OCR文字检测框的合并
OCR文字检测框的合并
项目的github地址:https://github.com/zcswdt/merge_text_boxs
在我们使用文字检测模型的对文本进行检测的时候,可能效果不能如愿以偿,如:某行文本会存在着多个检测框,这对于我们后续做OCR识别过程中语义连贯带来一系列的困扰,本文主要是解决针对文字检测得到的文字框,进行合并。
1.如下是一张原始图片:

2.使用常见的文字检测模型(craft,DBNet,PSENet)对该图片进行文字检测得到的效果如下:

- 使用如下代码对文字框进行x轴上的合并,得到的效果如下:
import numpy as np
def get_rect_points(text_boxes):
x1 = np.min(text_boxes[:, 0])
y1 = np.min(text_boxes[:, 1])
x2 = np.max(text_boxes[:, 2])
y2 = np.max(text_boxes[:, 3])
return [x1, y1, x2, y2]
class BoxesConnector(object):
def __init__(self, rects, imageW, max_dist=None, overlap_threshold=None):
print('max_dist',max_dist)
print('overlap_threshold',overlap_threshold )
self.rects = np.array(rects)
self.imageW = imageW
self.max_dist = max_dist # x轴方向上合并框阈值
self.overlap_threshold = overlap_threshold # y轴方向上最大重合度
self.graph = np.zeros((self.rects.shape[0], self.rects.shape[0])) # 构建一个N*N的图 N等于rects的数量
self.r_index = [[] for _ in range(imageW)] # 构建imageW个空列表
for index, rect in enumerate(rects): # r_index第rect[0]个元素表示 第index个(数量可以是0/1/大于1)rect的x轴起始坐标等于rect[0]
if int(rect[0]) < imageW:
self.r_index[int(rect[0])].append(index)
else: # 边缘的框旋转后可能坐标越界
self.r_index[imageW - 1].append(index)
print(self.r_index)
def calc_overlap_for_Yaxis(self, index1, index2):
# 计算两个框在Y轴方向的重合度(Y轴错位程度)
height1 = self.rects[index1][3] - self.rects[index1][1]
height2 = self.rects[index2][3] - self.rects[index2][1]
y0 = max(self.rects[index1][1], self.rects[index2][1])
y1 = min(self.rects[index1][3], self.rects[index2][3])
print('y1', y1)
Yaxis_overlap = max(0, y1 - y0) / max(height1, height2)
print('Yaxis_overlap', Yaxis_overlap)
return Yaxis_overlap
def get_proposal(self, index):
rect = self.rects[index]
print('rect',rect)
for left in range(rect[0] + 1, min(self.imageW - 1, rect[2] + self.max_dist)):
#print('left',left)
for idx in self.r_index[left]:
print('58796402',idx)
# index: 第index个rect(被比较rect)
# idx: 第idx个rect的x轴起始坐标大于被比较rect的x轴起始坐标(+max_dist)且小于被比较rect的x轴终点坐标(+max_dist)
if self.calc_overlap_for_Yaxis(index, idx) > self.overlap_threshold:
return idx
return -1
def sub_graphs_connected(self):
sub_graphs = [] #相当于一个堆栈
for index in range(self.graph.shape[0]):
# 第index列全为0且第index行存在非0
if not self.graph[:, index].any() and self.graph[index, :].any(): #优先级是not > and > or
v = index
print('v',v)
sub_graphs.append([v])
print('sub_graphs', sub_graphs)
# 级联多个框(大于等于2个)
print('self.graph[v, :]', self.graph[v, :])
while self.graph[v, :].any():
v = np.where(self.graph[v, :])[0][0] #np.where(self.graph[v, :]):(array([5], dtype=int64),) np.where(self.graph[v, :])[0]:[5]
print('v11',v)
sub_graphs[-1].append(v)
print('sub_graphs11', sub_graphs)
return sub_graphs
def connect_boxes(self):
for idx, _ in enumerate(self.rects):
proposal = self.get_proposal(idx)
print('idx11', idx)
print('proposal',proposal)
if proposal >= 0:
self.graph[idx][proposal] = 1 # 第idx和proposal个框需要合并则置1
sub_graphs = self.sub_graphs_connected() #sub_graphs [[0, 1], [3, 4, 5]]
# 不参与合并的框单独存放一个子list
set_element = set([y for x in sub_graphs for y in x]) #{0, 1, 3, 4, 5}
for idx, _ in enumerate(self.rects):
if idx not in set_element:
sub_graphs.append([idx]) #[[0, 1], [3, 4, 5], [2]]
result_rects = []
for sub_graph in sub_graphs:
rect_set = self.rects[list(sub_graph)] #[[228 78 238 128],[240 78 258 128]].....
print('1234', rect_set)
rect_set = get_rect_points(rect_set)
result_rects.append(rect_set)
return np.array(result_rects)
4.我们可以构造一些框,画在一张白纸上看看合并的效果如何,我编造了12个框,并且画在了一张白纸上,接下来是我自己构造并且合并的效果:
if __name__ == '__main__':
import cv2
rects = []
rects = [[144, 5, 192, 25], [25, 6, 64, 25], [66, 6, 141, 25], [193, 5, 275, 33], [269, 30, 354, 50], [26, 30, 182, 52],[185, 28, 265, 55], [25, 56, 89, 76], [93, 56, 229, 78], [232, 56, 262, 76], [264, 52, 343, 81]]
#创建一个白纸
show_image = np.zeros([500, 500, 3], np.uint8) + 255
connector = BoxesConnector(rects, 500, max_dist=15, overlap_threshold=0.2)
new_rects = connector.connect_boxes()
print(new_rects)
for rect in rects:
cv2.rectangle(show_image, (rect[0], rect[1]), (rect[2], rect[3]), (0, 0, 255), 1)
for rect in new_rects:
cv2.rectangle(show_image,(rect[0], rect[1]), (rect[2], rect[3]),(255,0,0),1)
cv2.imshow('res', show_image)
cv2.waitKey(0)
5.原始的坐标框一共有12个,画在白纸上如下图,使用该代码对文字检测模型检测的图片进行文字框进行x轴上的合并,得到的效果如下:
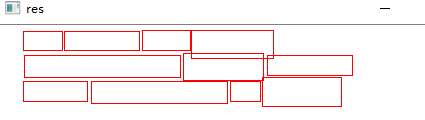
经过文字框合并之后仅仅有三个框,效果如下

- 当然我们有时候需要的是要将文字框进行按照区域进行合并,这样更能有利于提取该区域的文本内容的连贯性,不能说不同区域的文本在经过文字识别后不能组合到一起,形成语义信息。所以接下来我们需要对在x轴合并的文本框进行区域合并:
import numpy as np
def get_rect_points(text_boxes):
x1 = np.min(text_boxes[:, 0])
y1 = np.min(text_boxes[:, 1])
x2 = np.max(text_boxes[:, 2])
y2 = np.max(text_boxes[:, 3])
return [x1, y1, x2, y2]
class BoxesConnector(object):
def __init__(self, rects, imageW, max_dist=5, overlap_threshold=0.2):
self.rects = np.array(rects)
self.imageW = imageW
self.max_dist = max_dist # x轴方向上合并框阈值
self.overlap_threshold = overlap_threshold # y轴方向上最大重合度
self.graph = np.zeros((self.rects.shape[0], self.rects.shape[0])) # 构建一个N*N的图 N等于rects的数量
self.r_index = [[] for _ in range(imageW)] # 构建imageW个空列表
for index, rect in enumerate(rects): # r_index第rect[0]个元素表示 第index个(数量可以是0/1/大于1)rect的x轴起始坐标等于rect[0]
if int(rect[1]) < imageW:
self.r_index[int(rect[1])].append(index)
else: # 边缘的框旋转后可能坐标越界
self.r_index[imageW - 1].append(index)
print('self.r_index',self.r_index)
print('len(self.r_index)', len(self.r_index))
def calc_overlap_for_Yaxis(self, index1, index2):
# 计算两个框在Y轴方向的重合度(Y轴错位程度)
height1 = self.rects[index1][3] - self.rects[index1][1]
height2 = self.rects[index2][3] - self.rects[index2][1]
y0 = max(self.rects[index1][1], self.rects[index2][1])
y1 = min(self.rects[index1][3], self.rects[index2][3])
Yaxis_overlap = max(0, y1 - y0) / max(height1, height2)
return Yaxis_overlap
def calc_overlap_for_Xaxis(self, index1, index2):
# 计算两个框在Y轴方向的重合度(Y轴错位程度)
width1 = self.rects[index1][2] - self.rects[index1][0]
width2 = self.rects[index2][2] - self.rects[index2][0]
x0 = max(self.rects[index1][0], self.rects[index2][0])
x1 = min(self.rects[index1][2], self.rects[index2][2])
Yaxis_overlap = max(0, x1 - x0) / max(width1, width2)
print('Yaxis_overlap', Yaxis_overlap)
return Yaxis_overlap
def get_proposal(self, index):
rect = self.rects[index]
for left in range(rect[1] + 1, min(self.imageW - 1, rect[3] + self.max_dist)):
for idx in self.r_index[left]:
print('56871',idx)
# index: 第index个rect(被比较rect)
# idx: 第idx个rect的x轴起始坐标大于被比较rect的x轴起始坐标(+max_dist)且小于被比较rect的x轴终点坐标(+max_dist)
if self.calc_overlap_for_Xaxis(index, idx) > self.overlap_threshold:
return idx
return -1
def sub_graphs_connected(self):
sub_graphs = [] #相当于一个堆栈
for index in range(self.graph.shape[0]):
# 第index列全为0且第index行存在非0
if not self.graph[:, index].any() and self.graph[index, :].any(): #优先级是not > and > or
v = index
print('v',v)
sub_graphs.append([v])
print('sub_graphs', sub_graphs)
# 级联多个框(大于等于2个)
print('self.graph[v, :]', self.graph[v, :])
while self.graph[v, :].any():
v = np.where(self.graph[v, :])[0][0] #np.where(self.graph[v, :]):(array([5], dtype=int64),) np.where(self.graph[v, :])[0]:[5]
print('v11',v)
sub_graphs[-1].append(v)
print('sub_graphs11', sub_graphs)
return sub_graphs
def connect_boxes(self):
for idx, _ in enumerate(self.rects):
print('idx', idx)
proposal = self.get_proposal(idx)
print('proposal',proposal)
if proposal > 0:
self.graph[idx][proposal] = 1 # 第idx和proposal个框需要合并则置1
sub_graphs = self.sub_graphs_connected() #sub_graphs [[0, 1], [3, 4, 5]]
# 不参与合并的框单独存放一个子list
set_element = set([y for x in sub_graphs for y in x]) #{0, 1, 3, 4, 5}
for idx, _ in enumerate(self.rects):
if idx not in set_element:
sub_graphs.append([idx]) #[[0, 1], [3, 4, 5], [2]]
result_rects = []
for sub_graph in sub_graphs:
rect_set = self.rects[list(sub_graph)] #[[228 78 238 128],[240 78 258 128]].....
print('1234', rect_set)
rect_set = get_rect_points(rect_set)
result_rects.append(rect_set)
return np.array(result_rects)
接下来构建一张白纸来演示一下代码的合并效果:
if __name__ == '__main__':
import cv2
rects = []
#在y轴上的合并
rects.append(np.array([50, 50, 130, 80]))
rects.append(np.array([50, 90, 100, 125]))
rects.append(np.array([50, 135, 150, 167]))
rects.append(np.array([180, 50, 270, 82]))
rects.append(np.array([180, 92, 270, 125]))
rects.append(np.array([180, 135, 210, 170]))
rects.append(np.array([50, 220, 110, 251]))
rects.append(np.array([50, 261, 130, 289]))
rects.append(np.array([130, 190, 210, 210]))
#创建一个白纸
show_image = np.zeros([400, 400, 3], np.uint8) + 255
connector = BoxesConnector(rects, 400, max_dist=15, overlap_threshold=0.3)
new_rects = connector.connect_boxes()
print(new_rects)
for rect in rects:
cv2.rectangle(show_image, (rect[0], rect[1]), (rect[2], rect[3]), (0, 0, 255), 1)
# for rect in new_rects:
# cv2.rectangle(show_image,(rect[0], rect[1]), (rect[2], rect[3]),(255,0,0),1)
cv2.imshow('res', show_image)
cv2.waitKey(0)
res是使用了9个文本框来演示:

res_c中的蓝色文本框是经过文本区域合并以后的文字框:
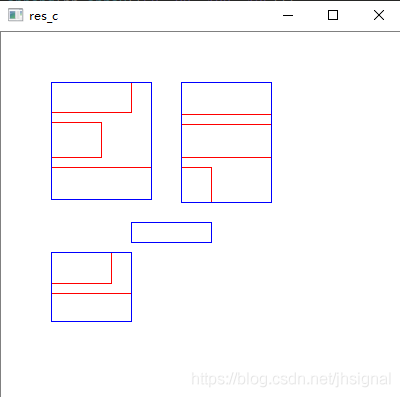
真实效果如下:绿色框是我们在沿着x轴进行的文字框合并,而蓝色的文本框才是经过区域合并的效果:
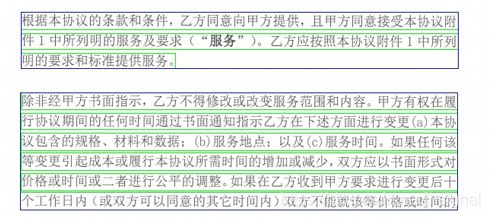
使用文本x轴方向的合并,和文本区域合并,有利用将大块区域的文本提取到一起,这样更有利于OCR文字识别时的组合语义之间的连贯性。