你知道学校里的MySQL与社会中的MySQL有啥区别吗?(详解一)
简介:以上文章讲述的是【2020总结与2021展望,挑战阿里面试】接下来我总结一下【接私活用到的数据库进阶版知识与面试知识】。觉得我还可以的可以加群一起督促学习探讨技术。QQ群:1076570504 个人学习资料库http://www.aolanghs.com/ 微信公众号搜索【欢少的成长之路】
前言
简介
本文经验都是我看书学习的总结的一些经验,面试常问的知识点,所以请关注后再继续观看学习!下面已经给出了书的目录!今后将按目录的顺序继续更新学习心得!
文章最后我会写一些面试的技术思路,我知道关于面试一直都是热门话题,有非常多的人写甚至抄袭,不过我保证我都是原创,我相信聪明的小伙伴应该都发现了文章有一些词的表述都用到了江苏连云港的方言。今后我将持续努力,钻研技术的同时将自己的收获通过写博客文章分享给你们。
个人介绍
我在实习的公司主要负责是做Net C# 语言的。工作应用场景主要是工业控制。平时的私活主要是用Java开发的Web网站,C#开发的PC桌面应用软件,微信小程序,Anroid移动端开发,IOS(团队内有专人负责)!
目标
希望通过这些MySQL的内部原理的知识可以帮助大家培养发现新问题的洞察力,能学习和实践的结合设计出维护基于MySQL的系统。
目录
第一章:数据库基础知识(正在更新)
第二章:基准测试
第三章:服务器性能刨析
第四章:Schema与数据库类型优化
第五章:创建高性能的索引
第六章:查询性能优化
第七章:MySQL高级特性
第八章:优化服务器设置
第九章:操作系统和硬件优化
第十章:复制底层实现
第十一章:可扩展的MySQL
第十二章:高可用性
第十三章:云端的MySQL
第十四章:应用层优化
第十五章:备份与恢复
第十六章:MySQL用户工具
正文
MySQL简单的运行流程
特性
MySQL最与众不同的就是他的特性【存储引擎架构】。这种架构的设计将查询处理,其他系统任务和数据的存储/提取相分离。这样做的好处是可以在使用时根据性能,特性以及其他需求选择相应的数据存储方式。
连接的实现分析
每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个线程中单独执行,该线程只能轮流在某个CPU核心或者CPU中执行。服务器会负责缓存缓存线程,因此不需要为每一个新建的连接创建或者销毁线程。
当客户端发送连接之后,服务器会对其进行认证。基于用户名,主机信息,密码。如果使用了SSL方式连接还可以使用X.509证书认证。认证成功之后服务器会验证你的查询权限等。
SQL语句分析
举一个Select语句的例子:在解析查询之前
- 服务器会先检查查询缓存
- 如果能够在其中找到对应的查询,服务器就不必再执行查询解析,优化和执行的整个过程
- 而是直接返回查询缓存中的结果集
控制MySQL并发读写
问题:email邮箱!一个邮箱的邮件都是串行在一起的彼此首位相连。这种格式对于读取和分析邮件信息非常友好,同时投递也很容易,只要在末端添加邮件就可以了。正题来了假如两个进程在同一时刻对同一个邮箱进行投递邮件时会发生什么?
答案:数据会被破环,两封邮件内容会交叉的附加在邮箱文件的末尾!
方案:通过lock锁防止数据损坏。如果客户端试图投递邮件,而邮箱已经被其他客户锁住,那就必须等待,直到释放才能进行投递。
通过这种方案的确可以做到数据不被破坏,但是如果只能等待的话并发效率太低了!读写锁的展开
读写锁:
- 读锁是共享的或者说是相互不阻塞的。多个客户在同一时刻可以同时读取同一个资源互不干扰。
- 写锁是排他锁也就是会阻塞其他的写锁和读锁。这也是出于安全考虑。只有这样才能确保在一定的时间内一个用户能够执行写入并防止其他用户读取正在写入的同一资源。
通过这种方式解决了数据破坏问题,效率也有所提高,真正大型项目还是不够!锁粒度与锁策略的展开
解决目标:提高资源的并发的方法可以只锁定需要修改的部分数据,而不是所有资源。更理性的方式是只对会修改的数据片进行精确锁定,任何时候在给定的资源中,锁定的数据量越少则系统开发程度越高,只要不冲突就可以了。
锁策略与锁粒度:在锁的开销与安全性寻求一个平衡,这种平衡也会影响性能。大多数数据库会直接用行级锁。MySQL提供了多种选择,每一个存储引擎都可以实现自己的锁粒度和锁策略。比如将锁粒度固定在某个级别,可以为某些场景提供更好的性能。如果性能需求提高直接提高锁粒度就可以了。下面展开两个重要的锁策略表锁和行级锁。
表锁与行级锁:
区别:
- 表锁是最基本的锁策略,也是开销最小的策略,表锁是直接锁定整张表,一个用户对表进行写入操作时需要获得写锁才可以。获取写锁之后会阻塞其他用户对他的读写操作。只有没有写锁的时候其他读取的用户才能获得读锁进行读取。读锁之间是不阻塞的
- 行级锁可以心最大程度上支持并发处理,同样的道理,也是开销最大的策略。行级锁只有在存储引擎层实现,MySQL服务器层不参与实现。
事务:
什么是事务呢?事务就是银行的需求一样,如果在执行过程中断电或者不符合条件的情况被停止执行,则已经执行的sql语句全部回滚。也就是说 事务操作过程要不全部成功,要不全部失败!事务ACID的特性可以确保银行不会弄丢你的钱
事务的ACID:
- 原子性:要不全部成功,要不全部失败,不可能只执行其中一部分操作,这就是事务的原子性
- 一致性:一致性主要体现在数据一致性,事务最终没有提交,事务所修改的数据不会保存在数据库中
- 隔离性:当前事务执行的修改在最终提交之前,对其他事务是不可见的。
- 持久性:一旦事务提交,将修改的数据持久化到数据库中就算数据库断电崩溃也不会丢失。
应用开发中的选型:
实现的ACID数据库跟没有实现ACID数据库,通常会需要更长的CPU处理能力以及更大的内存和磁盘空间。所以一定要根据当前特定的需求业务选择相应的数据库存储引擎。如果不需要事务,选择非事务存储引擎可以获得更高的性能。
事务的四种隔离级别:
- read uncommitted(未提交读):事务中的修改即使没有提交对其他事务都是可见的,也可以称为脏读,这个级别会导致很多问题,从性能上来说不会比其他隔离级别好太多,但缺乏其他隔离级别的很多好处。除非真的有特定的需求,一般很少用
- reda committed(提交读):大多数数据库默认的都是read committed,但是MySQL默认的不是这个!一个事务从执行到提交前,其他事务都是不可见的,有时候也可以叫不可重复读,因为两次执行同样的查询可能会得到不一样的查询结果。
- repeatable read(可重复读):repeatable read解决了read committed脏读的问题,这个隔离级别也是MySQL默认的隔离级别。该级别保证了同一个事务多次执行可以读取同样的数据,但是有个缺陷就是存在幻读!幻读就是当事务在某个范围内读取数据时,这时另一个事务在这个范围插入了数据,当读取的事务再次读取该范围时会产生幻行。通过多版本并发控制(MVCC)解决了幻读的问题。
- serializable(可串行化):这是最高的隔离级别,它通过强制事务在从串行上执行,避免了前面说的幻读问题,简单来说就在在读取数据时加一个锁,这就暴露了另一个问题,大量的加锁会导致出现争锁超时的问题。只有特定的需求情况下或者可以接收没有并发的情况下才考虑这种隔离级别。
MySQL中的事务
MySQL默认采用自动提交的模式。也就是说如果不是专门写一个事务执行,则每个查询都可以看成是一个事务。
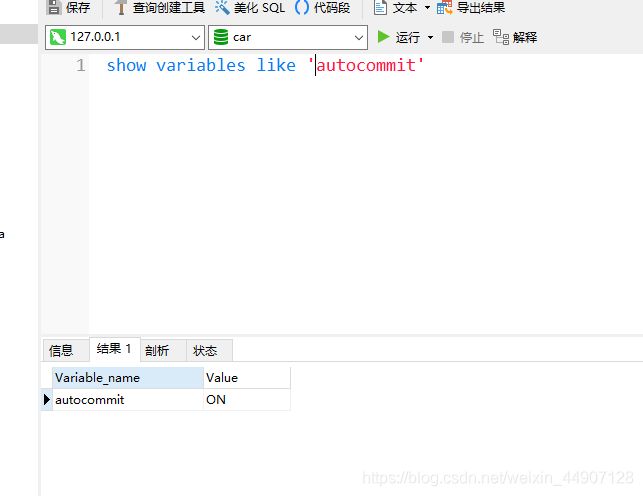
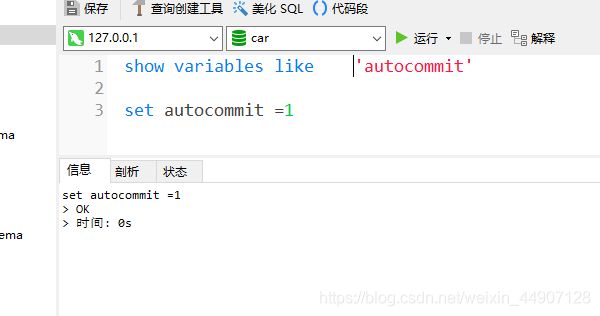
第一图可以查看当前的事务提交模式,第二张图可以修改事务提交模式 1或者NO表示启动,0或者OFF表示禁用
- 当autocommit=0时,所有的查询都是在一个事务,直到专门直接commit或者rollback回滚,该事务结束同时又开始了新的事务,修改autocommit对非事务型的表不会有任何影响。对于这类表来说没有commit或者rollback的概念,也可以说相当于一直处于启用的状态
- MySQL可以通过执行以下代码设置隔离级别。
set transaction isolationlevel //设置隔离级别,设置隔离级别会在下一个事务开始的时候生效
死锁:
很多时候会看到博客文章标题出现死锁数据,那么死锁到底是什么?什么导致了死锁?
死锁是指两个或多个事务对同一资源的相互占用。当前执行写操作时,另一方需要获得一个写锁,而另一个事务也是需要获得一个写锁。两个事务都等待着对方释放锁,同时又持有对方的锁。从而导致恶性循环的现象。除非有外部因素介入才可能接触死锁。死活会影响查询数据的效率。以下两个情况会死锁
- 当多个事务试图以不同的顺序锁定资源时,就可能发生了死锁
- 多个事务同时访问同一个资源时,也会产生死锁
事务1:
start transaction
update StockPrice set close=45 where stockid=4 and date=‘2021-01-31’
update StockPrice set close=40 where stockid=3 and date=‘2021-01-31’
事务2:
start transaction
update StockPrice set close=35 where stockid=3 and date=‘2021-01-31’
update StockPrice set close=30 where stockid=4 and date=‘2021-01-31’
以上代码举个例子帮助不懂的更好的理解。如果两个事务都执行的update的第一条语句,根据锁的过程会锁定当前的那一条数据(锁定id等于3和4的数据)也就是给他上锁,当两个事务执行第二条sql语句执行的时候(操作id等于3和4)就存在了死锁的情况因为两个都上锁也都等待着对方释放锁。
为了解决这一问题,数据库系统实现了死锁超时机制和各种死锁检测。InnoDB存储引擎检测到死锁的循环依赖,会立即返回一个错误,这种方式很有效。还有一种方式是当查询的时间达到锁等待超时的设定后放弃锁请求。这种不太友好。
目前InnoDB的处理方式是将持有最少行级锁的事务进行回滚(这是相对比较简单的死锁回滚算法)
死锁产生有双重原因
- 数据存在冲突
- 存储引擎的实现方式
如何处理死锁呢?
- 死锁发生后,只有部分或者完全回滚其中一个事务,才能打破死锁这是无法避免的。
- 大多数情况下只需要重新执行因死锁导致的事务即可。
先给猫洗个澡等会回来继续写

事务日志
存在优势:事务日志可以提高事务的效率。
实现方式:存储引擎在修改表数据的时候只需要修改其内存拷贝,再把修改的数据持久化到事务日志中,而不用每一次都把数据持久化到磁盘。事务日志采用追加的方式。所以写日志的操作是磁盘上一小块区域的顺序IO,而不像随机ID需要在磁盘的多个地方移动磁头,所以采用事务日志的方式会快很多。事务日志持久之后,内存中被修改的数据就可以在后台慢慢的刷回磁盘中,从而不会影响用户体验也提升了性能。修改数据需要写两次磁盘
多版本并发控制(MVCC)
概念:MySQL大多数事务型存储引擎实现的都不是简单的行级锁,基于提高行级锁的性能,一般同时都实现了多版本并发控制(mvcc)。不仅MySQL,包括oracle,postgresql等其他数据库系统都实现了mvcc,因为mvcc没有统一的实现标准,所以各自的实现机制也都不一样。
实现方式:通过保存数据在某一个时间点的快照来实现的。也就是说不管需要执行多长时间。每次事务执行的数据都是一致的。相反! 根据事务开始时间的不同选择的快照也是不同的,所以每个事务对同一张表,同一个时刻看到的数据有可能是不一样的。(如果没有这一方面的概念听起来可能有点迷惑)
多版本并发控制实现的不同,典型的实现有乐观锁并发控制与悲观锁并发控制。
如何工作的?
MVCC通过每行记录后面保存两个隐藏的列来实现的,一个是保存行的创建时间,一个是保存行的过期时间。存储的不是时间值,而是系统的版本号。每开始一个新的事务,系统版本号会自动增加。事务开始时刻的系统版本号也就是事务的版本号,用来查询到每行记录的版本号进行对比。
- select:innodb会根据以下两个条件检查每行记录。只有符合以下条件才能返回作为查询的结果
a=> InnoDB只查找版本早于当前事务版本的数据行(也就是行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么就是事务自身插入或者修改过的。
b=> 行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。 - insert:innodb为新插入的每一行保存当前系统版本号作为行版本号
- delete:innodb为删除的每一行保存当前的系统版本号作为行删除标识
- update:innodb为插入每一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统系统版本号到原来的行作为行删除标识。
优点:保存这两个额外的系统版本号的好处就是 操作数据的时候不需要单独上锁,这样设计使得数据操作很简单,性能也很好。并且也能保证只会读取到符合标准的行。
缺点:每行记录都需要额外的存储空间,需要做更多的检查行的操作,以及额外的维护工作
MVCC只在repertable read(可重复读)和read committed(提交读)两种隔离级别下工作。其他两种隔离级别都和mvcc不兼容!
Tip:read uncommitted总是读取最新的数据行,而不符合当前事务版本的数据行。serializable则会对所有读取的行都加锁
面试技巧流程
自我介绍什么的我就不说了,只说一下技术,拿Socket举例。
常见的小白场景就是
面试官:简单的介绍一下Socket
应聘人:你好面试官,不好意思我没用过,好像是通信用的。
常见的初级场景就是。
面试官:简单的介绍一下Socket
应聘人:你好面试官,Socket是一个安全套接字,用于通信。一个发送点一个接收点,有多种通信协议比如UDP/TCP,TCP是三次握手,UDP是不用握手的。UDP比TCP更高效。如果需要交互判断的选择TCP,如果不需要交互判断的选择UDP。
以上没有加分项,或许你可以这样,中级场景
面试官:简单的介绍一下Socket
应聘人:你好面试官,Socket我了解的是:
A=>安全套接字,要想聊Socket就要深入计算机底层我们可以从OSI7层模型说起,描述每一层的作用。
B=>TCP是什么,告诉面试官为什么是面向连接的可靠的传输协议。TCP三次握手都做了哪些事情比如Syn包,Ack包,Syn+Ack包。
C=> 通过交互流程可以展开ddos简单介绍一下表明你懂的比较多。你是个有干货的人,你是个对技术敏感的人。乐于学习的人
告诉面试官Socket在每一层都做了什么以及Socket通信的时候是如何和外界联系的【加分项】
更多面试思路干货,请前往微信搜【欢少的成长之路】 或者下面扫码关注 回复【面试思路】获取 感谢各位支持


结尾
目前更新出来的是我学习到的经验知识与心得,剩下的部分将过几天持续更新!
知道的越多,不知道的就越多。找准方向,坚持自己的定位!加油向前不断前行,终会有柳暗花明的一天!
创作不易,你们的支持就是对我最大认可!
文章将持续更新,我们下期见!下期将持续更新【详解二】 QQ群:1076570504 微信公众号搜索【欢少的成长之路】请多多支持!