Python解答蓝桥杯省赛真题之从入门到真题(二刷题目一直更新)
蓝桥刷题
文章目录
- 蓝桥刷题
-
- 不同字串
- 年号字串
- 数列求值
- 数的分解
- 特别数的和
- 迷宫
- 完全二叉树的和
- 等差数列
- 换钞票
- 分数
- 购物单
- 等差素数列
- 迷宫2
- 承压计算
- 方格分割
- 合根植物
- 判断两个圆之间的关系
原文链接:
https://github.com/libo-sober/LanQiaoCup
Python解答蓝桥杯省赛真题之从入门到真题
-
不同字串
""" 一个字符串的非空子串是指字符串中长度至少为1 的连续的一段字符组成的串。例如,字符串aaab 有非空子串a, b, aa, ab, aaa, aab, aaab,一共 7个。 注意在计算时,只算本质不同的串的个数。 请问,字符串0100110001010001 有多少个不同的非空子串? 这是一道结果填空的题,你只需要算出结果后提交即可。 本题的结果为一 个整数,在提交答案时只填写这个整数, 填写多余的内容将无法得分。 """ s = '0100110001010001' # s = 'aaab' sep = 1 # 连续的sep个字符的子串 count = 0 set1 = set() # 空集合,利用集合的不重复性 while sep <= len(s): set1.add(s[0:sep]) for i in range(len(s) - sep): set1.add(s[i+1:i+sep+1]) # 集合自动去掉重复的 sep += 1 count += len(set1) # 去重后的个数 print(set1) set1.clear() print(count) # {'b', 'a'} # {'ab', 'aa'} # {'aab', 'aaa'} # 7 # # {'1', '0'} # {'10', '11', '01', '00'} # {'110', '000', '010', '100', '001', '011', '101'} # {'0101', '0110', '0010', '0001', '1100', '1001', '0011', '1010', '1000', '0100'} # {'00101', '00010', '11000', '01001', '00110', '01010', '01100', '10011', '10001', '01000', '10100'} # {'010011', '000101', '001100', '001010', '101000', '010100', '100010', '100110', '010001', '011000', '110001'} # {'0011000', '0101000', '1000101', '0001010', '1010001', '1001100', '0010100', '1100010', '0110001', '0100110'} # {'00010100', '10011000', '10001010', '00110001', '11000101', '00101000', '01001100', '01100010', '01010001'} # {'000101000', '011000101', '110001010', '001010001', '010011000', '001100010', '100110001', '100010100'} # {'1000101000', '0100110001', '1001100010', '0110001010', '0011000101', '1100010100', '0001010001'} # {'10011000101', '10001010001', '11000101000', '01001100010', '00110001010', '01100010100'} # {'011000101000', '001100010100', '010011000101', '100110001010', '110001010001'} # {'0011000101000', '1001100010100', '0100110001010', '0110001010001'} # {'01001100010100', '10011000101000', '00110001010001'} # {'010011000101000', '100110001010001'} # {'0100110001010001'} # 100 # 直接提交100即可 -
年号字串
""" 小明用字母A 对应数字1,B 对应2,以此类推,用Z 对应26。对于27 以上的数字,小明用两位或更长位的字符串来对应,例如AA 对应27,AB 对 应28,AZ 对应52,LQ 对应329。 请问2019 对应的字符串是什么? """ # # 进制转换一般都是用除K取余法 # num = 2019 # print(num % 26, num // 26) # print(77 % 26, 77 // 26) # print(2 % 26, 2 // 26) # print(chr(ord('A') + 17 - 1)) # print(chr(ord('A') + 25 - 1)) # print(chr(ord('A') + 2 - 1)) # # BYQ # # 验算 # # LQ 329 # print(ord('Q')-ord('A')+1 + (ord('L')-ord('A')+1) * 26) # 329 # # BYQ 2019 # print(ord('Q')-ord('A')+1 + (ord('Y')-ord('A')+1) * 26 + (ord('B')-ord('A')+1) * 26 ** 2) # 2019 # # 所以提交BYQ # # # 2019 转成16进制 # # print(2019 % 16, 2019 // 16) # # print(126 % 16, 126 // 16) # # print(3 + 14 * 16 + 7 * 16 ** 2) # # 7E3 # 最后整理一下代码 year = 2019 lst = [] while year != 0: lst.append(chr(ord('A') + year % 26 - 1)) year = year // 26 # reversed(lst) lst.reverse() print(*lst) # B Y Q -
数列求值
""" 【问题描述】 给定数列 1, 1, 1, 3, 5, 9, 17, …,从第 4 项开始,每项都是前 3 项的和。 求第 20190324 项的最后 4 位数字。 【答案提交】 这是一道结果填空的题,你只需要算出结果后提交即可。 本题的结果为一个 4 位整数(提示:答案的千位不为 0), 在提交答案时只填写这个整数,填写多余的内容将无法得分。 """ # 本来想考虑用生成器来做,以达到节省内存的效果。 # 但是尝试了一下发现不太行。 # 有哪位大神可以解决吗? # 望分享。 lst = [1, 1, 1] for i in range(3, 20190324): lst.append((lst[i-3] + lst[i-2] + lst[i-1]) % 10000) print(lst[-1]) # 4659 -
数的分解
""" 把 2019 分解成 3 个各不相同的正整数之和,并且要求每个正整数都不包含数字 2 和 4,一共有多少种不同的分解方法? 注意交换 3 个整数的顺序被视为同一种方法,例如 1000+1001+18 和 1001+1000+18 被视为同一种。 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一 个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。 """ def check(x): while x != 0: a = x % 10 if a == 2 or a == 4: return True x = x // 10 return False num = 2019 lst = [] for i in range(1, num + 1): if check(i): continue for j in range(i + 1, num - i + 1): if check(j): continue for k in range(j + 1, num - i - j + 1): if check(k): continue if i + j + k == num: lst.append([i, j, k]) # print(lst) print(len(lst)) # 40785 -
特别数的和
""" 小明对数位中含有 2、0、1、9 的数字很感兴趣(不包括前导 0), 在 1 到 40 中这样的数包括 1、2、9、10 至 32、39 和 40,共 28 个, 他们的和是 574。 请问,在 1 到 n 中,所有这样的数的和是多少? 输入一行包含一个整数 n。 输出一行,包含一个整数,表示满足条件的数的和。 【样例输入】 40 【样例输出】 574 对于 20% 的评测用例,1≤n≤10。 对于 50% 的评测用例,1≤n≤100。 对于 80% 的评测用例,1≤n≤1000。 对于所有评测用例,1≤n≤10000。 """ n = int(input()) num = 0 for i in range(1, n + 1): a = i while a != 0: b = a % 10 if b in [2, 0, 1, 9]: num += i break a = a // 10 print(num) # 10000 # 41951713 # 数据规模不大,直接暴力求解 -
迷宫
""" 下图给出了一个迷宫的平面图,其中标记为 1 的为障碍,标记为 0 的为可 以通行的地方。 010000 000100 001001 110000 迷宫的入口为左上角,出口为右下角,在迷宫中,只能从一个位置走到这 个它的上、下、左、右四个方向之一。 对于上面的迷宫,从入口开始,可以按DRRURRDDDR 的顺序通过迷宫, 一共 10 步。其中 D、U、L、R 分别表示向下、向上、向左、向右走。 对于下面这个更复杂的迷宫(30 行 50 列),请找出一种通过迷宫的方式, 其使用的步数最少,在步数最少的前提下,请找出字典序最小的一个作为答案。 请注意在字典序中D -
完全二叉树的和
""" 给定一棵包含 N 个节点的完全二叉树,树上每个节点都有一个权值, 按从上到下、从左到右的顺序依次是 A1, A2, · · · AN,如下图所示: 现在小明要把相同深度的节点的权值加在一起,他想知道哪个深度的节点权值之和最大? 如果有多个深度的权值和同为最大,请你输出其中最小的深度。 注:根的深度是 1。 第一行包含一个整数 N。 第二行包含 N 个整数 A1, A2, · · · AN 。 输出一个整数代表答案 7 1 6 5 4 3 2 1 2 """ def get_deep(): n = int(input()) lst = list(map(int, input().split())) deep = 1 while 2 ** deep - 1 <= n: lst[deep - 1] = sum(lst[2 ** (deep - 1) - 1:2 ** deep - 1]) deep += 1 if 2 ** (deep - 1) - 1 < n: lst[deep - 1] = sum(lst[2 ** (deep - 1) - 1:]) return lst.index(max(lst)) + 1 if __name__ == '__main__': print(get_deep()) """ 注释: 1. map(int, input().split()) 这产生的是一个生成器, next一次会得到一个值 list可以全部结收生成器中的值并返回一个列表 gen = map(int, input().split()) print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) 1 6 5 4 3 2 1 1 6 5 4 3 2. 完全二叉树的特性 每一层的结点数:2 ** deep 满二叉树的总结点数:2 ** deep - 1 3. lst.index(a) 返回值为列表中最先出现a的索引值 加1后在此就是a对应的最小深度 """ -
等差数列
""" 试题 H: 等差数列 时间限制: 1.0s 内存限制: 256.0MB 本题总分:20 分 【问题描述】 数学老师给小明出了一道等差数列求和的题目。但是粗心的小明忘记了一 部分的数列,只记得其中 N 个整数。 现在给出这 N 个整数,小明想知道包含这 N 个整数的最短的等差数列有 几项? 【输入格式】 输入的第一行包含一个整数 N。 第二行包含 N 个整数 A 1 ,A 2 ,··· ,A N 。(注意 A 1 ∼ A N 并不一定是按等差数 列中的顺序给出) 【输出格式】 输出一个整数表示答案。 【样例输入】 5 2 6 4 10 20 【样例输出】 10 【样例说明】 包含 2、6、4、10、20 的最短的等差数列是 2、4、6、8、10、12、14、16、 18、20。 【评测用例规模与约定】 对于所有评测用例,2 ≤ N ≤ 100000,0 ≤ A i ≤ 10^ 9 。 """ def get_len(): n = int(input()) lst = list(map(int, input().split())) count = 1 lst.sort() num = lst[0] dif = lst[1] - lst[0] for i in range(2, n): new_dif = lst[i] - lst[i - 1] dif = new_dif if new_dif < dif else dif while num < lst[-1]: num += dif count += 1 return count if __name__ == '__main__': print(get_len()) """ 注释: 1. sorted 排序 l1 = [22, 33, 1, 2, 7, 4] l2 = sorted(l1) # print(l1) # [22, 33, 1, 2, 7, 4] 不会改变原来的数组内容 # print(l2) # [1, 2, 4, 7, 22, 33] l2 = [('太白',18), ('alex', 73), ('wusir', 35), ('口天吴', 41)] print(sorted(l2)) # [('alex', 73), ('wusir', 35), ('口天吴', 41), ('太白', 18)] print(sorted(l2, key=lambda x:x[1])) # 返回的是一个列表 [('太白', 18), ('wusir', 35), ('口天吴', 41), ('alex', 73)] print(sorted(l2, key=lambda x:x[1], reverse=True)) # 从大到小 2. 列表的sort()方法排序 l1.sort() print(l1) # [1, 2, 4, 7, 22, 33] 返回值为None 把原来的列表元素从小到大排序,改变原列表内容 l2 = [('太白',18), ('alex', 73), ('wusir', 35), ('口天吴', 41)] l2.sort(key=lambda x: x[1]) # print(l2) # [('太白', 18), ('wusir', 35), ('口天吴', 41), ('alex', 73)] l2.sort(key=lambda x: x[1], reverse=True) print(l2) # [('alex', 73), ('口天吴', 41), ('wusir', 35), ('太白', 18)] # 从大到小 """ -
换钞票
""" x星球的钞票的面额只有:100元,5元,2元,1元,共4种。 小明去x星旅游,他手里只有2张100元的x星币,太不方便,恰好路过x星银行就去换零钱。 小明有点强迫症,他坚持要求200元换出的零钞中2元的张数刚好是1元的张数的10倍, 剩下的当然都是5元面额的。 银行的工作人员有点为难,你能帮助算出:在满足小明要求的前提下,最少要换给他多少张钞票吗? (5元,2元,1元面额的必须都有,不能是0) 注意,需要提交的是一个整数,不要填写任何多余的内容。 """ def change_money(): money = 200 lst = [] for i in range(1, 10): if (money - i - 2 * i * 10) % 5 == 0: lst.append(i + i * 10 + (money - i - 2 * i * 10) // 5) return min(lst) if __name__ == '__main__': print(change_money()) """ 结果为74 其实本题的解就一个,就为74. """ -
分数
""" 标题:分数 1/1 + 1/2 + 1/4 + 1/8 + 1/16 + … 每项是前一项的一半,如果一共有20项, 求这个和是多少,结果用分数表示出来。 类似: 3/2 当然,这只是加了前2项而已。分子分母要求互质。 注意: 需要提交的是已经约分过的分数,中间任何位置不能含有空格。 请不要填写任何多余的文字或符号 """ def gcd(a, b): while a % b != 0: c = a % b a = b b = c return c def get_num(n): fenzi = 0 fenmu = 2 ** (n - 1) for i in range(n): fenzi += 2 ** i mcf = gcd(fenmu, fenzi) return f'{fenzi // mcf}/{fenmu // mcf}' if __name__ == '__main__': print(get_num(20)) # 1048575/524288 # print(gcd(20, 35)) # 5 -
购物单
""" 标题: 购物单 小明刚刚找到工作,老板人很好,只是老板夫人很爱购物。 老板忙的时候经常让小明帮忙到商场代为购物。小明很厌烦,但又不好推辞。 这不,XX大促销又来了!老板夫人开出了长长的购物单,都是有打折优惠的。 小明也有个怪癖,不到万不得已,从不刷卡,直接现金搞定。 现在小明很心烦,请你帮他计算一下,需要从取款机上取多少现金,才能搞定这次购物。 取款机只能提供100元面额的纸币。小明想尽可能少取些现金,够用就行了。 你的任务是计算出,小明最少需要取多少现金。 以下是让人头疼的购物单,为了保护隐私,``物品名称被隐藏了。 **** 180.90 88折 **** 10.25 65折 **** 56.14 9折 **** 104.65 9折 **** 100.30 88折 **** 297.15 半价 **** 26.75 65折 **** 130.62 半价 **** 240.28 58折 **** 270.62 8折 **** 115.87 88折 **** 247.34 95折 **** 73.21 9折 **** 101.00 半价 **** 79.54 半价 **** 278.44 7折 **** 199.26 半价 **** 12.97 9折 **** 166.30 78折 **** 125.50 58折 **** 84.98 9折 **** 113.35 68折 **** 166.57 半价 **** 42.56 9折 **** 81.90 95折 **** 131.78 8折 **** 255.89 78折 **** 109.17 9折 **** 146.69 68折 **** 139.33 65折 **** 141.16 78折 **** 154.74 8折 **** 59.42 8折 **** 85.44 68折 **** 293.70 88折 **** 261.79 65折 **** 11.30 88折 **** 268.27 58折 **** 128.29 88折 **** 251.03 8折 **** 208.39 75折 **** 128.88 75折 **** 62.06 9折 **** 225.87 75折 **** 12.89 75折 **** 34.28 75折 **** 62.16 58折 **** 129.12 半价 **** 218.37 半价 **** 289.69 8折 需要说明的是,88折指的是按标价的88%计算,而8折是按80%计算,余者类推。 特别地,半价是按50%计算。 请提交小明要从取款机上提取的金额,单位是元。 答案是一个整数,类似4300的样子,结尾必然是00,不要填写任何多余的内容。 特别提醒:不许携带计算器入场,也不能打开手机。 """ import math from fnmatch import fnmatchcase as match """ 这个求解方式很装逼, 但是, 蓝桥杯不允许导入第三方库, 又但是, 蓝桥杯是可以用python的标准库的, math是python标准库可以用,fnmatch我上网查貌似也是python的标准库。 我不确定,有兴趣的小伙伴们可以取查一下。 所以大家知道导库解决更容易就行了。 实锤: fnmatch.fnmatchcase(filename, pattern) Test whether filename matches pattern, returning True or False; the comparison is case-sensitive and does not apply os.path.normcase(). 官方文档可查,fnmatch也是python标准库,蓝桥可以使用。 本题完全可以使用这种方法。 此外, 本方法也可以不加库, 把match(new_line[-1], '?折')改为new_line[-1]去掉'折'后判断剩余new_line[-1]字符串的长度, 为1则 time = int(new_line[-1][:-1]) * 0.1 为2则 time = int(new_line[-1][:-1]) * 0.01 普通应试解法参考链接: https://blog.csdn.net/qq_31910669/article/details/103641497 在目录中选购物单即为本题目应试解法。 此方法需要用记事本先对数据进行格式化处理。 """ def get_prices(file_name): prices = 0 with open(file_name, mode='rt', encoding='utf-8') as f: info = f.readlines() for line in info: new_line = line.split() time = 0 if new_line[-1] == '半价': time = 0.5 elif match(new_line[-1], '?折'): time = int(new_line[-1][:-1]) * 0.1 elif match(new_line[-1], '*折'): time = int(new_line[-1][:-1]) * 0.01 prices += float(new_line[1]) * time return math.ceil(prices / 100) * 100 if __name__ == '__main__': print(get_prices('数据/com_info')) # 5200 """ 注释: 1. fnmatch模块 fnmatch模块下的fnmatchcase方法 fnmatchcase(匹配目标字符串, 需要匹配的通配符字符串) * 匹配多个 ? 匹配一个 可以匹配返回True 否则返回False 2. math模块(math库蓝桥考试可以用,属于python的标准库) math模块下的ceil(x)方法:向上取整,x为500.45则返回501 math模块下的floor(x)方法:向下取整,x为500.45则返回500 """ -
等差素数列
""" 难度系数:*** 2,3,5,7,11,13,…是素数序列。 类似:7,37,67,97,127,157 这样完全由素数组成的等差数列,叫等差素数数列。 上边的数列公差为30,长度为6。 2004年,格林与华人陶哲轩合作证明了:存在任意长度的素数等差数列。 这是数论领域一项惊人的成果! 有这一理论为基础,请你借助手中的计算机,满怀信心地搜索: 长度为10的等差素数列,其公差最小值是多少? 注意:需要提交的是一个整数,不要填写任何多余的内容和说明文字。 """ def init_num(): global tot for i in range(2, N): if dp[i] == 1: continue prim[tot] = i # 记录N以内的所有素数 tot += 1 j = i while i * j < N: dp[i * j] = 1 # 不是素数的位置标记1 j += 1 def get_dif(): global dif init_num() # print(dp[:100]) # print(prim[:100]) # print(tot) while dif * 10 < N: for j in range(tot): flag, temp = True, prim[j] for k in range(1, 10): # temp后边是否再有9个满足等差条件的素数 if temp + dif >= N or dp[temp + dif] == 1: flag = False break else: temp += dif if flag: # print(dif, prim[j]) return dif dif += 1 N = 1000010 dp = [1, 1] + [0] * N tot = 0 dif = 1 prim = [0] * N if __name__ == '__main__': # print(is_prime(2)) print(get_dif()) -
迷宫2
""" X星球的一处迷宫游乐场建在某个小山坡上。 它是由10x10相互连通的小房间组成的。 房间的地板上写着一个很大的字母。 我们假设玩家是面朝上坡的方向站立,则: L表示走到左边的房间, R表示走到右边的房间, U表示走到上坡方向的房间, D表示走到下坡方向的房间。 X星球的居民有点懒,不愿意费力思考。 他们更喜欢玩运气类的游戏。这个游戏也是如此! 开始的时候,直升机把100名玩家放入一个个小房间内。 玩家一定要按照地上的字母移动。 迷宫地图如下: UDDLUULRUL UURLLLRRRU RRUURLDLRD RUDDDDUUUU URUDLLRRUU DURLRLDLRL ULLURLLRDU RDLULLRDDD UUDDUDUDLL ULRDLUURRR 请你计算一下,最后,有多少玩家会走出迷宫? 而不是在里边兜圈子。 请提交该整数,表示走出迷宫的玩家数目,不要填写任何多余的内容。 """ def dfs(x, y): """ 深度搜索 :param x: 位置横坐标 :param y: 位置纵坐标 :return: None """ global ans while True: """所在(x, y)位置的人按照标识走出迷宫后推出循环""" # print(x, y) if x > 9 or x < 0 or y > 9 or y < 0: ans += 1 # print(ans) break if data_map[x][y] == 1: break # 记录走过的位置 data_map[x][y] = 1 if data[x][y] == 'U': x -= 1 elif data[x][y] == 'D': x += 1 elif data[x][y] == 'L': # print(x, y) y -= 1 elif data[x][y] == 'R': y += 1 def get_num(): """ 获取走出迷宫的人数 :return: 走出迷宫的人数 """ global data_map global ans for i in range(0, 10): for j in range(0, 10): """对每个位置进行遍历,注意每次遍历开始前要先对data_map清0""" # data_map = [[0] * 10] * 10 # 不要用这种方式定义,这样data_map[1][1] = 1 会导致每一行的第一个位置都为1 data_map = [[0] * 10 for _ in range(10)] # 这样行 # print(i, j) dfs(i, j) return ans def get_data(file_name): """ 获取数据 :param file_name: 保存数据的文件 :return: 获取的数据 """ data = [] with open(file_name, mode='rt', encoding='utf-8') as f: for line in f: line = list(line.strip()) data.append(line) return data # data_map = [[0] * 10] * 10 # 不要用这种方式定义,这样data_map[1][1] = 1 会导致每一行的第一个位置都为1 data_map = [[0] * 10 for _ in range(10)] # 这样行 # data_map = [[0 for _ in range(10)] for i in range(10)] # 这样也行 # data_map = [] # for i in range(10): # data_map.append([0 for i in range(10)]) data = get_data('数据/maze2') ans = 0 if __name__ == '__main__': print(get_num()) # 31个人 # dfs(8, 2) -
承压计算
""" X星球的高科技实验室中整齐地堆放着某批珍贵金属原料。 每块金属原料的外形、尺寸完全一致,但重量不同。 金属材料被严格地堆放成金字塔形。 7 5 8 7 8 8 9 2 7 2 8 1 4 9 1 8 1 8 8 4 1 7 9 6 1 4 5 4 5 6 5 5 6 9 5 6 5 5 4 7 9 3 5 5 1 7 5 7 9 7 4 7 3 3 1 4 6 4 5 5 8 8 3 2 4 3 1 1 3 3 1 6 6 5 5 4 4 2 9 9 9 2 1 9 1 9 2 9 5 7 9 4 3 3 7 7 9 3 6 1 3 8 8 3 7 3 6 8 1 5 3 9 5 8 3 8 1 8 3 3 8 3 2 3 3 5 5 8 5 4 2 8 6 7 6 9 8 1 8 1 8 4 6 2 2 1 7 9 4 2 3 3 4 2 8 4 2 2 9 9 2 8 3 4 9 6 3 9 4 6 9 7 9 7 4 9 7 6 6 2 8 9 4 1 8 1 7 2 1 6 9 2 8 6 4 2 7 9 5 4 1 2 5 1 7 3 9 8 3 3 5 2 1 6 7 9 3 2 8 9 5 5 6 6 6 2 1 8 7 9 9 6 7 1 8 8 7 5 3 6 5 4 7 3 4 6 7 8 1 3 2 7 4 2 2 6 3 5 3 4 9 2 4 5 7 6 6 3 2 7 2 4 8 5 5 4 7 4 4 5 8 3 3 8 1 8 6 3 2 1 6 2 6 4 6 3 8 2 9 6 1 2 4 1 3 3 5 3 4 9 6 3 8 6 5 9 1 5 3 2 6 8 8 5 3 2 2 7 9 3 3 2 8 6 9 8 4 4 9 5 8 2 6 3 4 8 4 9 3 8 8 7 7 7 9 7 5 2 7 9 2 5 1 9 2 6 5 3 9 3 5 7 3 5 4 2 8 9 7 7 6 6 8 7 5 5 8 2 4 7 7 4 7 2 6 9 2 1 8 2 9 8 5 7 3 6 5 9 4 5 5 7 5 5 6 3 5 3 9 5 8 9 5 4 1 2 6 1 4 3 5 3 2 4 1 X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X 其中的数字代表金属块的重量(计量单位较大)。 最下一层的X代表30台极高精度的电子秤。 假设每块原料的重量都十分精确地平均落在下方的两个金属块上, 最后,所有的金属块的重量都严格精确地平分落在最底层的电子秤上。 电子秤的计量单位很小,所以显示的数字很大。 工作人员发现,其中读数最小的电子秤的示数为:2086458231 请你推算出:读数最大的电子秤的示数为多少? 注意:需要提交的是一个整数,不要填写任何多余的内容。 """ from fnmatch import fnmatchcase as match def get_num(): data = [] length = 0 with open('数据/m', encoding='utf-8') as f: for line in f: if match(line, '*X*'): length = len(line.split()) break data.append(list(map(int, line.split()))) data.append([0] * length) # print(data, length) for i in range(1, len(data)): data[i - 1].insert(0, 0) data[i - 1].append(0) # print(data[i - 1]) for j in range(len(data[i])): data[i][j] += (data[i - 1][j] / 2 + data[i - 1][j + 1] / 2) return 2086458231 / min(data[-1]) * max(data[-1]) if __name__ == '__main__': print(get_num()) # 72665192664.0 提交整数 72665192664 -
方格分割
""" 6x6的方格,沿着格子的边线剪开成两部分。 要求这两部分的形状完全相同。 如图:p1.png, p2.png, p3.png 就是可行的分割法。 试计算: 包括这3种分法在内,一共有多少种不同的分割方法。 注意:旋转对称的属于同一种分割法。 请提交该整数,不要填写任何多余的内容或说明文字。 """ def dfs(x, y): global ans if x == 0 or x == n or y == 0 or y == n: ans += 1 return for i in range(4): tx = x + directions[i][0] ty = y + directions[i][1] if arr_map[tx][ty] == 0: arr_map[tx][ty] = 1 arr_map[n - tx][n - ty] = 1 dfs(tx, ty) arr_map[tx][ty] = 0 arr_map[n - tx][n - ty] = 0 return ans / 4 n = 6 ans = 0 arr_map = [[0] * (n + 1) for i in range(10)] directions = [(-1, 0), (1, 0), (0, -1), (0, 1)] arr_map[3][3] = 1 # print(arr_map) if __name__ == '__main__': print(dfs(n // 2, n // 2)) # 509 # print(ans) """ 注释: 从中心带你(3,3)开始出发,两边对称走,最后总数要除以4 """ -
合根植物
问题描述
w星球的一个种植园,被分成 m * n 个小格子(东西方向m行,南北方向n列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。
如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?输入格式
第一行,两个整数m,n,用空格分开,表示格子的行数、列数(1格子的编号一行一行,从上到下,从左到右编号。
比如:5 * 4 的小格子,编号:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20样例输入
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17样例说明:其合根情况参考下图(注意:6也是一个连通子集)
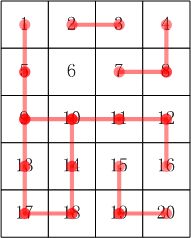
样例输出
5def init(n): for i in range(1, n+1): pre[i] = i def find_pre(key): """找key的根,也就是找带头大哥""" if pre[key] == key: return key else: pre[key] = find_pre(pre[key]) # 如果当前节点不是根节点,就找当前节点的父节点的根节点。最后的到的根就是key的根 return pre[key] def unite(x, y): """如果x和y不相连则连接它们,即x的根和y的根不同,则让一方从属于另一方""" rootx = find_pre(x) rooty = find_pre(y) if rootx != rooty: pre[rootx] = rooty m, n = list(map(int, input().split())) line = int(input()) ans = 0 lst = [0 for i in range(m*n+1)] pre = [0 for i in range(m*n+1)] # 存放以索引值为节点序号的点的根节点 init(m*n) # 初始化每个节点的根节点都为它自己,即开始时都各不相连 for i in range(line): x, y = list(map(int, input().split())) unite(x, y) # 每输入两个有关联的节点,就让他们相连 for i in range(1, m*n+1): lst[find_pre(i)] = 1 # 遍历每个节点,把她们对应的根节点的索引位置赋值1,比如节点1的老大是13,5的老大也是13,则他们属于1个节点集,操作和都只能将lst的13索引的地方赋值1 for i in range(1, m*n+1): # 等于1的个数就是最后的子集个数 if lst[i] == 1: ans += 1 print(ans) # pre:[0, 13, 3, 3, 8, 13, 6, 8, 8, 13, 13, 13, 13, 13, 13, 20, 13, 13, 13, 20, 20] -
判断两个圆之间的关系
Problem B: 判断两个圆之间的关系
Description
定义Point类,包括double类型的两个属性,分别表示二维空间中一个点的横纵坐标;定义其必要的构造函数和拷贝构造函数。定义Circle类,包括Point类的对象和一个double类型的数据作为其属性,分别表示圆心坐标及半径;定义其必要的构造函数、拷贝构造函数。定义Circle类的成员函数:
int JudgeRelation(const Circle& another)
用于判断当前圆与another之间的位置关系。该函数的返回值根据以下规则确定:当两个圆外离时返回1;当两个圆内含时返回2;当两个圆外切时返回3; 当两个圆内且时返回4;当两个圆相交时返回5。
Input
第1行N>0表示测试用例个数。每个测试用例包括2行,第1行是第1个圆的位置及半径;第2行是第2个圆的位置和半径。
Output
每个测试用例对应一行输出,输出两个圆之间的位置关系。见样例。Sample Input
5
0 0 10
20 20 1
0 0 10
1 1 4
0 0 10
0 20 10
0 0 10
0 5 5
0 0 10
15 0 10
Sample Output
Outside
Inside
Externally tangent
Internally tangent
Intersection
HINT
外离与内含均指两个圆没有任何交点,但内含是指一个圆完全包含在另一个的内部,否则便是外离。import math class Point: def __init__(self, x, y): self.x = x self.y = y class Circle: def __init__(self, center, r): self.center = center self.r = r def judge_relation(self,another): dis = math.sqrt((self.center.x - another.center.x) ** 2 + (self.center.y - another.center.y) ** 2) if self.r + another.r < dis: # print("外离") return 'Outside' elif self.r + another.r == dis: # print('外切') return 'Externally tangent' elif math.fabs(self.r - another.r) < dis < self.r + another.r: # print('相交') return 'Intersection' elif math.fabs(self.r - another.r) == dis: # print('内切') return 'Internally tangent' else: # dis < math.fabs(self.r - another.r) # print('内含') return 'Inside' def main(): n = int(input()) for i in range(n): x1, y1, r1 = list(map(int, input().split())) x2, y2, r2 = list(map(int, input().split())) one = Circle(Point(x1, y1), r1) another = Circle(Point(x2, y2), r2) res = one.judge_relation(another) print(res) if __name__ == '__main__': main()