深度学习图像语义分割网络总结:U-Net与V-Net的Pytorch实现
图像语义分割网络系列博文索引
| FCN与SegNet | U-Net与V-Net | DeepLab系列 | DenseNet、PSPNet、与DenseASPP | Mask R-CNN |
|---|
(后四个在计划中,敬请期待)
图像语义网络分割之U-Net与V-Net
- 图像语义分割网络系列博文索引
- U-Net
-
- U-Net主要贡献
- U-Net网络结构
- Pytorch框架下U-Net实现
- V-Net
-
- V-Net主要贡献
- V-Net网络结构
- Pytorch框架下V-Net实现
U-Net
U-Net是医学图像处理领域最常用的一种网络结构,很多医学图像处理的网络结构都由U-Net改进而来。U-Net可以被看作是基于FCN和SegNet的一种改进方法,采用了FCN的全卷积、反卷积上采样、越级连接的方法,采用了SegNet的Encoder-Decoder结构。原文链接:U-Net: Convolutional Networks for Biomedical Image Segmentation
为了应对小样本学习问题,U-Net提出的网络结构和训练策略使用了充分利用了数据增强方法尽可能提高了对样本和标注的利用率。该体系结构由捕获上下文的跃迁路径和支持精确定位的对称展开路径组成。实验表明,该网络可以从很少的图像中进行端到端训练,并且性能优于先验最佳方法。此外,网络速度很快,在最新的GPU上,512x512图像的分割时间不到一秒。
U-Net主要贡献
- 与FCN不同的是U-net越级层融合方式采用的是concat方式,是对其通道数进行拼接,使特征图变厚,FCN采取的是直接加和的方式。此外U-Net的越级层融合次数增加,FCN只在最后一层进行了融合,Unet有4次融合,实现了多尺度的特征融合,充分的利用了上下文(context)信息,一定解决了感受野大小与分割精度之间的矛盾。
- 提出了overlap策略,该策略能够无缝分割任意大的图像。为了预测图像边界区域的像素,通过镜像输入图像来外推缺失的上下文。该策略使得网络在应对普遍像素大小比较大的医学图像具有了优势,否则分辨率将受到GPU内存的限制。
- 为了应对训练样本少的问题,U-Net采用了随机的弹性形变进行数据增强。
- Unet的优化方法为带动量项的SGD,能量函数为加权的交叉熵形式,离边界越近的像素点权重越大,使得网络对边界像素有更好的训练效果。
U-Net网络结构
其网络结构图如下所示,每一个蓝色方框对应一个多通道的特征图,通道数标注在框的上方。蓝色箭头代表3x3卷积和ReLu激励,灰色箭头代表复制和裁剪,红色剪头代表2x2最大池化,绿色剪头代表2x2的反卷积上采样,青色箭头为1x1卷积。
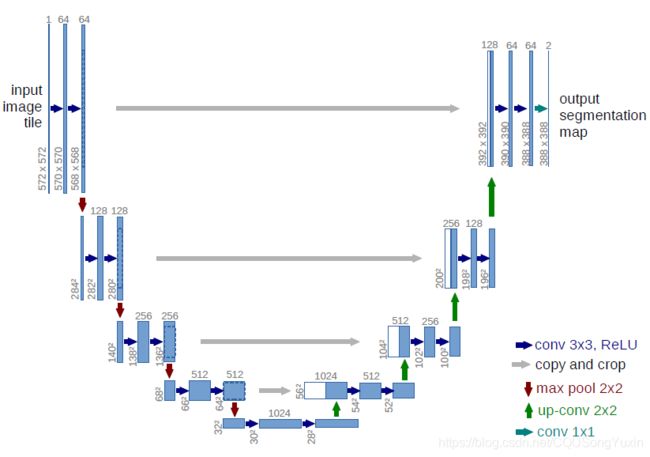
Unet由一条收缩路径(左侧)和一条扩张路径(右侧)组成。收缩路径
和卷积网络的典型结构一致。它由两个3x3卷积(未填充卷积)的重复应用
组成,在每个卷积后跟ReLU激励和一个2x2最大池化操作,步长为2,以实
现下采样。在每个下采样步骤中,将特征通道的数量增加一倍。扩展路径中的每个步骤都包括对特征图进行上采样,然后是将特征通道数量减半的2x2卷积(向上卷积),与来自收缩路径的相应裁剪的特征图的串联以及两个3x3卷积,后跟一个ReLU。由于每次卷积中都会丢失边界像素,因此有必要进行裁剪。在最后一层,使用1x1卷积将每个64分量特征向量映射
到所需的类数。网络总共有23个卷积层。
Pytorch框架下U-Net实现
这里使用的代码是在Github中guanfuchen/semseg原代码的基础上做了一些顺序上的调整及更多的标注帮助理解。
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision import models
class unetDown(nn.Module):
def __init__(self, in_channels, out_channels):
super(unetDown, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True),
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
class unetUp(nn.Module):
def __init__(self, in_channels, out_channels):
super(unetUp, self).__init__()
self.upConv = nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size=2, stride=2)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0),
nn.ReLU(inplace=True),
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0),
nn.ReLU(inplace=True),
)
def forward(self, x_cur, x_prev):
x = self.upConv(x_cur)
x = torch.cat([F.upsample_bilinear(x_prev, size=x.size()[2:]), x], 1)
x = self.conv1(x)
x = self.conv2(x)
return x
def cross_entropy2d(input, target, weight=None, size_average=True):
n, c, h, w = input.size()
nt, ht, wt = target.size()
# Handle inconsistent size between input and target
if h > ht and w > wt: # upsample labels
target = target.unsequeeze(1)
target = F.upsample(target, size=(h, w), mode="nearest")
target = target.sequeeze(1)
elif h < ht and w < wt: # upsample images
input = F.upsample(input, size=(ht, wt), mode="bilinear")
elif h != ht and w != wt:
raise Exception("Only support upsampling")
input = input.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
target = target.view(-1)
print('target',target.view(-1).shape)
loss = F.cross_entropy(input, target, weight=weight, size_average=size_average, ignore_index=250)
return loss
class unet(nn.Module):
def __init__(self, n_classes=21, pretrained=False):
super(unet, self).__init__()
self.down1 = unetDown(in_channels=3, out_channels=64)
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.down2 = unetDown(in_channels=64, out_channels=128)
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.down3 = unetDown(in_channels=128, out_channels=256)
self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.down4 = unetDown(in_channels=256, out_channels=512)
self.maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.center = unetDown(in_channels=512, out_channels=1024)
self.up4 = unetUp(in_channels=1024, out_channels=512)
self.up3 = unetUp(in_channels=512, out_channels=256)
self.up2 = unetUp(in_channels=256, out_channels=128)
self.up1 = unetUp(in_channels=128, out_channels=64)
self.classifier = nn.Conv2d(in_channels=64, out_channels=n_classes, kernel_size=1)
def forward(self, x):
out_size = x.size()[2:]
down1_x = self.down1(x)
maxpool1_x = self.maxpool1(down1_x)
# print('maxpool1_x.data.size():', maxpool1_x.data.size())
down2_x = self.down2(maxpool1_x)
maxpool2_x = self.maxpool2(down2_x)
# print('maxpool2_x.data.size():', maxpool2_x.data.size())
down3_x = self.down3(maxpool2_x)
maxpool3_x = self.maxpool3(down3_x)
# print('maxpool3_x.data.size():', maxpool3_x.data.size())
down4_x = self.down4(maxpool3_x)
maxpool4_x = self.maxpool1(down4_x)
# print('maxpool4_x.data.size():', maxpool4_x.data.size())
center_x = self.center(maxpool4_x)
# print('center_x.data.size():', center_x.data.size())
up4_x = self.up4(center_x, down4_x)
# print('up4_x.data.size():', up4_x.data.size())
up3_x = self.up3(up4_x, down3_x)
# print('up3_x.data.size():', up3_x.data.size())
up2_x = self.up2(up3_x, down2_x)
# print('up2_x.data.size():', up2_x.data.size())
up1_x = self.up1(up2_x, down1_x)
# print('up1_x.data.size():', up1_x.data.size())
x = self.classifier(up1_x)
# 最后将模型上采样到原始分辨率
x = F.upsample_bilinear(x, out_size)
return x
if __name__ == '__main__':
n_classes = 21
image_width = 480
image_height = 360
model = unet(n_classes=n_classes, pretrained=False)
# model.init_vgg16()
x = Variable(torch.randn(1, 3, image_height, image_width))
y = Variable(torch.LongTensor(np.ones((1, image_height, image_width), dtype=np.int)))
# print(x.shape)
# ---------------------------unet模型运行时间-----------------------
start = time.time()
pred = model(x)
end = time.time()
print(end-start)
print(pred.data.size())
loss = cross_entropy2d(pred, y)
print(loss)
V-Net
V-Net是基于U-Net从2D到3D的改进,提出的出发点是因为很多临床的医学影像数据为3D数据(3D volumes)。原文链接:V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image
Segmentation
尽管CNN很流行,但大多数方法只能处理二维图像,而在临床实践中使用的大多数医疗数据是由三维体积组成的。在这项工作中,我们提出了一种方法基于3D体积、全卷积、神经网络的三维图像分割。我们的网络在描述前列腺的MRI体积上进行端到端的训练,并学习一次性预测整个3D图像的分割。
V-Net主要贡献
- 提出了一个3D卷积神经网络框架,可以在3D医学图像数据上直接实现端到端的分割。
- 针对医学图像基于重叠度系数(Dice coeffcient)引入了新的目标函数,以此来解决体素中背景和前景不均衡的问题。
- 引入残差连接,增进网络的收敛性。
- 为了解决训练可用的标注卷数量有限的问题,应用随机非线性变换和直方图匹配来扩充数据。
V-Net网络结构
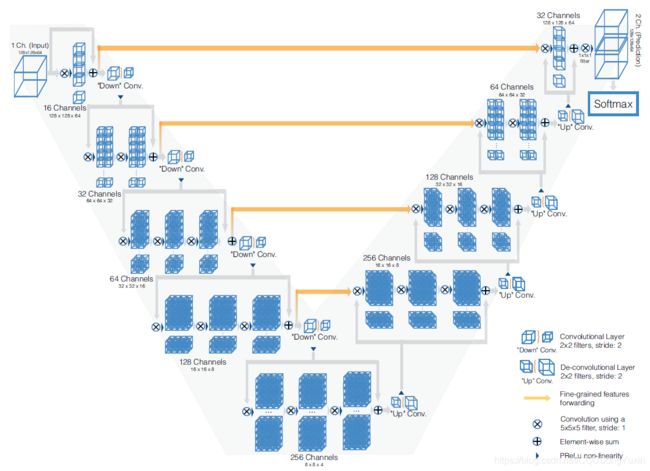
网络结构上与U-Net相似,都是编码-解码结构,左侧的网络不断降低图像的分辨率,提取特征。右侧的网络对图像进行,解码将图像恢复至原来的大小。
左侧网络由多个步骤组成,作者将每一个步骤视为在学习一个残差函数。每一步中通过多次的线性卷积和非线性激活,再加上每一步的最后一层卷积结果跃迁到右侧的输出端,以这样的过程学习一个残差函数。在卷积的过程中使用了跨步(stride)的技巧,这样做的结果是降低图像的大小,增大感受野,一定程度上替代了池化操作。
Pytorch框架下V-Net实现
这里使用的代码是在Github中mattmacy/vnet.pytorch原代码的基础上做了一些注释帮助理解。
import torch
import torch.nn as nn
import torch.nn.functional as F
def passthrough(x, **kwargs):
return x
def ELUCons(elu, nchan): #elu为标记符,使用何种激活函数
if elu:
return nn.ELU(inplace=True)
else:
return nn.PReLU(nchan)
class ContBatchNorm3d(nn.modules.batchnorm._BatchNorm):
def _check_input_dim(self, input): #确认张量维度
if input.dim() != 5:
raise ValueError('expected 5D input (got {}D input)'
.format(input.dim()))
super(ContBatchNorm3d, self)._check_input_dim(input)
def forward(self, input):
self._check_input_dim(input) #维度无误后进行正则化
return F.batch_norm(
input, self.running_mean, self.running_var, self.weight, self.bias,
True, self.momentum, self.eps)
class LUConv(nn.Module): #进行3D卷积,3D卷积后为正则化,最后进行激活 nchan为通道数
def __init__(self, nchan, elu):
super(LUConv, self).__init__()
self.relu1 = ELUCons(elu, nchan)
self.conv1 = nn.Conv3d(nchan, nchan, kernel_size=5, padding=2)
self.bn1 = ContBatchNorm3d(nchan)
def forward(self, x):
out = self.relu1(self.bn1(self.conv1(x)))
return out
def _make_nConv(nchan, depth, elu): #根据depth进行多次卷积
layers = []
for _ in range(depth):
layers.append(LUConv(nchan, elu))
return nn.Sequential(*layers) #列表前面加星号作用是将列表解开成多个独立的参数,传入函数
class InputTransition(nn.Module):
def __init__(self, outChans, elu):
super(InputTransition, self).__init__()
self.conv1 = nn.Conv3d(1, 16, kernel_size=5, padding=2)
self.bn1 = ContBatchNorm3d(16)
self.relu1 = ELUCons(elu, 16)
def forward(self, x):
# do we want a PRELU here as well?
out = self.bn1(self.conv1(x))
# split input in to 16 channels
x16 = torch.cat((x, x, x, x, x, x, x, x, #把输入重复16次,变换为16通道
x, x, x, x, x, x, x, x), 0)
out = self.relu1(torch.add(out, x16))
return out
class DownTransition(nn.Module):
def __init__(self, inChans, nConvs, elu, dropout=False): #dropout为标记符 是否进行Dropout操作 默认为不进行dropout nConvs为卷积重复次数
super(DownTransition, self).__init__()
outChans = 2*inChans
self.down_conv = nn.Conv3d(inChans, outChans, kernel_size=2, stride=2)
self.bn1 = ContBatchNorm3d(outChans)
self.do1 = passthrough
self.relu1 = ELUCons(elu, outChans)
self.relu2 = ELUCons(elu, outChans)
if dropout:
self.do1 = nn.Dropout3d()
self.ops = _make_nConv(outChans, nConvs, elu)
def forward(self, x):
down = self.relu1(self.bn1(self.down_conv(x)))
out = self.do1(down)
out = self.ops(out)
out = self.relu2(torch.add(out, down))
return out
class UpTransition(nn.Module):
def __init__(self, inChans, outChans, nConvs, elu, dropout=False):
super(UpTransition, self).__init__()
self.up_conv = nn.ConvTranspose3d(inChans, outChans // 2, kernel_size=2, stride=2) #//取整除,所得商向下取整
self.bn1 = ContBatchNorm3d(outChans // 2)
self.do1 = passthrough
self.do2 = nn.Dropout3d()
self.relu1 = ELUCons(elu, outChans // 2)
self.relu2 = ELUCons(elu, outChans)
if dropout:
self.do1 = nn.Dropout3d()
self.ops = _make_nConv(outChans, nConvs, elu)
def forward(self, x, skipx):
out = self.do1(x)
skipxdo = self.do2(skipx)
out = self.relu1(self.bn1(self.up_conv(out)))
xcat = torch.cat((out, skipxdo), 1)
out = self.ops(xcat)
out = self.relu2(torch.add(out, xcat))
return out
class OutputTransition(nn.Module):
def __init__(self, inChans, elu, nll):
super(OutputTransition, self).__init__()
self.conv1 = nn.Conv3d(inChans, 2, kernel_size=5, padding=2)
self.bn1 = ContBatchNorm3d(2)
self.conv2 = nn.Conv3d(2, 2, kernel_size=1)
self.relu1 = ELUCons(elu, 2)
if nll:
self.softmax = F.log_softmax
else:
self.softmax = F.softmax
def forward(self, x):
# convolve 32 down to 2 channels
out = self.relu1(self.bn1(self.conv1(x)))
out = self.conv2(out)
# make channels the last axis
out = out.permute(0, 2, 3, 4, 1).contiguous()
# flatten
out = out.view(out.numel() // 2, 2)
out = self.softmax(out)
# treat channel 0 as the predicted output
return out
class VNet(nn.Module):
# the number of convolutions in each layer corresponds
# to what is in the actual prototxt, not the intent
def __init__(self, elu=True, nll=False):
super(VNet, self).__init__()
self.in_tr = InputTransition(16, elu)
self.down_tr32 = DownTransition(16, 1, elu)
self.down_tr64 = DownTransition(32, 2, elu)
self.down_tr128 = DownTransition(64, 3, elu, dropout=True)
self.down_tr256 = DownTransition(128, 2, elu, dropout=True)
self.up_tr256 = UpTransition(256, 256, 2, elu, dropout=True)
self.up_tr128 = UpTransition(256, 128, 2, elu, dropout=True)
self.up_tr64 = UpTransition(128, 64, 1, elu)
self.up_tr32 = UpTransition(64, 32, 1, elu)
self.out_tr = OutputTransition(32, elu, nll)
def forward(self, x):
out16 = self.in_tr(x)
out32 = self.down_tr32(out16)
out64 = self.down_tr64(out32)
out128 = self.down_tr128(out64)
out256 = self.down_tr256(out128)
out = self.up_tr256(out256, out128)
out = self.up_tr128(out, out64)
out = self.up_tr64(out, out32)
out = self.up_tr32(out, out16)
out = self.out_tr(out)
return out