg': 30000, 'high': 40000, 'low': 20000},
'spider_at': '2018-10-06 21:28:09',
'time': '2018-10-05',
'workYear': '1-3年'}
另外,入门教程页提到将数据保存只数据库,Item Pipeline官方教程。
因按照好几个教程尝试将数据保存只MongoDB中都未能成功,所以只好作罢。
如有大神不吝赐教,还望留言联系,不胜感激~
四、不足
因这是第一次使用Scrapy框架进行spider,从10.2到10.6日写完本博客,已经用去将近整个十一假期,虽说投入了很长一段时间,但是对自己来说还有一定提升,从完全看不明白经验贴,到可以花3天时间写完整个博客分析,觉得自己还是有所长进。
但仍有一些不足,有待日后提升:
- 1、研究1天未能使用pipelines.py将数据保存至MongoDB中,略有些遗憾
- 2、关于招聘详细页的信息,还没有进行抓取
- 3、settings.py中的通用配置,以及middlewares.py中的代理IP等,未能好好研究使用一下
- 4、未能将spider到的数据,进行数据可视化的统计、精准的分析,还是导出数据后,一条一条的看(ps:还不如在Boss官网上查看招聘信息的效率高,哭丧脸...)
五、后记
查看招聘网站的种种不错的职位和待遇,真有一种跃跃欲试的冲动,找机会试试吧,希望能有能不错的机会...
同时也希望,这篇关于Scrapy的基础入门博客,能为你在python入门学习的到路上扫除一些障碍,也不枉花时间整理博客。
六、鸣谢
在本次的学习中,参考了一下的文档
1、Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
2、Scrapy入门教程
3、Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
4、Scrapy笔记02- 完整示例