GoogLeNet( Going deeper with convolutions)解读
Introduction
GoogLeNet是业界经典的一种深度结构,整个网络有22层,之所以称为GoogLeNet,作者说是为了致敬Yann LCun 的LeNet。
从LeNet-5开始,CNN有一个很标准的结构,一堆卷积层,后面可能跟上Norm和max-pooling层,然后接上一层或者全连接层。论文的工作主要集中在探索一种高效的深度神经网络结构,代号是Inception,概念主要来自于Network in network的工作,有点类似于盗梦空间的梦中梦,并且“We need to go deeper” 的概念。Deep 本身也有两层意思,一是引进了一种以“Inception module”形式新的层的组织方式,二是网络深度增加的直观感觉。GoogLeNet在ImageNe2014t分类和检测上都拿到了第一。
Motivation and High Level Considerations
深度学习提高性能最直接的方式是增加网络的深度(网络层数)和宽度(每层的神经元个数),如果我们有足够大的labeled数据集,这个是简单可靠的方法,但是事实并不是这样的,主要体现在两个方面:首先更深更宽的网络意味着更多的参数,模型更容易overfitting,尤其数据量不够的时候,而数据的标注是一项成本很高的工作,这是主要的瓶颈;二是更多的参数也是意味着更加巨大的计算量,而在实际情况中计算资源总是有限的。
为了解决上述两个问题,最基本的方式是把全连接层转换为稀疏连接的结构,因为我们都知道全连接层占据了参数中的很大一部分,甚至在卷积层也可以做一些稀疏工作。一方面是模仿生物学系统,另一方面是有研究表明数据集的分布可以由一个非常稀疏的深度网络来表达,最优的网络拓扑可以通过逐层分析激活的统计特性,然后聚集神经元到高度相关的神经元输出上;虽然严格的数学证明需要很强的条件,但是Hebbian principle(neurons that fire together,wire together)表明在实际运用中是可行的。
但是值得注意的一点是,尽管提出的结构在计算机视觉上有很大的成功,但是是否它的质量可以根据构建的指导原则属性化依然是存在疑问的,最好的证明方式是能够有一个自动系统,他能够用相同的算法在其他领域创建出看起来很不同的网路拓扑结构,但是结果依旧很好。
Architectural Details
Inception结构的主要思想是发掘最优的局部稀疏结构来近似密集成分。
最初的结构如图:

几个细节:
为了解决对齐的问题,卷积核限制为1*1,3*3和5*5,但是这个不是必须的,只是为了方便而已;
中间这些层的输出进行组合作为下一个阶段的输入;
因为在现有的state of art的CNN中,pooling操作是必须的,所以也加入了pooling层;
由于越高层,特征越抽象,3*3和5*5的卷积核的比例是要增加的;
Inception初步结构的问题是5*5卷积核在高层计算时很expensive的,因此在几个阶段后计算就会爆炸了,所以提出了一个改进结构,如图:

在计算量增加太多的地方,加入1*1的卷积来进行降维(降低输入的通道数),来解决计算瓶颈的问题;举个例子,输入的feature map是28×28×192,1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64 3×3×192×128 5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64 (1×1×192×96 3×3×96×128) (1×1×192×16 5×5×16×32),参数大约减少到原来的三分之一。所以这个结构很有价值的一个方面是随着每个stage神经元数目的增加,不会产生不可控的计算复杂度的爆炸性增长;另一个很有用的点是视觉信息应该在不同scales下进行处理然后再聚合以便下个阶段可以直接同时处理不同scales下的抽象特征。
相比于类似性能的non-Inception网络,速度可以快2-3倍,但是需要小心的设计Inception结构。
具体22层(不包括pooling层,包括的话是27层)结构如下:
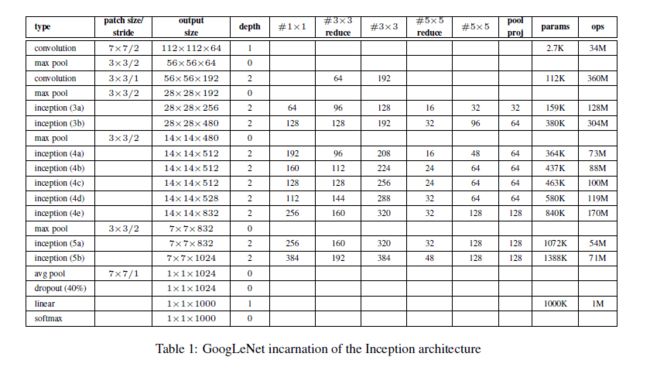
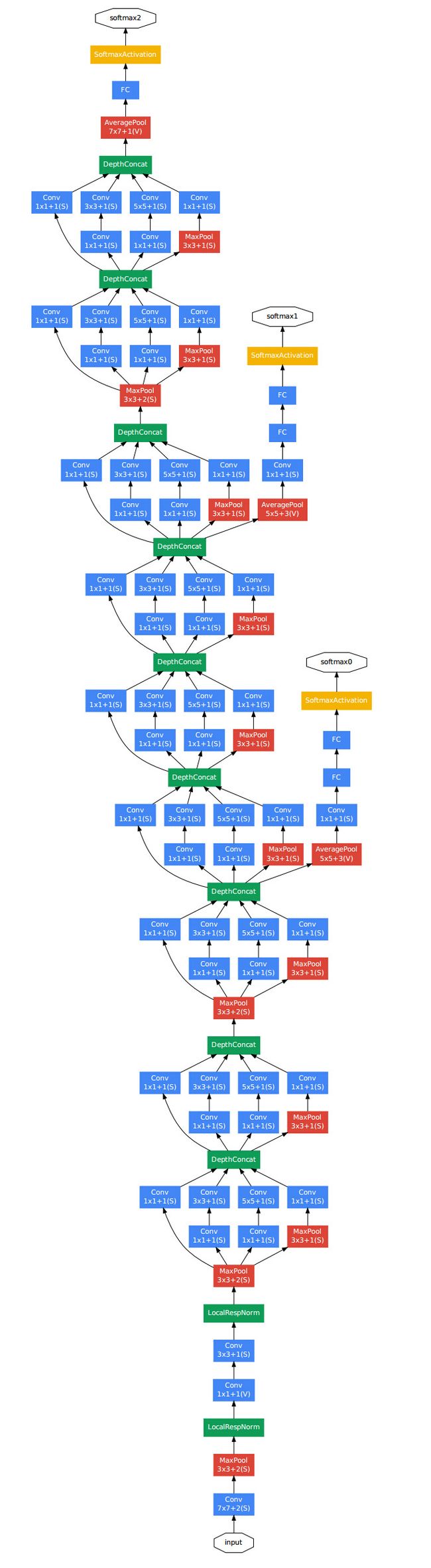
注: 中间层的输出作为辅助,在训练时中间层输出的loss*0.3加到总loss里面,而在测试时时丢弃的。