数据挖掘算法和实践(二十一):kaggle经典-职场离职率分析案例解读
本节使用kaggle经典数案例一起学习数据挖掘流程和工具使用,使用决策树和随机森林预测员工离职率,帮助人事部门理解员工为何离职, 预测员工离职的可能性,数据来源: kaggle数据集地址
使用jupyterlab,能够保存中间结果并且流程较清晰,小数据集可以考虑使用,但从模块化思想来看可以用VsCode和其他工具,一如既往首先引入需要的包,这里plot和seaborn都引入了,plot更偏底层可以定制化作图,seaborn作图更方便和炫酷但定制化作图能力弱,想了解seaborn作图包可以参照之前的博客: 数据挖掘算法和实践(六):seaborn数据可视化探索(tips 数据集)
一、数据导入
这里读取本地文件,该数据集较小,只有14999条数据,包含10个特征属性,最后left列为标签;
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
# 读入数据到Pandas Dataframe "df"
df = pd.read_csv('HR_comma_sep.csv', index_col=None)二、数据预处理
1、数据探索
将数据读取到pandas.dataframe容器后,用提供的shape,dtypes,head(),isnull(),describe()观察数据类型和分布,发现14999×10数列不存在空值,第1步把字段名称修改为自己熟悉或者可以接受的字段名称,这里把是否离职放在第一列了;
# 共14999个样本,每一个样本中包含10个特征
df.shape
# 特征数据类型.
df.dtypes
# 检测是否有缺失数据
df.isnull().any()
# 数据的样例
df.head()
# 整数数据分布描述
df.describe()
# 重命名
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})
# 将预测标签‘是否离职’放在第一列
front = df['turnover']
df.drop(labels=['turnover'], axis=1, inplace = True)
df.insert(0, 'turnover', front)
df.head()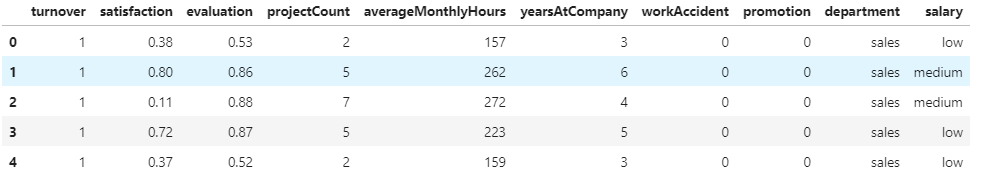
第1步可以算是数据探索,下一步就是牵扯到业务逻辑的探索,比如探究离职率、离职或不离职的其他属性的平均值情况;
# 离职率
turnover_rate = df.turnover.value_counts() / len(df)
turnover_rate
# 离职或者不离职的人其他特征的一些平均数据统计
turnover_Summary = df.groupby('turnover')
turnover_Summary.mean()
2、相关性分析
更进一步,考察特征属性间的相关性,相关性分析能够做到特征规约和整合,即多个特征可以合并,或者被舍弃;
# 相关性矩阵
corr = df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
corr
正相关的特征:
- projectCount VS evaluation: 0.349333
- projectCount VS averageMonthlyHours: 0.417211
- averageMonthlyHours VS evaluation: 0.339742
负相关的特征:
- satisfaction VS turnover: -0.388375
思考:
- 什么特征的影响最大?
- 什么特征之间相关性最大?
3、单变量探索
满意度字段:未离职员工满意度: 0.666809590479524,离职员工满意度: 0.4400980117614114;
# 比较离职和未离职员工的满意度
emp_population = df['satisfaction'][df['turnover'] == 0].mean()
emp_turnover_satisfaction = df[df['turnover']==1]['satisfaction'].mean()
print( '未离职员工满意度: ' + str(emp_population))
print( '离职员工满意度: ' + str(emp_turnover_satisfaction) )满意度的T-test,查看p值;T-Test 显示pvalue (0)非常小, 所以他们之间是显著不同的;
import scipy.stats as stats
# 满意度的t-Test
stats.ttest_1samp(a = df[df['turnover']==1]['satisfaction'], # 离职员工的满意度样本
popmean = emp_population) # 未离职员工的满意度均值
degree_freedom = len(df[df['turnover']==1])
# 临界值
LQ = stats.t.ppf(0.025,degree_freedom) # 95%致信区间的左边界
RQ = stats.t.ppf(0.975,degree_freedom) # 95%致信区间的右边界
print ('The t-分布 左边界: ' + str(LQ))
print ('The t-分布 右边界: ' + str(RQ))
# 工作评价的概率密度函数估计
fig = plt.figure(figsize=(15,4),)
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'evaluation'] , color='b',shade=True,label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'evaluation'] , color='r',shade=True, label='turnover')
ax.set(xlabel='工作评价', ylabel='频率')
plt.title('工作评价的概率密度函数 - 离职 V.S. 未离职')
# 月平均工作时长概率密度函数估计
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'averageMonthlyHours'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'averageMonthlyHours'] , color='r',shade=True, label='turnover')
ax.set(xlabel='月工作时长(时)', ylabel='频率')
plt.title('月工作时长(时) - 离职 V.S. 未离职')
# 员工满意度概率密度函数估计
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'satisfaction'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'satisfaction'] , color='r',shade=True, label='turnover')
plt.title('员工满意度 - 离职 V.S. 未离职')三、建模和评估
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, confusion_matrix, precision_recall_curve
# 将string类型转换为整数类型
df["department"] = df["department"].astype('category').cat.codes
df["salary"] = df["salary"].astype('category').cat.codes
# 产生X, y,即特征值与目标值
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y = df[target_name]
# 将数据分为训练和测试数据集
# 注意参数 stratify = y 意味着在产生训练和测试数据中, 离职的员工的百分比等于原来总的数据中的离职的员工的百分比
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.15, random_state=123, stratify=y)
# 显示前5行数据
df.head()
四、决策树和随机森林Decision Tree V.S. Random Forest
1、决策树和可视化
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
# 实例化
dtree = tree.DecisionTreeClassifier(
criterion='entropy',
#max_depth=3, # 定义树的深度, 可以用来防止过拟合
min_weight_fraction_leaf=0.01 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合
)
# 训练
dtree = dtree.fit(X_train,y_train)
# 指标计算
dt_roc_auc = roc_auc_score(y_test, dtree.predict(X_test))
print ("决策树 AUC = %2.2f" % dt_roc_auc)
print(classification_report(y_test, dtree.predict(X_test)))
# 需安装GraphViz和pydotplus进行决策树的可视化
# 特征向量
feature_names = df.columns[1:]
# 文件缓存
dot_data = StringIO()
# 将决策树导入到dot中
export_graphviz(dtree, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_names,class_names=['0','1'])
# 将生成的dot文件生成graph
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# 将结果存入到png文件中
graph.write_png('diabetes.png')
# 显示
Image(graph.create_png())
决策树的特征重要性分析
# 获取特征重要性
importances = dtree.feature_importances_
# 获取特征名称
feat_names = df.drop(['turnover'],axis=1).columns
# 排序
indices = np.argsort(importances)[::-1]
# 绘图
plt.figure(figsize=(12,6))
plt.title("Feature importances by Decision Tree")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()
2、随机森林和可视化
# 实例化随机森林
rf = RandomForestClassifier(
criterion='entropy',
n_estimators=3,
max_depth=None, # 定义树的深度, 可以用来防止过拟合
min_samples_split=10, # 定义至少多少个样本的情况下才继续分叉
#min_weight_fraction_leaf=0.02 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合
)
# 模型训练
rf.fit(X_train, y_train)
# 计算指标参数
rf_roc_auc = roc_auc_score(y_test, rf.predict(X_test))
print ("随机森林 AUC = %2.2f" % rf_roc_auc)
print(classification_report(y_test, rf.predict(X_test)))
# Graphviz中未提供多棵树的绘制方法,所以我们遍历森林中的树,分别进行绘制
Estimators = rf.estimators_
# 遍历
for index, model in enumerate(Estimators):
# 文件缓存
dot_data = StringIO()
# 将决策树导入到dot_data中
export_graphviz(model , out_file=dot_data,
feature_names=df.columns[1:],
class_names=['0','1'],
filled=True, rounded=True,
special_characters=True)
# 从数据中生成graph
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# 将结果写入到png文件中
graph.write_png('Rf{}.png'.format(index))
# 绘制图像
plt.figure(figsize = (20,20))
plt.imshow(plt.imread('Rf{}.png'.format(index)))
plt.axis('off')
# 特征的重要程度
importances = rf.feature_importances_
# 特征名称
feat_names = df.drop(['turnover'],axis=1).columns
# 排序
indices = np.argsort(importances)[::-1]
# 绘图
plt.figure(figsize=(12,6))
plt.title("Feature importances by RandomForest")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()
3、ROC曲线
# ROC 图
from sklearn.metrics import roc_curve
# 计算ROC曲线
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(X_test)[:,1])
dt_fpr, dt_tpr, dt_thresholds = roc_curve(y_test, dtree.predict_proba(X_test)[:,1])
plt.figure()
# 随机森林 ROC
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rf_roc_auc)
# 决策树 ROC
plt.plot(dt_fpr, dt_tpr, label='Decision Tree (area = %0.2f)' % dt_roc_auc)
# 绘图
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Graph')
plt.legend(loc="lower right")
plt.show() 