网络爬虫—03网络数据解析
文章目录
- 一、正则表达式
-
- 正则表达式匹配规则
- 正则实现步骤
- Pattern和Match对象方法汇总
-
- 1.pattern对象方法
- 2.match对象方法
- 3.search
- 4.findall和finditer方法
- 5.split方法
- 6.sub方法
- 7.匹配中文
- 8.正则常量
- 9.贪婪模式与非贪婪模式
- 基于requests和正则猫眼电影top100定向爬虫
- 二、XPath数据解析库
-
- 基于requests和XPath猫眼电影TOP100定向爬虫
- 基于requests和XPath的TIOBE编程语言排行榜定向爬虫
- 三、BeautifulSoup数据解析库
-
- BS4基本用法
- BS4的节点选择器
- BS4的方法选择器
- BS4的CSS选择器
- 基于requests和BS4的三国演义名著定向爬虫
一、正则表达式
爬虫一共四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式匹配规则
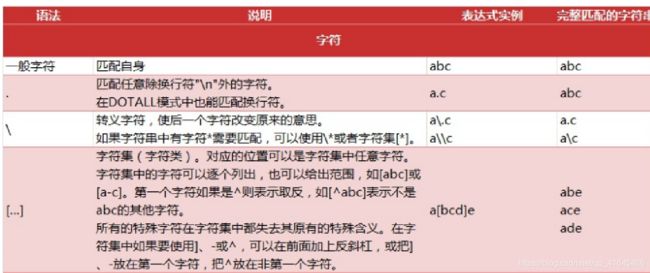



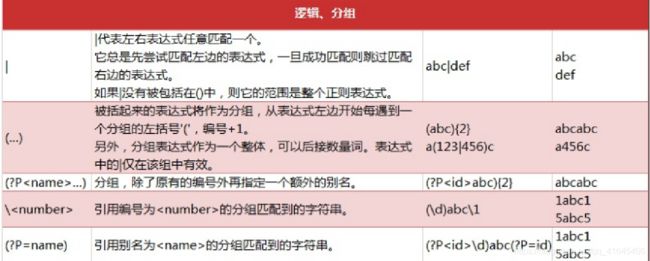
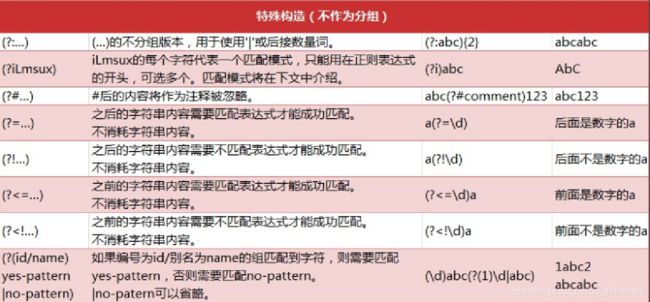
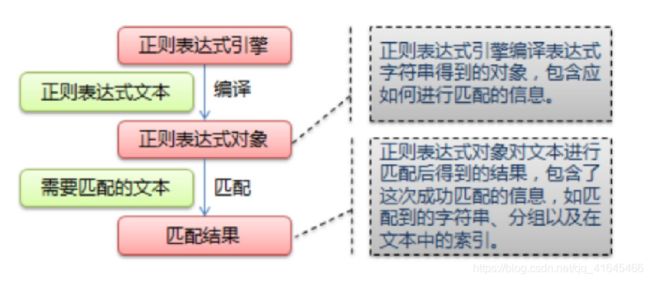
正则实现步骤
- 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象
注意: re对特殊字符进行转义,如果使用原始字符串,只需加一个 r 前缀 - 通过 Pattern 对象对文本进行匹配查找,获得匹配结果,一个 Match 对象。
- 使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
import re
text = """
2020-10-10
2020-11-11
2030/12/12
"""
# 1. 规则, 使用compile函数将字符串编译为一个pattern对象
# pattern = r'\d{4}-\d{1,2}-\d{1,2}' # 1. 无分组 group()
# pattern = r'(\d{4})-(\d{1,2})-(\d{1,2})' # 2. 有分组的 groups()
pattern = r'(?P\d{4})-(?P\d{1,2})-(?P\d{1,2})' # 3. 命名元组 groupdict()
compile_pattern = re.compile(pattern)
# compile_pattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}' )
# 2. 对文本进行匹配查找 search,match,fullmatch, 获得匹配结果,是一个match对象
# findall 返回符合条件的所有字符串
# result = re.findall(pattern, text)
# print(result) # ['2020-10-10', '2020-11-11']
# search 从给定的字符串中寻找一个符合规则的字符串,只返回一个
result = re.search(pattern, text)
print(result)
print(dir(result))
# 3. 使用match对象提供的属性和方法
print(result.group()) # 无分组
print(result.groups()) # 分组
print(result.groupdict()) # 命名元组Pattern和Match对象方法汇总
1.pattern对象方法
正则表达式编译成 Pattern 对象, 可以利用 pattern 的一系列方法对文本进行匹配查找
Pattern 对象的一些常用方法主要有:
| 方法 | 说明 |
|---|---|
| match 方法 | 从起始位置开始查找,一次匹配 |
| search 方法 | 从任何位置开始查找,一次匹配 |
| findall 方法 | 全部匹配,返回列表 |
| finditer 方法 | 全部匹配,返回迭代器 |
| split 方法 | 分割字符串,返回列表 |
| sub 方法 | 替换 |
2.match对象方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回, 而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])string :待匹配的字符串
pos :字符串的起始位置, 默认值是 0
endpos :字符串的终点位置, 默认值是 len (字符串长度)
| 方法 | 说明 |
|---|---|
| group([group1, …]) | 用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0); |
| start([group]) | 用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认 值为 0; |
| end([group]) | 用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数 默认值为 0; |
| span([group]) | 返回 (start(group), end(group))。 |
3.search
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有 匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
4.findall和finditer方法
findall 方法搜索整个字符串,获得所有匹配的结果。使用形式如下:
findall(string[, pos[, endpos]])finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每 一个匹配结果(Match 对象)的迭代器。
5.split方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
maxsplit 指定最大分割次数,不指定将全部分割
split(string[, maxsplit])import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')6.sub方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])repl 可以是字符串也可以是一个函数:
- 1). 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还 可以使用 id 的形式来引用分组,但不能使用编号 0;
- 2). 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符 串中不能再引用分组)。
count 用于指定最多替换次数,不指定时全部替换。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'hello 123, hello 456'
print(p.sub(r'hello word', s)) # 使用'hello word' 替换'hello 123, hello 456'
print(p.sub(r'\2 \1', s)) # \数字:引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print(p.sub(func, s))
print(p.sub(func, s, 1)) # 最多替换1次运行结果:

7.匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00- u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
8.正则常量
re.ASCII
re.IGNORECASE 忽略大小写
re.M 多行
re.S .代表任意字符
import re
# 1. re.ASCII
text = '正则表达式re模块'
# 匹配所有字母数字下划线, 默认匹配中文,不匹配中文时,指定flags=re.A
result = re.findall(pattern=r'\w+', string = text, flags=re.A) # 只匹配ascii
print(result)
# 2. 忽略大小写 re.IGNORECASE
text= 'hello word HEllo python'
result = re.findall(r'he\w+o' , text, re.I)
print(result) # ['hello', 'HEllo']
# 3. re.M 多行
text = 'hello 123 \n 234 453word '
result = re.findall(r'^he.*?', text, re.M)
print(result)
# 4. re.S .代表任意字符
text = 'hello \n word'
result = re.findall(r'^he.*?ld$', text, re.S)
print(result)运行结果:

9.贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
使用贪婪的数量词的正则表达式 ab* ,匹配结果: abbb。
*决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。 - 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
使用非贪婪的数量词的正则表达式 ab*? ,匹配结果: a。
即使前面有 * ,但是 ? 决定了尽可能少匹配 b,所以没有 b。 - Python里数量词默认是贪婪的。
基于requests和正则猫眼电影top100定向爬虫
import json
import re
import time
import requests
from colorama import Fore
from requests import HTTPError
from fake_useragent import UserAgent
def download_page(url, params=None):
""" 根据url地址下载html页面 """
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
'Host':'maoyan.com',
'Cookie':''}
# 请求https协议时报错SSLError 解决:verify = False 不验证证书
requests.packages.urllib3.disable_warnings()
response = requests.get(url, params=params, headers = headers,verify = False)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站失败:%s' %(url, e.reason) )
return None
else:
return response.text
def parse_html(html):
""" 通过正则表达式对html解析,获取电影名称 """
pattern = re.compile(
''
+'.*?(\d+)' # 获取电影排名+'.*?![]() alt="(.*?)"' # 获取电影图片网址和电影标题
+'.*?
alt="(.*?)"' # 获取电影图片网址和电影标题
+'.*?(.*?)
' # 获取电影的主演 主演:黄渤,张译
>
+'.*?(.*?)
'# 获取电影上映时间上映时间:2019-09-30
'.*?',
re.S )
items = re.finditer(pattern, html) # 返回迭代器 findall返回列表
for item in items:
yield {
'index':item.groups()[0],
'image':item.groups()[1],
'title':item.groups()[2],
'star':item.groups()[3].strip().strip('注意:'), #去掉后面的空格
'releosetime':item.groups()[4].strip('上映时间:')
}
def sace_to_json(data,filename):
"""写入json文件"""
# 1. python数据类型如何存储到文件中:json将python数据类型序列化为json字符串
# 2.json中中文不能存储怎么解决: ensure_ascii=False
# 3.存储到文件中的数据改为utf-8
with open(filename, 'ab') as f:
f.write(json.dumps(data,ensure_ascii=False).encode('utf-8'))
print(Fore.GREEN+'[+]保存电影%s的信息成功' %(data['title']))
def get_one_page(page=1):
# url = 'https://maoyan.com/board/' # 采集热映口碑榜,只有一页
# 共十页,url规则:https://maoyan.com/board/4?offset=(page-1)*10
url = 'https://maoyan.com/board/4?offset=%s' %(page-1)*10
html = download_page(url)
items = parse_html(html)
for item in items:
sace_to_json(item,'maoyan.json') # item是字典
if __name__ == '__main__':
for page in range(1,11):
get_one_page(page)
print(Fore.GREEN+'[+]采集第%s页数据' %(page))
#反爬虫策略:速度太快被限速,在数据采集的过程中休眠几秒
time.sleep(1)使用多线程和多进程
def no_use_thread():
for page in range(1,11):
get_one_page(page)
print(Fore.GREEN+'[+]采集第%s页数据' %(page))
#反爬虫策略:速度太快被限速,在数据采集的过程中休眠几秒
time.sleep(1)
def use_multi_thread():
# 使用多线程实现
from threading import Thread
for page in range(1, 11):
# 开启多线程,每一页
thread = Thread(target=get_one_page, args=(page,)) # args是元组
thread.start()
print(Fore.GREEN + '[+]采集第%s页数据' % (page))
def use_thread_pool():
# 使用线程池实现
from concurrent.futures import ThreadPoolExecutor
# 实例化线程池 并指定线程池的线程个数
pool = ThreadPoolExecutor(100)
pool.map(get_one_page, range(1, 11))
print("采集结束")
if __name__ == '__main__':
use_multi_thread()二、XPath数据解析库
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
XPath (XML Path Language) 是一门在 xml文档中查找信息的语言,可用来在 xml /html文档中对元素和属性进行遍历。
常用规则:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取直接子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text的节点 |


from lxml import etree
text = """
标题一
标题二
"""
# 1. etree 把html文档中的字符串解析为Element对象
html = etree.HTML(text)
print(html) #标题一
\n标题二\n
'
# 2.
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)基于requests和XPath猫眼电影TOP100定向爬虫
页面分析:
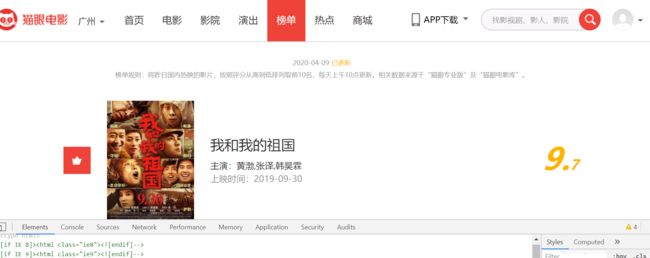
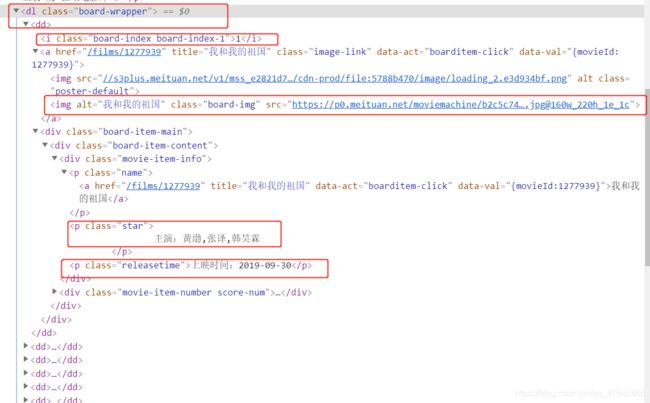
import codecs
import json
import re
import time
import requests
from colorama import Fore
from requests import HTTPError
from fake_useragent import UserAgent
from lxml import etree
def download_page(url, params=None):
""" 根据url地址下载html页面 """
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
'Host':'maoyan.com',
#'Cookie':''
}
# 请求https协议时报错SSLError 解决:verify = False 不验证证书
response = requests.get(url, params=params, headers = headers, verify = False)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站失败:%s' %(url, e.reason) )
return None
else:
return response.text
def parse_html(html):
""" 通过xpath解析,获取电影名称 """
# 1.将传入的html文档内容通过lxml解析器进行解析
html = etree.HTML(html)
# 2.通过Xpath语法获取电影的信息
#//*[@id="app"]/div/div/div/dl/dd[1]
#//dl[@class="board-wrapper"]/dd 从当前节点寻找类名class属性名等于board-wrapper的dl标签,并拿出所有的dd标签
movies = html.xpath('dl[@class="board-wrapper"]/dd')
for movie in movies:
#从当前dd节点寻找i标签里面的文本内容
index = movie.xpath('./i/text()')
# ./从当前标签寻找img标签(class="border-img")红藕去标签的data-src和alt属性
# /不深入寻找 //深入寻找
image = movie.xpath('./img[@class="board-img"]/@data-src')[0]
title = movie.xpath('./img[@class="board-img"]/@alt')[0]
star = movie.xpath('.//p[@class="star"]/text()')[0]
releasetime = movie.xpath('.//p[class="releasetime"]/text()')[0]
yield {
'index':index,
'image':image,
'title':title,
'star': star.strip().strip('注意:'), # strip:去掉后面的
'releosetime': releasetime.strip('上映时间:')
}
def sace_to_json(data,filename):
"""写入json文件"""
# 1. python数据类型如何存储到文件中:json将python数据类型序列化为json字符串
# 2.json中中文不能存储怎么解决: ensure_ascii=False
# 3.存储到文件中的数据改为utf-8
with codecs.open(filename, 'ab','utf-8') as f:
f.write(json.dumps(data,ensure_ascii=False), indent=4)
#print(Fore.GREEN+'[+]保存电影%s的信息成功' %(data['title']))
def get_one_page(page=1):
url = 'https://maoyan.com/board/' # 采集热映口碑榜,只有一页
html = download_page(url)
items = parse_html(html)
for item in items:
print(item)
#sace_to_json(item,'maoyan.json')# item是字典
if __name__ == '__main__':
get_one_page()基于requests和XPath的TIOBE编程语言排行榜定向爬虫
页面分析:

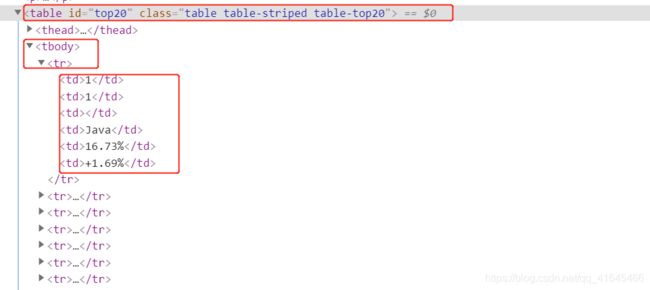
import codecs
import csv
import json
import re
import time
import requests
from colorama import Fore
from requests import HTTPError
from fake_useragent import UserAgent
from lxml import etree
def download_page(url, params=None):
""" 根据url地址下载html页面 """
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
# 请求https协议时报错SSLError 解决:verify = False 不验证证书
response = requests.get(url, params=params, headers = headers, verify = False)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站失败:%s' %(url, e.reason) )
return None
else:
return response.text
def parse_html(html):
# 1. 通过lxml解析页面信息,返回Element对象
html = etree.HTML(html)
# 2.根据xpath 路径寻找语法获取编程语言相关信息
# 获取每一个编程语言的Element对象
#
laguages = html.xpath('//table[@id="top20"]/tbody/tr')
# 依次获取每个语言的去年名次,今年名次,编程语言名称,评级rating,变化率change
for laguage in laguages:
# xpath进行索引时,从1开始
now_rank = laguage.xpath('./td[1]/text()')[0]
last_rank = laguage.xpath('./td[2]/text()')[0]
name = laguage.xpath('./td[4]/text()')[0]
rating = laguage.xpath('./td[5]/text()')[0]
change = laguage.xpath('./td[6]/text()')[0]
yield {
'now_rank':now_rank,
'last_rank':last_rank,
'name':name,
'rating':rating,
'change':change
}
def sace_to_csv(data,filename):
#data是yeid返回的字典对象
#默认csv文件写入会有空行,通过newline=''去掉
with open(filename,'a',encoding='utf-8',newline='') as f:# 追加的方式写入
csv_writer = csv.DictWriter(f,['now_rank','last_rank','name','rating','change'])
csv_writer.writerow(data)
def get_one_page(page=1):
url = 'https://www.tiobe.com/tiobe-index/'
filename = 'tiobe.csv'
html = download_page(url)
items = parse_html(html)
for item in items:
# 存入csv文件中,
sace_to_csv(item,'tiobe.csv')
print(Fore.GREEN + '[+]写入文件%s成功' %(filename))
if __name__ == '__main__':
get_one_page()
运行结果:生成tiobe.csv文件
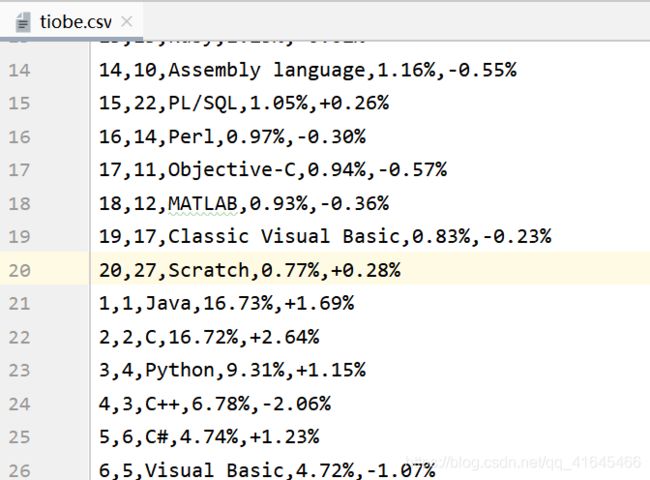
这里涉及到CSV文件的读写操作:

import csv
# # 1. 通过reader方式读取文件内容,每行内容是一个列表
# with open('hello.csv') as f:
# csv_reader = csv.reader(f)
# for row in csv_reader:
# print(row) # 返回的是列表
#2. 通过Dictreader方式读取文件,每行是字典
# with open('hello.csv') as f:
# csv_reader = csv.DictReader(f)
# for row in csv_reader:
# print(row) # OrderedDict([('name', 'zhangsan'), ('age', '10')])
# print('名称:',row['name'])
# print('年龄:',row['age'])
# # 3. 通过writer写入文件,必须传入一个列表
# info = [
# ('zhangsan',10),
# ('lisi',20),
# ]
# with open('writer.csv','w',encoding='utf-8') as f:
# csv_writer = csv.writer(f)
# # 一次写入多行内容
# csv_writer.writerows(info)
# # for循环, 一次写入一行内容
# for row in info:
# csv_writer.writerow(row)
# 4. 通过DictWriter方式写入文件,必须传入一个字典
with open('writer.csv','w',encoding='utf-8') as f:
# 传两个值:文件名称,字典KEY值(表头)
csv_writer = csv.DictWriter(f,['name','password']) # 表头
for row in range(10):
csv_writer.writerow({
'name':'name'+str(row),
'password':'password'+str(row)
})
# for row in data:
# csv_writer.writerow(row)
三、BeautifulSoup数据解析库
Beautiful Soup 4.4.0是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
BS4基本用法
# 1. 从bs4模块中导入BeautifulSoup
from bs4 import BeautifulSoup
html = """
bs4
"""
# 2.实例化BeautifulSoup对象,并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html,'lxml') # 使用'lxml'解析器
result = soup.prettify()
print(result)
运行结果:

BS4的节点选择器
from bs4 import BeautifulSoup
text = """
beautifulsoup >
姓名
年龄
张三
10
小王
12
 """
# 使用lxml进行解析
soup = BeautifulSoup(text, 'lxml')
# 节点选择器
# 1. 元素选择 soup.标签名: 只返回在html里面查询的符合条件的第一个标签的内容
print(soup.title)
print(soup.table) # table里的包括的所有信息都返回回来了
print(soup.img)
print(soup.tr) # 只返回了第一个tr
# 2. 嵌套选择
print(soup.head.title)
print(soup.body.table.tr.td) # 符合条件的第一个
# 3. 属性选择
# (1)获取标签名称:当爬虫过程中标签对象赋值给一个变量传递进函数时,向获取变量对应的标签,用name属性
print(soup.img.name)
movieing = soup.img
print(movieing.name)
# (2)获取标签的属性 :attrs返回标签的所有属性
print(soup.table.attrs) # 返回table标签的所有属性:{'class': ['table'], 'id': 'userinfo'}
print(soup.table.attrs['class']) # 获取class属性对应的值
print(soup.table['class']) # 获取class属性对应的值,最好用这个
# (3)获取文本内容
print(soup.title.string)
print(soup.title.get_text())
# 4. 关联选择
# (1)父节点和祖先节点
first_tr_tags = soup.table.tr
print(first_tr_tags.parent) # 父节点:table
print(first_tr_tags.parents) # 祖先节点
"""
# 使用lxml进行解析
soup = BeautifulSoup(text, 'lxml')
# 节点选择器
# 1. 元素选择 soup.标签名: 只返回在html里面查询的符合条件的第一个标签的内容
print(soup.title)
print(soup.table) # table里的包括的所有信息都返回回来了
print(soup.img)
print(soup.tr) # 只返回了第一个tr
# 2. 嵌套选择
print(soup.head.title)
print(soup.body.table.tr.td) # 符合条件的第一个
# 3. 属性选择
# (1)获取标签名称:当爬虫过程中标签对象赋值给一个变量传递进函数时,向获取变量对应的标签,用name属性
print(soup.img.name)
movieing = soup.img
print(movieing.name)
# (2)获取标签的属性 :attrs返回标签的所有属性
print(soup.table.attrs) # 返回table标签的所有属性:{'class': ['table'], 'id': 'userinfo'}
print(soup.table.attrs['class']) # 获取class属性对应的值
print(soup.table['class']) # 获取class属性对应的值,最好用这个
# (3)获取文本内容
print(soup.title.string)
print(soup.title.get_text())
# 4. 关联选择
# (1)父节点和祖先节点
first_tr_tags = soup.table.tr
print(first_tr_tags.parent) # 父节点:table
print(first_tr_tags.parents) # 祖先节点
BS4的方法选择器
import re
from bs4 import BeautifulSoup
# 方法选择器:find; findall
text = """
beautifulsoup >
姓名
年龄
张三
10
小王
12
"""
soup = BeautifulSoup(text, 'lxml')
# (1)根据标签名进行寻找
print(soup.find_all('title')) # 找到所有,列表
print(soup.find('title')) # 找一个
print(soup.find('title').string) # 获取里面的内容
# (2)根据标签名和属性信息进行寻找
print(soup.find_all('table', attrs={
'class':'table','id':'userinfo'}))
print(soup.find('table', attrs={
'class':'table','id':'userinfo'}))
print(soup.find('table', attrs={
'class':'table','id':'userinfo'},recursive=True)) # 递归查找
# (3)根据标签名和属性信息进行寻找,不用attrs, 直接指定 class_=... id=...
print(soup.find_all('table',id='userinfo'))
print(soup.find_all('table',class_='table'))
# (4) 规则可以和正则表达式进行结合
print(soup.find_all('tr',class_=re.compile('item-\d+')))
print(soup.find_all('tr',class_=re.compile('item-\d+'),limit=2)) # 只获取前两个
# (5)根据标签的文本信息进行查找
# 需求:将td标签中文本信息是一位数字或者两位数字的值拿出
print(soup.find_all('td', text=re.compile(r'\d{1,2}')))
BS4的CSS选择器
from bs4 import BeautifulSoup
text = """
beautifulsoup >
姓名
年龄
张三
10
小王
12
"""
soup = BeautifulSoup(text, 'lxml')
# 使用CSS选择器获取信息
# 需求:获取元素类名等于item-3的元素对象
print(soup.select('.item-3'))
# 需求:获取元素id名等于userinfo的元素对象
print(soup.select('#userinfo'))
print(soup.select('table tr td'))
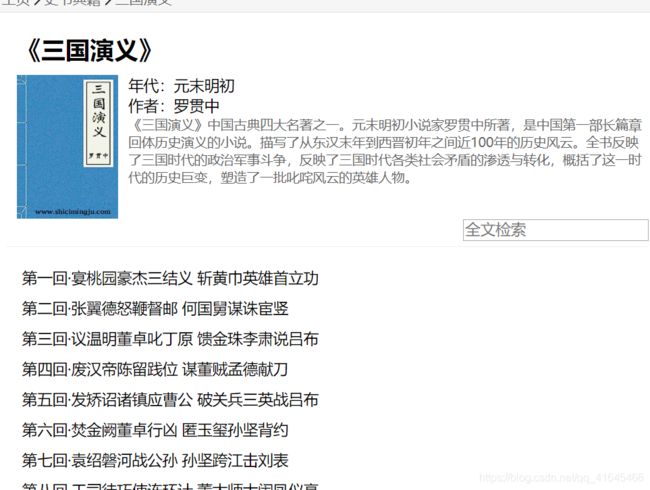
基于requests和BS4的三国演义名著定向爬虫
页面分析:
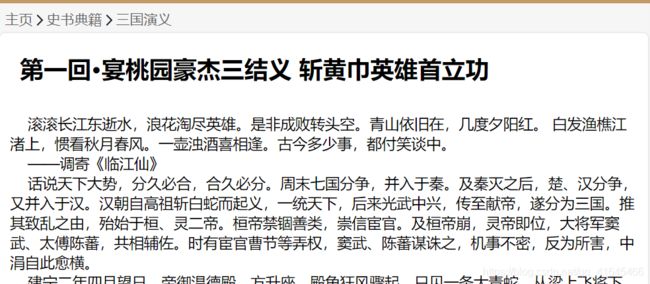
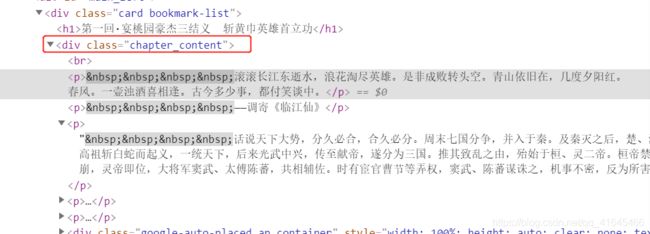
章节的页面:
章节内容页面:
"""
1. 根据网址http://www.shicimingju.com/book/sanguoyanyi.html获取三国演义主页的章节信息.
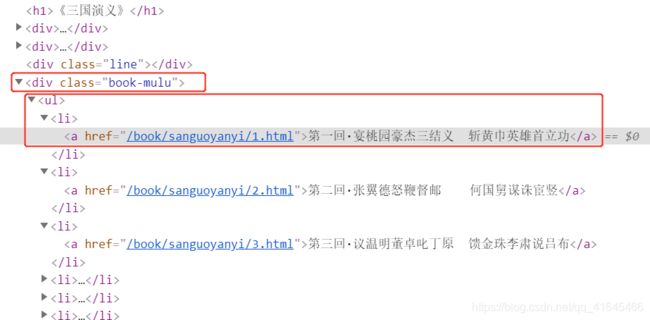
2. 分析章节信息的特点, 提取章节的详情页链接和章节的名称。
- ,li的详情信息如下:
- 第一回·宴桃园豪杰三结义 斩黄巾英雄首立功
3. 根据章节的详情页链接访问章节内容
4. 将章节信息存储到文件中
"""
import os
import re
import requests
from colorama import Fore
from fake_useragent import UserAgent
from requests import HTTPError
from bs4 import BeautifulSoup
def download_page(url, params=None):
try:
ua = UserAgent()
headers = {
'User-Agent':ua.random,
'Host':'www.shicimingju.com'
}
response = requests.get(url, params=params, headers=headers, verify = False)
except HTTPError as e:
print(Fore.RED+ '[-]爬取网站失败:%s' %(url, e.reason))
return None
else:
return response.text
def parse_html(html):
# 选择解析器进行解析
soup = BeautifulSoup(html,'lxml')
# 根据bs4的选择器获取章节的详情页链接和章节的名称
# -
#
你可能感兴趣的:(网络爬虫,网络爬虫,python)