目标检测Anchor是什么?怎么科学设置?人人都能彻底搞懂的Anchor深度解析
作者丨元峰
来源丨AIZOO
编辑丨极市平台
极市导读
在基于anchor的目标检测网络中,一个至关重要的步骤就是科学的设置anchor,可以说Anchor设置的合理与否,极大的影响着最终模型检测性能的好坏。本文作者以通俗易懂的语言介绍Anchor是什么,以及如何科学的设置anchor。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
对于目标检测新手来说,一个比较常见的误区就是拿到模型,直接无修改的在自己的数据集上训练,最终可能导致模型虽然有一定效果,但是mAP指标可能低于别人的十几个点,这里很有可能就是anchor设置的不合理。笔者记得在之前面试应届生的时候,也有不少学生不能清晰的表达anchor是什么,以及怎么科学的设置。笔者开源人脸口罩检测模型和数据后,也有不少同行和学生在自己的网络上训练,通过与他们的交流,我发现很多人都遇到了不知道anchor怎么设置,或者设置不科学的问题。
今天,我们讲解一下anchor,因为这篇文章面向新手,所以笔者争取用质朴(讲人话)的语言进行简单的介绍,同时,我们也将相关代码上传到了Github,大家可以在自己的数据集上可视化数据分布(链接见文末)。

在介绍Anchor之前,我们先介绍一下传统的人脸识别算法,是怎么检测出图片中的人脸的。以下图为例,如果我们要检测图中小女孩的人脸位置,一个比较简单暴力的方法就是滑窗,我们使用不同大小、不同长宽比的候选框在整幅图像上进行穷尽式的滑窗,然后提取窗口内的特征(例如Haar、LBP、Hog等特征),再送入分类器(SVM、Adaboost等)判断该窗口内包含的是否为人脸。这种方法简单易理解,但是这类方法受限于手动设计的特征,召回率和准确率通常不是很高。

在深度学习时代,大名鼎鼎的RCNN和Fast RCNN依旧依赖滑窗来产生候选框,也就是Selective Search算法,该算法优化了候选框的生成策略,但仍旧会产生大量的候选框,导致即使Fast RCNN算法,在GPU上的速度也只有三、四帧每秒。直到Faster RCNN的出现,提出了RPN网络,使用RPN直接预测出候选框的位置。RPN网络一个最重要的概念就是anchor,启发了后面的SSD和YOLOv2等算法,虽然SSD算法称之为default box,也有算法叫做prior box,其实都是同一个概念,他们都是anchor的别称。
1. 什么是Anchor
那么,anchor到底是什么呢?如果我们用一句话概括——就是在图像上预设好的不同大小,不同长宽比的参照框。(其实非常类似于上面的滑窗法所设置的窗口大小)
下图来自《动手学深度学习》中的例子,假设一个256x256大小的图片,经过64、128和256倍下采样,会产生4x4、2x2、1x1大小的特征图,我们在这三个特征图上每个点上都设置三个不同大小的anchor。当然,这只是一个例子,实际的SSD模型,在300x300的输入下,anchor数量也特别多,其在38x38、19x19、10x10、5x5、3x3、1x1的六个特征图上,每个点分别设置4、6、6、6、6、4个不同大小和长宽比的anchor,所以一共有38x38x4+ 19x19x6+ 10x10x6+ 5x5x6+ 3x3x4+ 1x1x4= 8732个anchor。
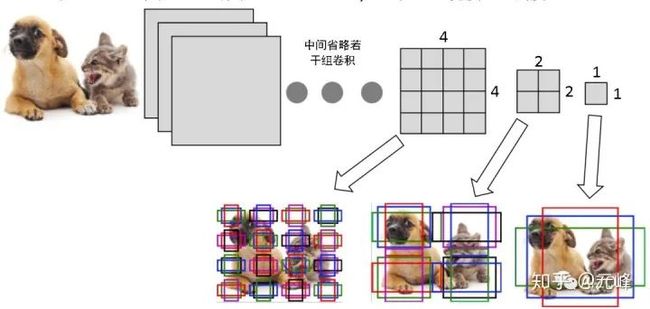
借助神经网络强大的拟合能力,我们不再需要计算Haar、Hog等特征,直接让神经网络输出,每个anchor是否包含(或者说与物体有较大重叠,也就是IoU较大)物体,以及被检测物体相对本anchor的中心点偏移以及长宽比例。 以下图为例:

一般的目标检测网络可能有成千上万个anchor,例如标准SSD在300x300输入下有8732个anchor,在500x500下anchor数量过万。我们拿上图中的三个anchor举例,神经网络的输出,也就是每个anchor认为自己是否含有物体的概率,物体中心点与anchor自身的中心点位置的偏移量,以及相对于anchor宽高的比例。因为anchor的位置都是固定的,所以就可以很容易的换算出来实际物体的位置。以图中的小猫为例,红色的anchor就以99%的概率认为它是一只猫,并同时给出了猫的实际位置相对于该anchor的偏移量,这样,我们将输出解码后就得到了实际猫的位置,如果它能通过NMS(非最大抑制)筛选,它就能顺利的输出来。但是,绿色的anchor就认为它是猫的概率就很小,紫色的anchor虽然与猫有重叠,但是概率只有26%。
其实SSD的推理很简单,就是根据anchor进行位置解码,然后进行NMS过程,就完成了(更详细的推理介绍,请查看我们这篇文章如何在浏览器运行深度神经网络?以人脸口罩识别为例进行讲解)。在训练的时候,也就是给每张图片的物体的Bounding Box,相对于anchor进行编码,如果物体的Bounding Box与某个anchor的IoU较大,例如大于0.5就认为是正样本,否则是负样本(当然,也有算法将大于0.7的设为正样本,小于0.3的算负样本,中间的不计算损失)。
以SSD作者给出的示例图为例,图中有一只猫和一只狗,这只猫在8x8的特征图上所设置anchor中,有两个(蓝色部分)与猫的IoU较大,可以认为是正样本,而对于狗,在4x4的特征图上的设置的anchor,有一个(红色部分)与狗的IoU较大,可以认为是正样本。其他的,都算作负样本。在实际中,因为anchor非常密集,所以SSD算法中,会有多个anchor与物体的IoU大于阈值,所以可能多个anchor都是对应同一个物体的正样本(例如这只猫,就可能有不止2个匹配的正样本)。
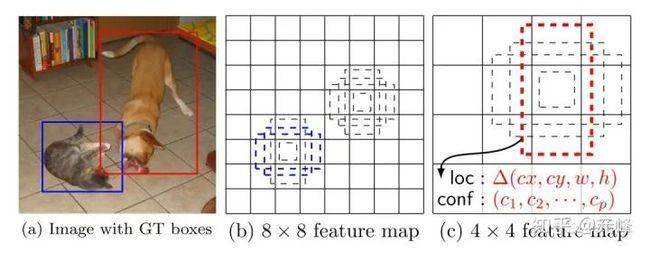
看到这里大家应该比较明白了,在训练的时候,需要anchor的大小和长宽比与待检测的物体尺度基本一致,才可能让anchor与物体的IoU大于阈值,成为正样本,否则,可能anchor为正样本的数目特别少,就会导致漏检很多。

我们举个例子,如果您要检测道路两边的电线杆,电线杆的宽高比可能不止1:10,而且特别细。如果您设置的anchor长宽比为1:1、1:2、 2:1、 1:3、 3:1这五个不同的长宽比,那可能到导致在训练的时候,没有哪个anchor与电线杆的IoU大于0.5,导致全部为负样本,那么,这样的anchor设置,模型怎么可能检测出来电线杆呢?(虽然我们在实现SSD算法的时候,即使某个物体与所有anchor的IoU都不大于0.5的阈值,也会可怜可怜它,给它强行分配一个IoU最大的anchor,即使IoU只有0.3, 但是这样,每个物体只能分配一个,而且宽高偏移量还比较大,导致回归不准)。
到这里,大家应该知道了,对于目标检测,anchor合理设置大小和宽高比,可以说非常重要。那么,如何科学的设置anchor呢?
2. 如何科学的设置Anchor
在FasterRCNN的RPN网络部分,anchor为三个尺度{128, 256, 512},三个比例{1:1, 1:2, 2:1},所以一共9组anchor。
在SSD论文中,作者使用6组定位层,每个定位层分别有6个anchor(不过第一和最后一个定位层只有4个)。一个尺度,分别有1:1、1:2、2:1、1:3、3:1五个不同宽高比,再加一个后面特征图的anchor尺度与该特征图的尺度相乘再开根号,也就是:
![]()
同样是1:1比例,所以一共5+1=6组anchor。
关于anchor的宽度,是尺度(scale,简写为s)乘以长宽比(aspect ratio,简写为ar)的根方,而高度,则是除以ar的根方。
![]()
![]()
在SSD中,作者提到了anchor尺度大小(scale)的计算方法,也就是从最小的0.2,到最大的0.9,中间四个定位层的大小是等间隔采样得到的。
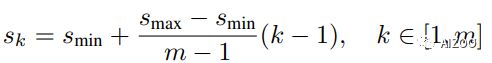
但是,但是,大家查看SSD开源的代码,作者给出的得anchor大小并不是这么计算得到的。而是30、60、111、162、213、264(再加一个315)这7个尺度。我想,这应该是作者根据数据集的物体框大小的分布而设置的。因为上面我们介绍了,anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
YOLOv3在三个不同尺度,每个尺度三个不同大小的anchor,一共九组。这位退出CV圈的Joseph Redmon大神则是在YOLOv2版本开始使用kmeans方法聚类得到合适的anchor。
可见,三大框架的作者,在实际的公开数据集上,都是根据数据的实际分布来设置的,所以,我们在自己的数据集上训练目标检测网络时,一定!不要!拿到开源代码就是一顿跑,拿起键盘就是干。
3 .代码示例
我们将代码开源放到了Github上。以人脸检测数据集Wider Face为例,因为人脸从下巴到额头,宽高比大约为1:1.4左右。在我们的开源代码中,将example.py开头设置文件路径和要聚类的簇,以及是否将物体坐标相对于图像宽高尺度归一化。
ANNOTATIONS_PATH = "./data/widerface-annotations"
CLUSTERS = 25
BBOX_NORMALIZE = False然后代码会自动读取所有的xml文件中的物体坐标,然后运行kmeans聚类,并将结
果画出来。我们可以看到数据分布如下:
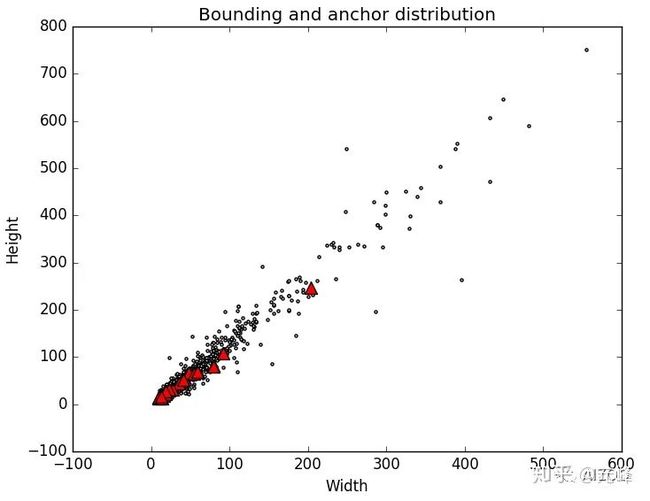
其中黑色点是随机选的2000个物体框的大小,红色三角为聚类结果,可能太密集了,不易查看,但代码会输出建议的25组anchor大小:
建议anchor大小
宽度 高度 高宽比
10.000 12.000 1.2
10.000 14.000 1.4
14.000 12.000 0.9
12.000 14.000 1.2
12.000 16.000 1.3
13.000 16.000 1.2
12.000 18.000 1.5
14.000 19.000 1.4
16.000 19.000 1.2
17.000 22.000 1.3
19.000 22.000 1.2
18.000 27.000 1.5
23.000 29.000 1.3
23.000 32.000 1.4
28.000 32.000 1.1
35.000 44.000 1.3
41.000 51.000 1.2
48.000 67.000 1.4
49.000 67.000 1.4
55.000 65.000 1.2
59.000 69.000 1.2
80.000 80.000 1.0
80.000 82.000 1.0
92.000 108.00 1.2
204.00 246.00 1.2
可以看到,建议的anchor高宽比都是1.3左右,另外,还有数据框的分布统计图如下:
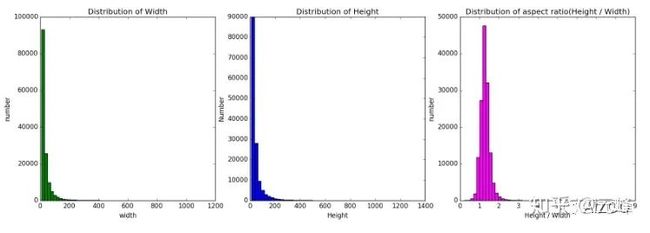
可以看到人脸高宽比例多数都在1.4 : 1左右。所以,对于Wider Face人脸检测,可以将anchor 设置为1:1、1.4:1、 1.7:1,而没必要设置3:1、1:3这种明显不合适的比例(毕竟,脸再长,也很少是3:1这么夸张的比例吧)。对于anchor的大小,可以查看上图的宽度和高度统计,参考聚类结果,设置合理的大小。
4. 注意事项
对于检测网络,有的实现,是用没有归一化的坐标,例如anchor设置为(30, 42)这种尺度大小,但是,有的算法实现,是将坐标和物体框的宽高比,除以图片的宽和高。这里,就需要注意了。如果您的图片都是正方形的,那归一化后宽高比没有变化,如果是1080P这种分辨率的摄像头,那么长宽比是16:9了。本来就小的宽度,再除以1920,而高度除以1080,会导致归一化后的人脸高度是宽度的2倍左右。例如下图,图片宽度约为高度的两倍,归一化后,人脸宽度相比高度要更小很多。

我们将代码中归一化选项打开:
BBOX_NORMALIZE = True再次运行,可以看到统计的高宽比如下图,可以看到高宽比最集中的是2:1(未归一化时是1.4:1),因为WiderFace数据,多数图片也是宽度大于高度的宽图。
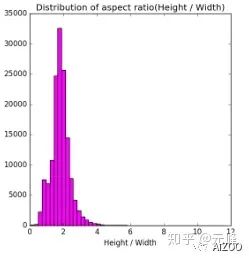
归一化的建议anchor大小如下,可以看到高宽比相比上面未归一化的,明显要更大一些。
建议anchor大小
宽度 高度 高宽比
0.010 0.008 0.8
0.013 0.011 0.9
0.011 0.015 1.4
0.010 0.018 1.8
0.011 0.022 2.1
0.013 0.020 1.5
0.019 0.017 0.9
0.014 0.025 1.8
0.013 0.031 2.4
0.017 0.028 1.7
0.016 0.036 2.3
0.020 0.033 1.7
0.027 0.027 1.0
0.021 0.039 1.9
0.021 0.050 2.3
0.026 0.043 1.6
0.024 0.066 2.7
0.030 0.054 1.8
0.036 0.069 1.9
0.054 0.057 1.1
0.047 0.085 1.8
0.059 0.114 1.9
0.090 0.143 1.6
0.139 0.233 1.7
0.299 0.421 1.4
所以,如果是使用归一化的anchor大小,需要考虑图片的宽高比例问题。
同样,即使您使用的是未归一化的anchor大小,但是如果您将图像直接resize成正方形大小,对于宽幅的图像,也会面临同样的问题,我们将上面的图resize成500x500的正方形,如下,可以看到高宽比进一步加大。当然,如果您的做法是将短边通过padding补零的方式,使图像为正方形,则不存在这个问题的。

好了,总结一下,对于目标检测的anchor 设置,一定要根据您的数据分布设置合理的anchor,另外,也要考虑是否是归一化的anchor大小,或者是否做了改变图像长宽比的resize。
我们的Github代码地址:https://github.com/AIZOOTech/object-detection-anchors
https://mp.weixin.qq.com/s/Qvjk7mz8d9lxeyIMND1mPA