高性能Ceph:Flashcache与Bcache缓存大比拼

新钛云服已为您服务943天


虽然性能较强的SSD价格逐年降低,但与传统的HDD驱动器相比,它们的容量相对更小,同时价格也更昂贵。与之相比,HDD虽然价格低廉,但容量更大,可是却有较高的延迟并且很容易达到性能瓶颈。那我们又该如何实现存储系统的低延迟和高容量。
有一种比较通用的的优化性能一般的存储集群的做法—使用缓存。由于磁盘上的大多数数据在大多数情况下都不被访问,经常被访问的数据只是占其中的一小部分,因此我们可以通过使用容量相对较小,但性能却非常高的SSD作为缓存使整个存储集群获得更高的存储性能。
当前,硬件服务器和操作系统都已经实现了各种缓存方式。Linux在文件系统层上有块设备的页面缓存,Dirent缓存和inode缓存。磁盘内部也有自己的缓存。CPU具有缓存。那么,为什么不为较慢的磁盘增加一个持久性缓存层呢?
在本文中,我们将解释我们所使用的方案,遇到的问题以及如何通过替换块设备缓存软件来解决这些问题。我们将从带有HDD后端的Ceph集群的缓存方案开始讲。
环境
Ceph是现代软件定义的对象存储。它可以以不同的方式使用,包括存储虚拟机磁盘并提供S3 API。以下是我们使用它的场景:
虚拟机的RBD设备。
CephFS用于某些内部应用程序的文件存储,用于替代NFS。
使用网络或者api访问的普通RADOS对象存储。
下面是我们将要在这里讨论的环境信息。
由于历史原因,我们的这个群集的架构并不完美。该集群大概约有10台服务器,每台服务器中都有24个HDD磁盘作为底层OSD。另外,我们有5个cache tier(缓存层)服务器,在本文中我们并不会讨论cache tier(生产环境使用cache tier并不理想,我们后续也尽量避免使用该缓存方案)。
每台包含24个HDD磁盘的服务器都有一个NVMe SSD,该SSD分为48个分区(实际上,它是由2个NVMe组成的RAID-1阵列)。因此,每个OSD都有一个分区用于OSD日志,一个分区用于缓存。
Flashcache
什么是flashcache?它是Facebook最初开发的内核模块,它基于内核的 devicemapper 机制,允许将 ssd 设备映射为机械存储设备的缓存,堆叠成为一个虚拟设备供用户读写,从而在一定程度上兼顾 ssd 的高速与机械存储设备的高容量,更加经济高效地支撑线上业务。它可以在四种不同模式下工作:write-through,write-around, write-back 和 write-only。Write-around 和 write-through缓存在设备移除和重新引导后并不持久。大多数时候,我们需要缓存读写工作负载,因此我们使用了write-back模式。
可以将Flashcache添加到正在使用的设备中。这是它的优点之一。需要做的就是停止服务,创建缓存设备并使用新创建的虚拟闪存设备启动服务。与所有基于设备映射器的设备一样,Flashcache设备在系统中将被命名为dm- [0-9]。
长期以来,我们一直在使用Flashcache作为具磁盘级别的Ceph OSD的缓存层。如文档中所述,它是为随机读取/写入的IO工作模式而开发的。但是,我们可以配置“顺序阈值”,即将要缓存的请求的最大大小(以KB为单位)。所有大于指定大小的请求都将直接通过缓存传递到后端慢速的磁盘设备上。
我们是在不同的应用场景下开始使用它:通过Ceph和基于RADOS的客户端。这也是当前大部分用户所使用的场景。
问题
当我们开始使用flashcache时,问题就开始出现了。第一个问题是flashcache的锁行为。当有一个错误时候,就会导致死锁。在高内存压力下,当flashcache需要释放一些内存时,它必须启动一个新线程来这样做。但是要启动一个新线程,它就需要分配内存,这时候主机无法分配所需要的内存。该错误最终导致的结果就是是主机突然挂起。
我们面临的另一个问题是HDD利用率很高,集群越大,利用率越高。有些磁盘的利用率高达100%,持续了数十秒钟。为了了解为何会这样,我们开始查看配置文件以及相应的调整历史。当时我们正使用Ceph的cache tier,因此很难知道是哪一种制导致这一现象,但是至少它可以刷回对象。
因此,我们知道我们集群有cache-tier的数据刷回,flashcache脏数据清理和Ceph恢复操作。所有这些操作都可能导致高HDD利用率。我们开始跟踪HDD动作,以便更好地了解事情的起因。第一个结果与预期的一样。缓存中有很多恢复操作。
可以理解,由于恢复过程的I/O主要是顺序的,在恢复过程中顺序读取会导致HDD利用率很高,但是当群集处于稳定状态时,我们会遇到相同的问题。然后,借着这次机会,在利用率很高且没有恢复的情况下跟踪块请求。我们使用blktrace进行跟踪,并使用btt和bno_plot脚本来构建3d图形:

此图中有三个同时使用HDD的主线程:
Flashcache 的脏数据块会清除正在磁盘上写入的清理线程(图中的的kworker)。
Ceph OSD文件存储线程,正在读取和异步写入磁盘。
当必须清除OSD日志时,文件存储同步线程将fdatasync()发送到脏数据块。
这是什么意思呢?这意味着有时我们从Ceph OSD守护程序中获得了顺序的工作负载。有时我们进行了flashcache脏块清理操作。当这些操作在同一时间段内发生时,我们面临HDD设备达到瓶颈的情况。
调整Flashcache
Flashcache的缓存结构是一个集合关联哈希。缓存设备被分成若干部分,称为集合。每一组被分成块。后端慢速设备被分成多个部分,每个部分都有一个相关的集合。由于缓存磁盘要小得多,所以每一组都与多个慢速后端设备相关联。
当flashcache尝试在磁盘上存储一些数据时,它必须为其找到一个集合。然后它必须在该集合内的高速缓存上找到可以存储新块的位置。虽然高速缓存集查找速度很快,因为它是使用块编号进行映射的,但是缓存集中的块查找只是对空闲(或干净)空间的线性搜索。
从下面代码中可以看到,我们必须使Flashcache能够更轻松地处理脏数据块。但是这里的问题是脏数据块清理的所有设置都与设置相关。没有可以帮助我们的IO反馈控制机制。
dev.flashcache..fallow_delay = 900
In seconds. Clean dirty blocks that have been "idle" (not read or written) for fallow_delay seconds. Default is 15 minutes. Setting this to 0 disables idle cleaning completely.
dev.flashcache..fallow_clean_speed = 2
The maximum number of "fallow clean" disk writes per set per second. Defaults to 2.
...
(There is little reason to tune these)
dev.flashcache..max_clean_ios_set = 2
Maximum writes that can be issued per set when cleaning blocks.
dev.flashcache..max_clean_ios_total = 4
Maximum writes that can be issued when syncing all blocks.
更改所有这些设置并不能帮助我们在清理脏数据块时减少HDD硬盘上生成的flashcache负载。
我们前面提到的另一个问题是通过缓存的顺序负载很高(最后一个图片上有绿色的X标记)。可以设置一个更高的顺序阈值,这至少可以帮助我们缓存更多的顺序写入并降低HDD硬盘的利用率。
不幸的是,由于flashcache的架构,它没有起到任何作用。如果缓存集有很多写入操作,则会被脏数据块填满。如果没有地方缓存一个新的数据块,例如,如果当前集合中的所有块都是脏的,则将该块放置在HDD设备上。此行为称为conflict miss 或 collision miss ,也就是缓存冲突为命中,这也是集合关联缓存的已知问题。
Flashcache配置问题
Flashcache配置管理很难。实际上,它使用sysctl进行配置。例如,如果我们将md2p9作为ata-HGST_HUS726040ALE614_N8G8TN1T-part2的缓存设备,则所有Flashcache设备选项如下所示:
dev.flashcache.md2p9+ata-HGST_HUS726040ALE614_N8G8TN1T-part2.cache_all = 1
dev.flashcache.md2p9+ata-HGST_HUS726040ALE614_N8G8TN1T-part2.clean_on_read_miss = 0
dev.flashcache.md2p9+ata-HGST_HUS726040ALE614_N8G8TN1T-part2.clean_on_write_miss = 0
dev.flashcache.md2p9+ata-HGST_HUS726040ALE614_N8G8TN1T-part2.dirty_thresh_pct = 20
…
假设您要更改缓存或缓存的设备,然后要创建新的闪存设备,则必须更改sysctl.d配置文件。您需要删除以前使用的配置,并为新的闪存设备添加新选项。因此,使用自定义脚本删除旧文件并创建一个新脚本会更容易,该脚本可以从/proc/flashcache目录获取设备名称。
然后,为了减少人为因素,应该有一个udev规则,它调用«dm»设备«add»或«change»事件上的脚本。如果要更改某些主机或主机上某些设备的某些设置(这种情况很少见,但依然有可能),则必须使用配置管理系统自定义脚本。所有这些操作都变得复杂和不直观。
Flashcache的另一个缺点是它不在内核主线中。当内核API更改时,需要重新编译添加:
#if LINUX_VERSION_CODE < KERNEL_VERSION (your version here)
在源代码中,添加一些代码并重新生成模块。所有这些问题迫使我们寻找另一种解决办法。
Bcache
Bcache与flashcache不同。它最初由Kent Overstreet开发,现在由Coly Li积极维护。它被合并到内核主线中,因此我们不必担心,可以使用新的内核对其进行测试。
Bcache不使用设备映射器,它是一个单独的虚拟设备。与flashcache一样,它由三个设备组成:
后端设备:慢速缓存的设备,通常容量大,但性能相对一般;
缓存设备:高速NVMe;
bcache设备:最终为应用程序提供使用的虚拟设备盘。
它支持write-back,write-through,write-around和none的缓存模式。正如我们前面提到的,我们一直在寻找比较好的write-back。更改缓存模式很容易,我们只需要向sysfs文件中写入一个新的模式名称即可。这些sysfs是在创建新的bcache设备时创建的。
echo writeback > /sys/class/block/bcache0/bcache/cache_mode
它看起来比通过动态更改的sysctl配置文件配置每个设备要简单得多。它更容易,因为它可以使用udev规则来更改设置,就像标准块设备一样!
可以使用多个支持设备创建一个bcache设备,但是我们不使用此功能。相反,我们为每个缓存单独使用NVMe驱分区。
Bcache如何运作
Bcache不使用标准的缓存分配策略,例如直接映射或集合关联。相反,它在b+tree上运行。在此树中,它存储指向已分配数据块的键和指针。如果有一些要写入的数据,它将准备密钥并为该数据分配空间。
写入数据后,将密钥插入到btree中。当有读取请求要提供时,bcache在btree中查找密钥。如果没有这样的键,则仅返回零;如果找到了键,则通过指针收集数据。该请求处理方法使得冲突失效事件成为不可能。可以在这里((https://bcache.evilpiepirate.org/BcacheGuide/))查看文档。它并不全面,但是它解释了bcache如何运行的基本原理。
前面我们提到过,我们要控制回写速率的速度。bcache使这成为可能。它使用PI控制器计算回写率。
回写操作的速率取决于当前脏数据块的数量和阈值之间的差异。越脏的块超过阈值,回写率就越高。它还取决于脏数据超过阈值的时间。超过阈值的时间越长,回写率就越高。您可以在Wikipedia(https://en.wikipedia.org/wiki/PID_controller)上找到有关PID控制器如何工作的基本信息。
使用新内核,即使脏块的数量尚未达到阈值,我们也可以设置最小回写率,即最小率。还有另外两个设置:writeback_rate_p_term_inverse和writeback_rate_i_term_inverse。这两个设置都会影响PI控制器对写入负载的响应速度。
这些功能使bcache成为一个非常灵活的解决方案,因此我们决定对其进行一些测试,然后尝试在生产环境中运行它。
Bcache测试和配置
在本节中,我们将显示一些配置选项,一些测试结果和fdatasync()行为。让我们从最基本的配置开始。
我们已经说过,我们需要bcache来缓存写请求和读请求。因此,第一件事就是设置回写模式。然后关闭sequence_cutoff。此选项告诉bcache传递大小大于指定值的请求。值为0表示关闭此机制。
~$ echo writeback > /sys/class/block/bcache6/bcache/cache_mode
~$ echo 0 > /sys/class/block/bcache6/bcache/sequential_cutoff
bcache/cache目录中也有拥塞阈值,但是我们不更改这些阈值,因为它们对我们来说足够高。
我们使用fio进行测试:
[test]
ioengine=libaio
rw=randwrite
bs=4k
filename=/dev/bcache6
direct=1
fdatasync=10
write_iops_log=default
log_avg_msec=1000
filesize=8G
如您所见,我们或多或少使用了默认选项。选项direct = 1阻止使用页面缓存,并使libaio引擎正常工作。每执行10次写入操作后,将调用fdatasync系统调用以刷新设备的缓存。还有一些选项要求Fio将IOPS结果输出到文件中。当然,这种工作负载看起来像是一个极端情况,因为在现实生活中,我们一直都没有这种直接的单线程随机写入负载。但这将向我们展示有关bcache行为的一些信息。
我们在一开始就对两种类型的缓存状态进行了一些测试:清理缓存;缓存在先前的测试后将其回写率降至最低。
我们清理了缓存,测试之前的统计信息如下:
rate: 4.0k/sec
dirty: 0.0k
target: 5.3G
proportional: -136.2M
integral: -64.5k
change: 0.0k/sec
next io: -4035946ms
这些统计资料来自cat /sys/class/block/bcache6/bcache/writeback_rate_debug,我们将在本节中展示它们。我们使用默认的bcache设置开始测试。让我们看一下结果:
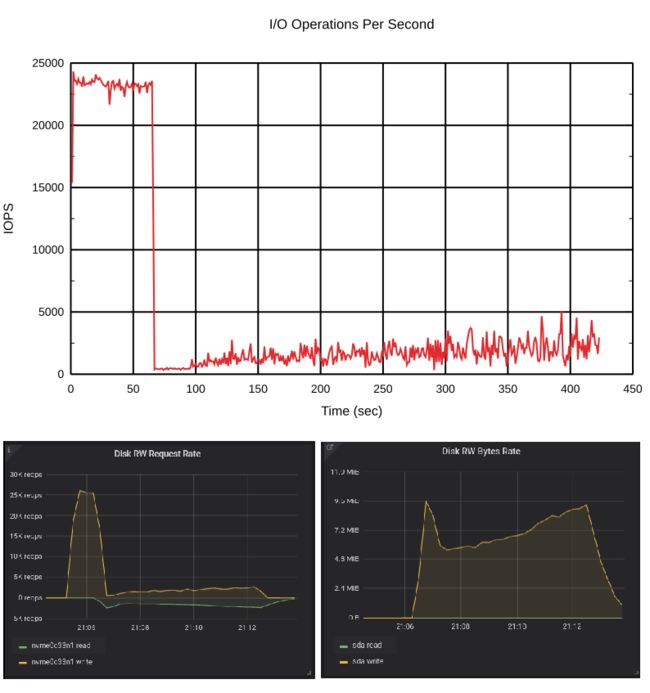
这很有趣。一开始,缓存是空的,每秒大约有25K写入操作。但是,当脏数据达到其阈值时,它会降低写入请求的速度。那是怎么发生的?答案是fdatasync()。
所有刷新请求都会发送到后端设备。当脏数据块的数量大于阈值时,bcache会增加回写率并将数据写入后端设备。当后端设备加载写操作时,它开始对刷新请求做出更慢的响应。您可以运行相同的测试,然后使用iostat进行检查。除非您使用内核> = 5.5,否则它将显示有很多对后端设备的写入请求(即刷新),除非内核对刷新请求有特定的计数器。
回写速率快速增加,并且后端设备负担也很重。
现在让我们再次开始此测试,但是现在使用不同的测试条件:
rate: 4.0k/sec
dirty: 5.1G
target: 5.3G
proportional: -6.4M
integral: 6.3M
change: -26.0k/sec
next io: 552ms
脏数据块的数量已接近阈值,因此我们预计它将快速到达阈值,bcache将更快地作出反应,并且减慢速度不会那么大。

现在让我们更改一些对回写行为有影响的配置。前面我们提到了writeback_rate_p_term_inverse和writeback_rate_i_term_inverse选项。您可能已经猜到过,这些选项是成比例的反比例项和成逆的积分项。
~$ echo 180 > /sys/class/block/bcache6/bcache/writeback_rate_p_term_inverse
默认的«p»是40,因此此更改将显着影响回写行为。使其反应速度降低。我们使用干净的缓存再次开始测试。
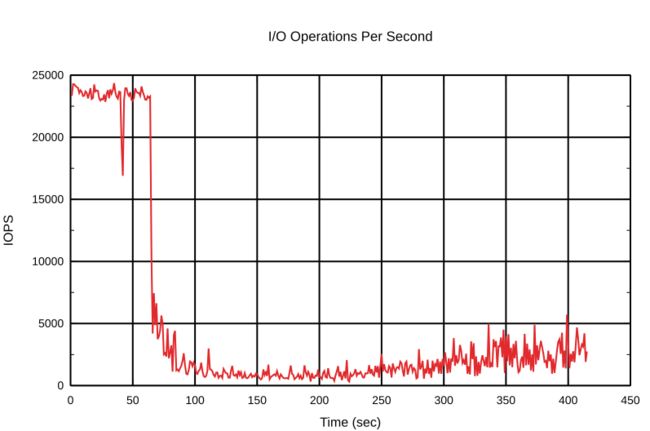
将速度降至最低后的回写状态:
rate: 4.0k/sec
dirty: 4.7G
target: 5.3G
proportional: -3.1M
integral: -39.5k
change: 0.0k/sec
next io: 357ms
并再次测试。

显而易见,bcache的回写率更加柔和。顺便说一句,它在两个方向上都很温和—增大和减小。看看使用默认设置的第一次测试之后和更改了«p»项的第一次测试之后的脏数据。在下一个达到最低速率后,脏数据块减少了。较高的逆«p»项花费了更多时间才能将回写率降低到默认值。
让我们也使用积分术语。在当前情况下,积分项不应发挥如此大的作用。初始条件与之前的测试相同。
echo 30000 > /sys/class/block/bcache6/bcache/writeback_rate_i_term_inverse
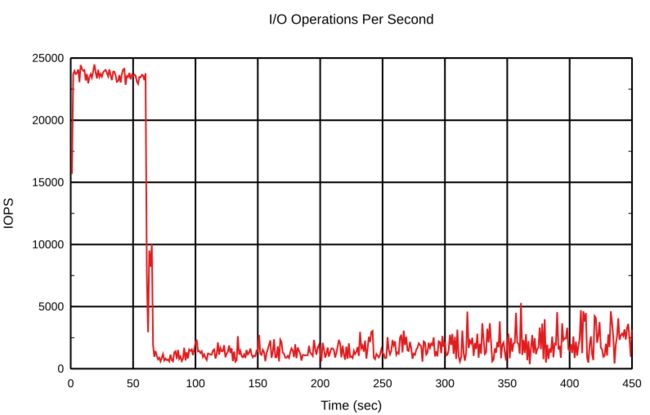
将速度降至最低后的回写状态:
rate: 4.0k/sec
dirty: 5.2G
target: 5.3G
proportional: -2.3M
integral: -0.5k
change: 0.0k/sec
next io: 738ms
第二个开始:
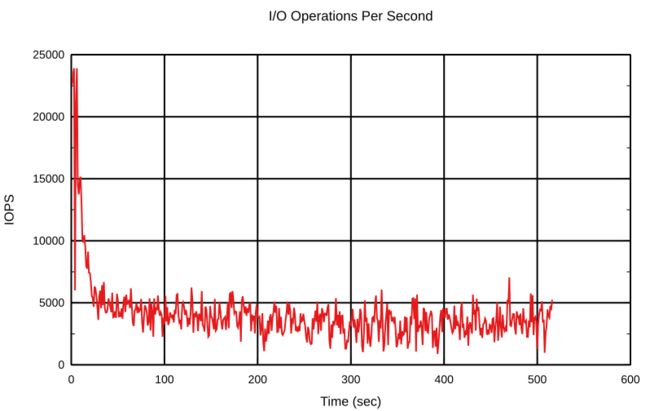
可以看出,积分项在这里没有起到很大的作用。实际上,积分项会影响PI控制器的速度,并有助于减少来自输入的干扰,例如bcache设备上的突发写入。配合调整PI控制器非常有趣,请根据实际工作量进行尝试。
好消息是可以缓存所有写请求,无论是顺序的还是随机的。其回写率取决于加载和缓存是否已满。这正是我们想要的。
结论
我们决定在生产中使用bcache,这并没有使我们失望。write-back模式下的Bcache比FlashCache更好。我们还可以使用比flashcache允许使用的相对更小的缓存设备。
我们已经开始在新的集群中使用bcache,并且在性能上,稳定性上得到了大量的改进。我们从未见过bcache的硬盘利用率如此之高。当整个系统处于高负载时,由于HDD硬盘的瓶颈,使用bcache的主机要比使用flashcache的主机显示出更低的延迟。
参考:
https://wiki.archlinux.org/index.php/bcache
https://www.kernel.org/doc/Documentation/bcache.txt
https://en.wikipedia.org/wiki/Bcache
*本文译自https://blog.selectel.com/bcache-vs-flashcache/,如有侵权请联系删除
*本文部分图片来源于网络,如有侵权请联系删除
了解新钛云服
当IPFS遇见云服务|新钛云服与冰河分布式实验室达成战略协议
新钛云服正式获批工信部ISP/IDC(含互联网资源协作)牌照
深耕专业,矗立鳌头,新钛云服获千万Pre-A轮融资
新钛云服,打造最专业的Cloud MSP+,做企业业务和云之间的桥梁
新钛云服一周年,完成两轮融资,服务五十多家客户
上海某仓储物流电子商务公司混合云解决方案
往期技术干货
低代码开发,全民开发,淘汰职业程序员!
国内主流公有云VPC使用对比及总结
万字长文:云架构设计原则|附PDF下载
刚刚,OpenStack 第 19 个版本来了,附28项特性详细解读!
Ceph OSD故障排除|万字经验总结
七个用于Docker和Kubernetes防护的安全工具
运维人的终身成长,从清单管理开始|万字长文!
OpenStack与ZStack深度对比:架构、部署、计算存储与网络、运维监控等
什么是云原生?
IT混合云战略:是什么、为什么,如何构建?
