Linear regression with one variable - Gradient descent for linear regression
摘要: 本文是吴恩达 (Andrew Ng)老师《机器学习》课程,第二章《单变量线性回归》中第12课时《线性回归的梯度下降》的视频原文字幕。为本人在视频学习过程中逐字逐句记录下来以便日后查阅使用。现分享给大家。如有错误,欢迎大家批评指正,在此表示诚挚地感谢!同时希望对大家的学习能有所帮助。
In previous videos, we talked about the gradient descent algorithm, and we talked about the linear regression model, and the squared error cost function. In this video, we're going to put together gradient descent with our cost function, and that will give us an algorithm for linear regression for fitting a straight line to our data.

So, this is what we worked out in the previous videos. That's our gradient descent algorithm which should be familiar, and here (on the right) is the linear regression model with our linear hypothesis and our squared error cost function. Now, in order to apply gradient descent, in order to write this piece of code (on the left), the key term we need is this derivative term over here (red box).

So, we need to figure out what is this partial derivative term. Plug in the definition of the cost function J. This turns out to be this, something might equal 1 through m of this squared error cost function term. And all I did here was just you know plugging in the definition of the cost function there and simplifying a little bit more. This turns out to be equal to this something equals 1 through m of ![]() . And all I did there was took the definition for my hypothesis and plug that in there. And it turns out we need to figure out what is the partial derivative of the two cases, for
. And all I did there was took the definition for my hypothesis and plug that in there. And it turns out we need to figure out what is the partial derivative of the two cases, for 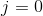 and for
and for 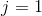 . So we want to figure out what is this partial derivative for both the
. So we want to figure out what is this partial derivative for both the 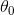 case and the
case and the  case. And I’m just going to write out the answers.
case. And I’m just going to write out the answers.

And computing these partial derivatives. So we are going from this equation to either of these equations down there. Computing those partial derivative terms requires some multivariate calculus. If you know calculus, feel free to work through the derivations yourself, and check the derivatives you actually get the answers that I got. But if you are less familiar with calculus, you don’t worry about it, it is fine to just take the equations I worked out, and you won’t need to know calculus or anything like that. You know you did the homework, so to implement gradient descent you’d get that to work.

But so, after these definitions, or after what we’ve worked out to be the derivatives which is really just the slope of the cost function J. We can now plug them back in to our gradient descent algorithm. So here's the gradient descent for linear regression, which is going to repeat until convergence, and get updated, as you know, the same minus  times the derivative term. So, here is our linear regression algorithm. This first term here, that term is, of course, just a partial derivative with respect to
times the derivative term. So, here is our linear regression algorithm. This first term here, that term is, of course, just a partial derivative with respect to 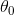 that we worked out in the previous slide. And this second term here, that term is just a partial derivative with respect to the that we worked out on the previous slide. And just a quick reminder, you must, when implementing gradient descent, there is actually detail that, you know, you should be implementing it, so the update and simultaneously. So, let’s see how gradient descent works. One of the issues we solved gradient descent is that it can be susceptible to local optima.
that we worked out in the previous slide. And this second term here, that term is just a partial derivative with respect to the that we worked out on the previous slide. And just a quick reminder, you must, when implementing gradient descent, there is actually detail that, you know, you should be implementing it, so the update and simultaneously. So, let’s see how gradient descent works. One of the issues we solved gradient descent is that it can be susceptible to local optima.


So, when I first explained gradient descent, I showed you this picture. It is going downhill on the surface, and we saw how, depending on where you’re initializing, you can end up with different local optima. You end up here or here (the two red arrows). But it turns out that the cost function for linear regression is always going to be a bowl-shaped function like this. The technical term for this is that this is called a convex function. And I’m not going to give the formal definition for what is a convex function, c-o-n-v-e-x, but informally a convex function means a bowl-shaped function. And so, this function doesn’t have any local optima, except for the one global optimum. And does gradient descent on this type of cost function which you get whenever you’re using linear regression, it will always convert to the global optimum because there are no other local optima other than global optimum.
 figure-1
figure-1
 figure-2
figure-2
 figure-3
figure-3
 figure-4
figure-4
 figure-5
figure-5
 figure-6
figure-6
 figure-7
figure-7
 figure-8
figure-8
So now, let's see this algorithm in action. As usual, here are plots of the hypothesis function and of my cost function  . And so, let's see how to initialize my parameters at this value (red cross). Usually you initialize your parameters at
. And so, let's see how to initialize my parameters at this value (red cross). Usually you initialize your parameters at 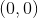 . But for illustration in this specific in gradient descent, I've initialized at about 900 and at about -0.1, okay? And so, this corresponds to
. But for illustration in this specific in gradient descent, I've initialized at about 900 and at about -0.1, okay? And so, this corresponds to ![]() . It's this line (figure-1). So, out here on the cost function. Now if we take one step of gradient descent, we end up going from this point out here a little bit to the down left, to that second point over there. And, you notice that my line changed a little bit (figure-2). And, I take another step at gradient descent, my line on the left will change, right (figure-3)? And I have also moved to a new point on my cost function. And as I take further step of gradient descent, I'm going down in cost, right (figure-4)? So, my parameter is following this trajectory. And if you look on the left, this corresponds to hypotheses that seem to be getting better and better fits for the data (figure-5 to figure 7). Until eventually, I have now wound up at the global minimum. And this global minimum corresponds to this hypothesis which gives me a good fit to the data. And so, that's gradient descent, and we've just run it, and gotten a good fit to my data set of housing prices. And you can now use it to predict, you know, if your friend has a house with a size of 1250 square feet, you can now read off the value, and tell them that, I don't know, maybe they can get $350,000 for their house.
. It's this line (figure-1). So, out here on the cost function. Now if we take one step of gradient descent, we end up going from this point out here a little bit to the down left, to that second point over there. And, you notice that my line changed a little bit (figure-2). And, I take another step at gradient descent, my line on the left will change, right (figure-3)? And I have also moved to a new point on my cost function. And as I take further step of gradient descent, I'm going down in cost, right (figure-4)? So, my parameter is following this trajectory. And if you look on the left, this corresponds to hypotheses that seem to be getting better and better fits for the data (figure-5 to figure 7). Until eventually, I have now wound up at the global minimum. And this global minimum corresponds to this hypothesis which gives me a good fit to the data. And so, that's gradient descent, and we've just run it, and gotten a good fit to my data set of housing prices. And you can now use it to predict, you know, if your friend has a house with a size of 1250 square feet, you can now read off the value, and tell them that, I don't know, maybe they can get $350,000 for their house.

Finally, just to give another name. It turns out that the algorithm that we just went over is sometimes called batch gradient descent. And it turns out in machine learning, I feel like us machine learning people were not always created and given me some algorithms. But the term batch gradient descent means that refers to the fact that, in every step of gradient descent, we’re looking at all of the training example. So, in gradient descent, you know, when computing derivatives, we’re computing these sums, this sum of 
 . So in every separate gradient descent, we end up computing something like this, that sums over our M training examples. And so the term batch gradient descent refers to the fact when looking at the entire batch of training examples, this is really, really not a great name, but this is what Machine Learning people call it. And it turns out there are sometimes other versions of gradient descent that are not batch versions, but instead do not look at the entire training set, but look at small subsets of the training sets at a time, and we’ll talk about those versions later in this course as well. But for now, using the algorithm you just learned about, while using batch gradient descent. You now know how to implement gradient descent for linear regression.
. So in every separate gradient descent, we end up computing something like this, that sums over our M training examples. And so the term batch gradient descent refers to the fact when looking at the entire batch of training examples, this is really, really not a great name, but this is what Machine Learning people call it. And it turns out there are sometimes other versions of gradient descent that are not batch versions, but instead do not look at the entire training set, but look at small subsets of the training sets at a time, and we’ll talk about those versions later in this course as well. But for now, using the algorithm you just learned about, while using batch gradient descent. You now know how to implement gradient descent for linear regression.
So, that's linear regression with gradient descent. If you've seen advanced linear algebra before, so some of you may have taken a class with advanced linear algebra, you might know that there exists a solution for numerically solving for the minimum of the cost function without needing to use an iterative algorithm like gradient descent. Later in this course, we'll talk about that method as well that just solves for the minimum cost function without needing this multiple step of gradient descent. That other method is called normal equation method. But in case you have heard of that method, it turns out gradient descent will scale better to larger data sets than that normal equation method. And now that we know gradient descent, we'll be able to use it in lots of different contexts, and we'll use it in lots of different machine learning problems as well. So, congrats on learning about your first Machine Learning algorithm. We'll later have exercises in which we'll ask you to implement gradient descent and hopefully see these algorithms work for youself. But before that, I first want to tell you, in the next videos, a generalization of the gradient descent algorithm that will make it much more powerful, and I guess I will tell you about that in the next video (article).