详解pandas数据分析之groupby分组聚合(基于电商平台数据)
该篇文章基于电商的商品数据信息,详细介绍pandas数据分析之分组聚合的方法与技巧(保密起见,只展示部分数据)。
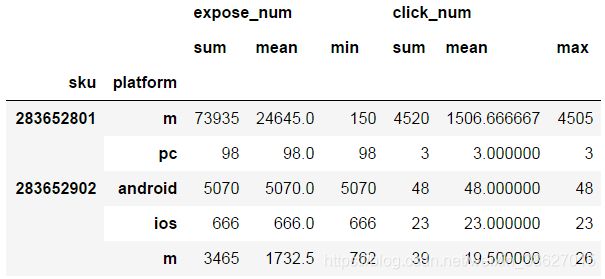
分组聚合结果展示:
文章目录:
一、导入pandas包并读取数据集
数据
数据字段说明
二、分组
1、生成分组对象
2、查看分组对象类型
3、查看分组对象的方法(函数)
4、查看分组数量
5、查看各分组
6、查看各分组索引
7、查看各分组的唯一识别标签
8、获取某个分组数据
9、group_obj分组对象可迭代
10、group_obj对象使用head方法
11、nth方法可以选出每个分组指定行的数据
三、分组聚合
一)单字段分组聚合
方式一(灵活性高):使用agg方法,以字典格式传入要聚合的字段和聚合函数
方式二:将聚合的字段作为索引,聚合函数传入agg
方式三:直接将函数名作为字符串传入agg
方式四:直接使用mean()函数
二)多字段分组聚合
1、多字段分组、单字段聚合
2、多字段分组、多字段聚合
3、多字段分组、多字段聚合、多个聚合函数
4、拼接列索引
5、重置行索引
三)自定义聚合函数
1、单字段自定义函数
2、多字段自定义函数
3、同时传入自定义聚合函数与系统函数
4、修改列名
5、实现自定义函数传参
6、注意事项
7、自定义函数传参与内置函数共用
一、导入pandas包并读取数据集
import pandas as pd
df = pd.read_excel('./data/sku_analysis.xlsx')数据
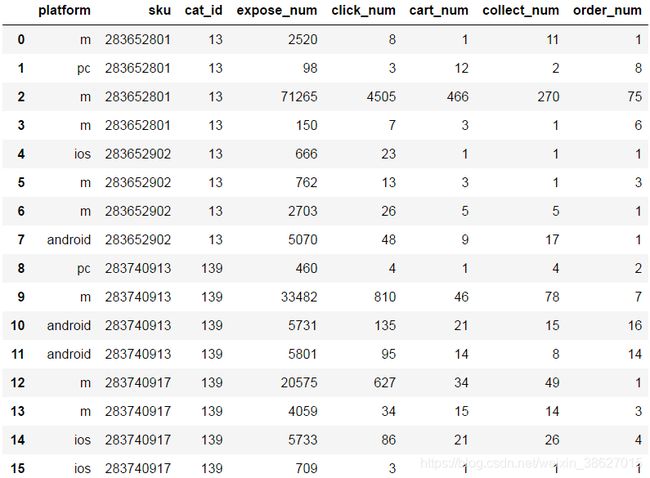
数据字段说明
1、platform:用户使用的终端设备类型,分pc端、m端、ios端、android端。
2、sku:某款特点商品的唯一编号。
3、expose_num:商品sku的累计曝光数。
4、click_num:商品sku的累计点击数。
5、cart_num:商品sku的累计加购数。
6、collect_num:商品sku的累计收藏数。
7、order_num:商品sku的累计下单数。
二、分组
1、生成分组对象
按sku进行分组,代码如下:
group_obj = df.groupby('sku')2、查看分组对象类型
type(group_obj)![]()
3、查看分组对象的方法(函数)
print([func for func in dir(group_obj) if not func .startswith('_')])
#startswith() 方法用于检查字符串是否是以指定子字符串开头,
# 如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。输出:

4、查看分组数量
group_obj.ngroups![]()
5、查看各分组
group_obj.groups
6、查看各分组索引
group_obj.indices
7、查看各分组的唯一识别标签
list(group_obj.groups.keys())8、获取某个分组数据
group_obj.get_group(283652801)
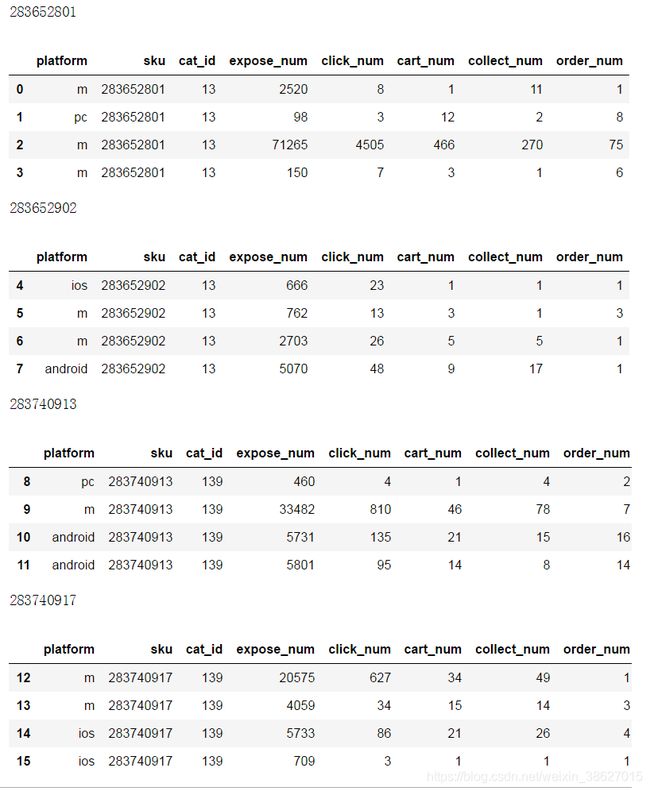
9、group_obj分组对象可迭代
for name, group in group_obj:
print(name)
display(group)输出:
10、group_obj对象使用head方法
可以在一个DataFrame中显示每个分组的前几行
每个分组显示两行,共八行(设定十行,但数据只有八行可显示)
group_obj.head(2).head(10)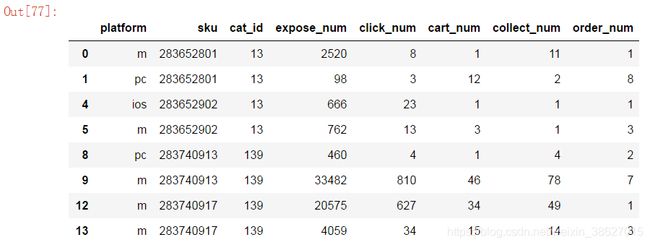
11、nth方法可以选出每个分组指定行的数据
选出第1行和第3行
group_obj.nth([0,2]).head(8)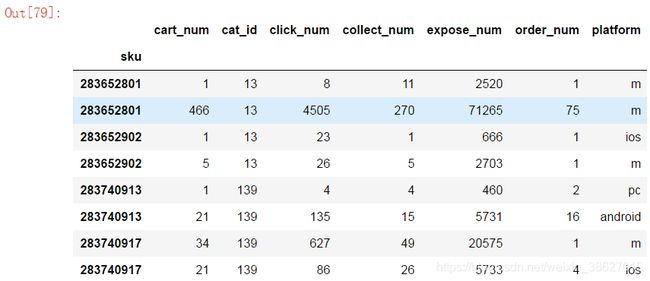
三、分组聚合
一)单字段分组聚合
统计不同sku的总曝光数
方式一(灵活性高):使用agg方法,以字典格式传入要聚合的字段和聚合函数
df.groupby('sku').agg({'expose_num':'sum'})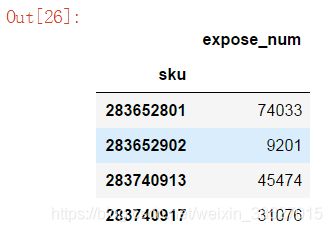
方式二:将聚合的字段作为索引,聚合函数传入agg
df.groupby('sku')['expose_num'].agg(np.sum)
方式三:直接将函数名作为字符串传入agg
df.groupby('sku')['expose_num'].agg('sum')
方式四:直接使用mean()函数
df.groupby('sku')['expose_num'].sum()
二)多字段分组聚合
1、多字段分组、单字段聚合
统计不同sku在不同设备端的总曝光数
df.groupby(['sku', 'platform'])['expose_num'].agg('sum')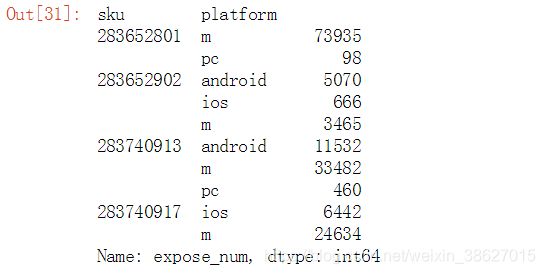
2、多字段分组、多字段聚合
统计不同sku在不同设备端的总曝光数及总点击数
df.groupby(['sku', 'platform'])['expose_num','click_num'].agg('sum')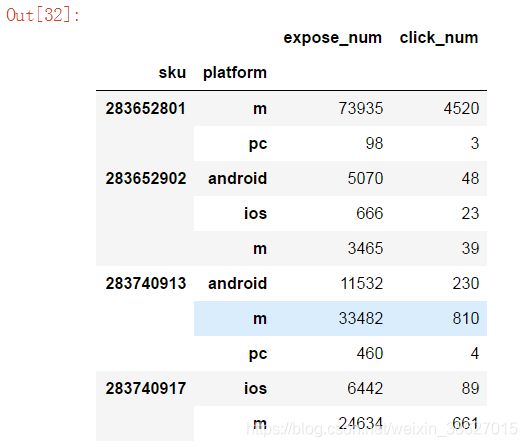
3、多字段分组、多字段聚合、多个聚合函数
1)多字段共用聚合函数
统计不同sku在不同设备端的总曝光数与平均曝光数、总点击数与平均点击数
df.groupby(['sku', 'platform'])['expose_num','click_num'].agg(['sum','mean'])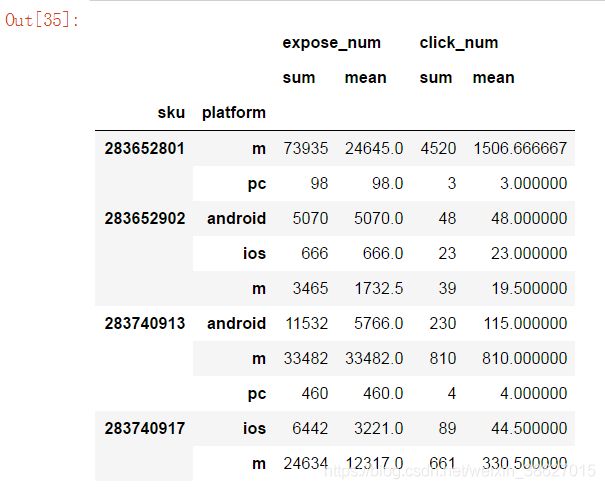
2)多字段各自用聚合函数
统计不同sku在不同设备端的总曝光数、平均曝光数与最小曝光数、总点击数、平均点击数与最大点击数
df.groupby(['sku', 'platform']).agg({'expose_num':['sum','mean','min'],'click_num':['sum','mean','max']})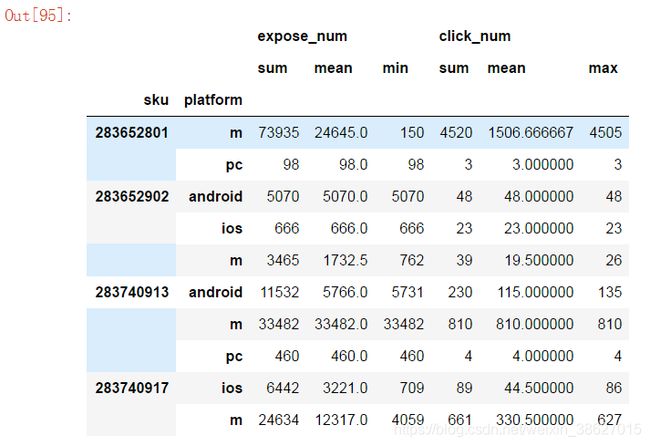
4、拼接列索引
将多级列索引自定义拼接为单级索引
group_obj = df.groupby(['sku', 'platform']).agg({'expose_num':['sum','mean','min'],'click_num':['sum','mean','max']})
index0 = group_obj.columns.get_level_values(0)
index1 = group_obj.columns.get_level_values(1)
group_obj.columns = index0 + '_' + index1
group_obj
5、重置行索引
将多级行索引变为单级索引
group_obj = df.groupby(['sku', 'platform']).agg({'expose_num':['sum','mean','min'],'click_num':['sum','mean','max']})
group_obj.reset_index()
等效于分组时指定as_index=False:
df.groupby(['sku', 'platform'],as_index=False).agg({'expose_num':['sum','mean','min'],'click_num':['sum','mean','max']})
三)自定义聚合函数
1、单字段自定义函数
自定义函数求取各个sku的平均曝光数
agg在调用自定义函数时,直接引入自定义的函数名,字段名作为参数。
def mean_func(s):
score = s.sum()/s.size
return score
df.groupby('sku')['expose_num'].agg(mean_func).round(1).head()#round(1)保留一位小数
2、多字段自定义函数
可同时对多个字段应用自定义函数,各个字段分别传入,分别得出结果。
def mean_func(s):
score = s.sum()/s.size
return score
df.groupby('sku')['expose_num','click_num','cart_num'].agg(mean_func).round(2).head()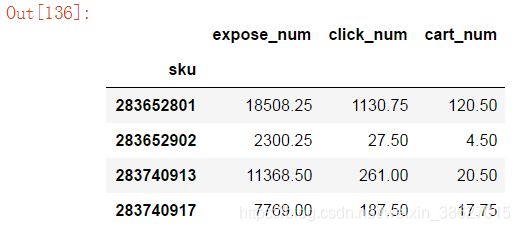
3、同时传入自定义聚合函数与系统函数
def mean_func(s):
score = s.sum()/s.size
return score
df.groupby('sku')['expose_num','click_num','cart_num'].agg([mean_func,'mean']).round(2).head()
4、修改列名
上面自定义函数计算出的索引名为函数名,可对其作更改。
def mean_func(s):
score = s.sum()/s.size
return score
mean_func.__name__ = 'mean_1'
df.groupby('sku')['expose_num','click_num','cart_num'].agg([mean_func,'mean']).round(2).head()
5、实现自定义函数传参
统计数量在10000以上的频率
def pct_func(s,low,high):
score = s.between(low,high).mean()
return score
mean_func.__name__ = 'pct'
df.groupby('sku')['expose_num','click_num','cart_num'].agg(pct_func,low=0,high=10000).round(2).head()
6、注意事项
注意:实现自定义函数传参的同时与内置函数共用,以下方式均会报错:
df.groupby('sku')['expose_num','click_num','cart_num'].agg([mean,pct_func,low=0,high=10000]).round(2).head()df.groupby('sku')['expose_num','click_num','cart_num'].agg([mean,pct_func(low=0,high=10000).round(2).head()df.groupby('sku')['expose_num','click_num','cart_num'].agg(pct_func(low=0,high=10000)).round(2).head()7、自定义函数传参与内置函数共用
要实现自定义函数传参的同时与内置函数共用,可用如下方式:
定义嵌套函数(闭包)
def pct_func(s,low,high):
score = s.between(low,high).mean()
return score
def agg_func(func,name,low,high):
def wrapper(x):
return func(x,low,high)
wrapper.__name__ = name
return wrapper
df.groupby('sku')['expose_num','click_num','cart_num'].agg([mean,agg_func(pct_func,'pct',low=0,high=10000)]).round(2).head()
谢谢!