pytorch学习笔记(六)——pytorch进阶教程之tensor数学运算
pytorch学习笔记(六)——pytorch进阶教程之合并与分割
- 目录
-
- tensor的加减乘除----add/sub/mul/div
- tensor的矩阵相乘----mm,matmul/@
-
- 2d以上的tensor矩阵相乘
- tensor的次方----pow/sqrt/rsqrt/exp/log
- tensor的其他运算----floor/ceil/round/trunc/frac
- tensor的其他运算----clamp(用的多)
目录
tensor的加减乘除----add/sub/mul/div
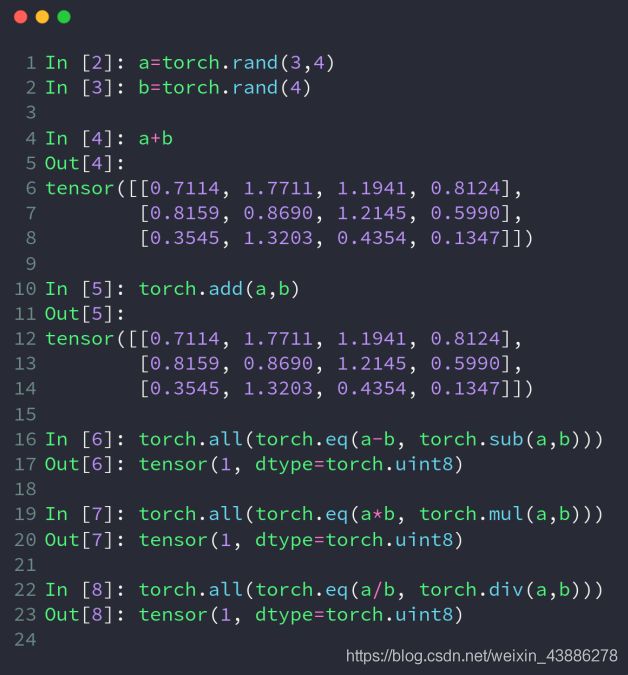
在pytorch中加减乘除既可以用一般的运算符±*/,也可以用pytorch内置函数代替,对应如上图,a和b的size不一样但可以相加的原因是因为broadcast机制。
tensor的矩阵相乘----mm,matmul/@
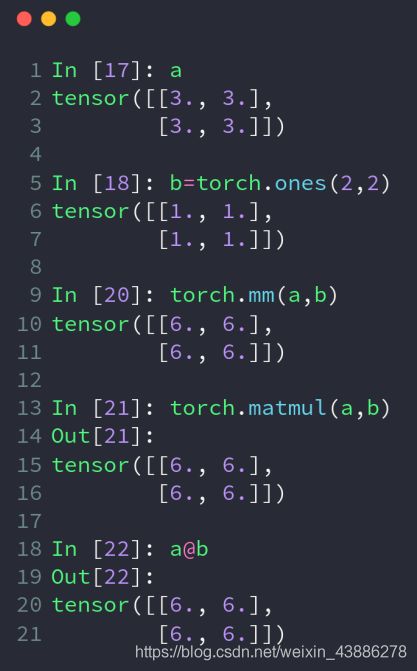
要注意:×和matmul是不一样的,×表示矩阵中对应元素相乘,matmul则表示矩阵相乘
mm函数只能用于二维矩阵相乘,matmul可以运用于任意维度,@是matmul的简略写法。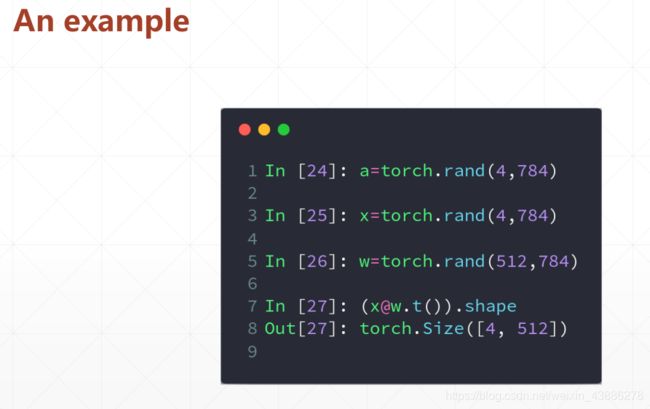
x的size是[4,784],我们现在想要把x降维成[4,512]格式的,所以生成w:[512,784]
(pytorch中默认要这样写,实际上也可直接生成w:[784,512]而不用进行转置),再用x矩阵乘以w的转置,得到[4,512]的结果。
2d以上的tensor矩阵相乘
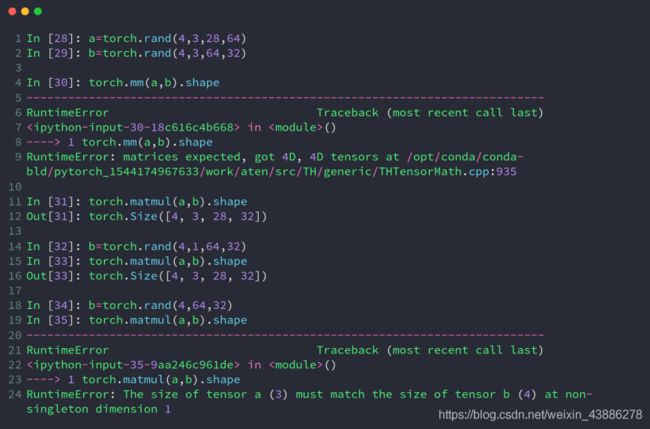
我们可以看到超过二维使用mm会直接报错,使用matmal会直接对最后两个维度进行矩阵运算,前提是前面的维度长度一致,若前面的维度长度有不一致则进行broadcast维度扩展到一致,如[4,3,28,64]和[4,1,64,32],[4,1,64,32]==>[4,3,64,32],在矩阵相乘得到[4,3,28,32]。当然也有无法broadcast的时候,如最后一行代码,会直接报错。
tensor的次方----pow/sqrt/rsqrt/exp/log
pow/sqrt/rsqrt
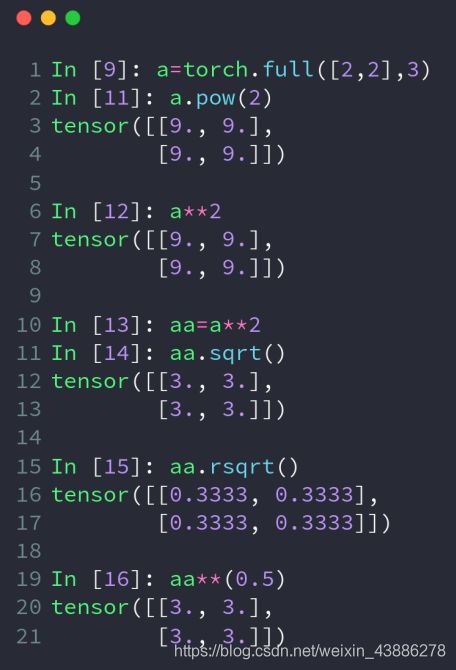
full([2,2],3)表示生成一个shape为[2,2]的tensor,初始化值都是3
这里: pow(tensor, 次方)第一个参数为Tensor,第二个参数表示次方,比如2次方,三次方,四次方等等。
pow ××都是接幂次方,sqrt表示平方根,rsqrt表示平方根的倒数
exp/log
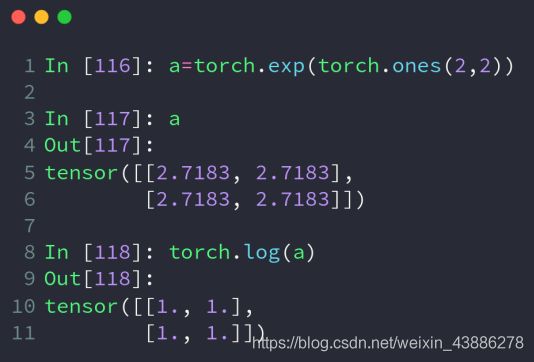
exp以e为底数
log以e为底数取对数
tensor的其他运算----floor/ceil/round/trunc/frac

floor 向下取整
ceil 向上取整
trunc 裁剪整数部分
frac 裁剪小数部分
round 四舍五入
tensor的其他运算----clamp(用的多)

这里: 主要用在梯度裁剪里面,梯度离散(不需要从网络层面解决,因为梯度非常小,接近0)和梯度爆炸(梯度非常大,100已经算是大的了)。因此在网络训练不稳定的时候,可以打印一下梯度的模看看,w.grad.norm(2)表示梯度的二范数(一般100,1000已经算是大的了,一般10以内算是合适的)。
a.clamp(min):表示tensor a中小于10的都赋值为10,表示最小值为10;
torch.clamp(input, min, max, out=None) → Tensor
将输入input张量每个元素的夹紧到区间 [min,max],并返回结果到一个新张量。
操作定义如下:
| min, if x_i < min
y_i = | x_i, if min <= x_i <= max
| max, if x_i > max