kobe
科比职业生涯回顾与模型预测
2016年4月13日,NBA巨星科比退役,结束了自己的篮球生涯。2020年1月26日,科比去世,令球迷悲痛不已。在此回顾科比20年的NBA生涯,以更深入的了解这位传奇,同时向科比致敬。
本文主要内容如下:
- 数据采集
- 数据清洗
- 数据分析
- 数据概览
- 胜率
- 出勤率
- 命中率
- 对阵球队
- 时间序列模型预测
- 比赛结果预测
- 结论
一、数据采集
import pandas as pd
# 爬取科比常规赛数据
df = pd.read_html('http://www.stat-nba.com/query.php?page=0&QueryType=game&GameType=season&Player_id=195&crtcol=season&order=1#label_show_result',encoding='utf-8',index_col=0)[0]
for page in range(67):
url = f'http://www.stat-nba.com/query.php?page={page+1}&QueryType=game&GameType=season&Player_id=195&crtcol=season&order=1#label_show_result'
temp = pd.read_html(url,encoding='utf-8',index_col=0)[0]
df = pd.concat([df,temp])
df.to_csv('kobe_regular.csv',index=None)
# 爬取科比季后赛数据
df_2 = pd.read_html('http://www.stat-nba.com/query.php?page=0&QueryType=game&GameType=playoff&Player_id=195&crtcol=season&order=1#label_show_result',encoding='utf-8',index_col=0)[0]
for page in range(10):
url = f'http://www.stat-nba.com/query.php?page={page+1}&QueryType=game&GameType=playoff&Player_id=195&crtcol=season&order=1#label_show_result'
temp = pd.read_html(url,encoding='utf-8',index_col=0)[0]
df_2 = pd.concat([df_2,temp])
df_2.to_csv('kobe_playoff.csv',index=None)
二、数据清洗
1、缺失值处理及数据替换
# 读取数据
import pandas as pd
df_r = pd.read_csv('kobe_regular.csv')
df_o = pd.read_csv('kobe_playoff.csv')
# 替换"结果"中的字符
df_r.replace({
'胜':1,'负':0},inplace=True)
df_o.replace({
'胜':1,'负':0},inplace=True)
# 将字符串转换为float
df_r[['投篮','三分','罚球']]=df_r[['投篮','三分','罚球']].apply(lambda x:x.str.replace('%', '').astype('float')/100)
df_o[['投篮','三分','罚球']]=df_o[['投篮','三分','罚球']].apply(lambda x:x.str.replace('%', '').astype('float')/100)
# def convert_percent(x):
# new = x.str.replace('%','')
# return float(new)/100
# df['投篮'].apply(convert_percent)
#查看缺失数据
df_r.isnull().values.sum()
df_o.isnull().values.sum()
25
df_r[df_r.isnull().any(axis=1)].iloc[:,7:].head(10)
| 命中 | 出手 | 三分 | 命中.1 | 出手.1 | 罚球 | 命中.2 | 出手.2 | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 1 | 7 | 0.000 | 0 | 2 | NaN | 0 | 0 | 2 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 2 |
| 27 | 4 | 13 | 0.286 | 2 | 7 | NaN | 0 | 0 | 4 | 0 | 4 | 3 | 2 | 0 | 2 | 2 | 10 |
| 28 | 5 | 9 | 0.000 | 0 | 1 | NaN | 0 | 0 | 2 | 0 | 2 | 1 | 0 | 0 | 5 | 1 | 10 |
| 29 | 2 | 9 | 0.250 | 1 | 4 | NaN | 0 | 0 | 2 | 1 | 1 | 6 | 0 | 1 | 3 | 2 | 5 |
| 31 | 2 | 5 | 0.500 | 1 | 2 | NaN | 0 | 0 | 2 | 0 | 2 | 9 | 1 | 0 | 4 | 0 | 5 |
| 33 | 4 | 15 | 0.000 | 0 | 4 | NaN | 0 | 0 | 6 | 2 | 4 | 3 | 2 | 1 | 2 | 2 | 8 |
| 47 | 5 | 13 | 0.500 | 1 | 2 | NaN | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 2 | 2 | 11 |
| 49 | 2 | 15 | 0.167 | 1 | 6 | NaN | 0 | 0 | 3 | 0 | 3 | 1 | 1 | 0 | 3 | 2 | 5 |
| 57 | 5 | 13 | 0.000 | 0 | 5 | NaN | 0 | 0 | 4 | 0 | 4 | 5 | 2 | 0 | 3 | 2 | 10 |
| 69 | 2 | 12 | 0.000 | 0 | 3 | NaN | 0 | 0 | 8 | 0 | 8 | 7 | 1 | 0 | 6 | 1 | 4 |
缺失值均为命中率,且仅在无出手时才为0,理应删除该类缺失,但此处先保留,分析时再做处理
2、将“比赛”列拆分为对阵双方的比分,方便后续比较
import re
# 将“比赛”列拆分为对阵双方
df_r_score= df_r['比赛'].str.split('-',1,expand=True).rename(columns={
0:'对手',1:'湖人'})
df_o_score= df_o['比赛'].str.split('-',1,expand=True).rename(columns={
0:'对手',1:'湖人'})
# 提取湖人比分
df_r_score['湖人得分']=df_r_score['湖人'].str.extract(r'(\d+)',expand=True)
df_o_score['湖人得分']=df_o_score['湖人'].str.extract(r'(\d+)',expand=True)
# 将对手比分和队名拆分,其中队名中“76人”既有数字又有字符,因此使用正则表达式
rival = []
for i in range(len(df_r)):
tem = re.split(r'(\d+\D|\D+)',df_r_score['对手'][i],maxsplit=1)
rival.append(tem)
# 合并两队数据,删除无用列
df_r_score = df_r_score.join(pd.DataFrame(rival)).drop(['对手','湖人',0],axis=1).rename(columns={
1:'对手',2:'对手得分'})
rival = []
for i in range(len(df_o)):
tem = re.split(r'(\d+\D|\D+)',df_o_score['对手'][i],maxsplit=1)
rival.append(tem)
# 合并两队数据,删除无用列
df_o_score = df_o_score.join(pd.DataFrame(rival)).drop(['对手','湖人',0],axis=1).rename(columns={
1:'对手',2:'对手得分'})
df_r_score = df_r_score.join(df_r['果'])
df_o_score = df_o_score.join(df_o['果'])
df_r_score.to_csv('df_r_score.csv')
df_o_score.to_csv('df_o_score.csv')
3、重新命名列名
df_r.columns
Index(['球员', '赛季', '果', '比赛', '首发', '时间', '投篮', '命中', '出手', '三分', '命中.1',
'出手.1', '罚球', '命中.2', '出手.2', '篮板', '前场', '后场', '助攻', '抢断', '盖帽', '失误',
'犯规', '得分'],
dtype='object')
df_o.columns
Index(['球员', '赛季', '果', '比赛', '时间', '投篮', '命中', '出手', '三分', '命中.1', '出手.1',
'罚球', '命中.2', '出手.2', '篮板', '前场', '后场', '助攻', '抢断', '盖帽', '失误', '犯规',
'得分'],
dtype='object')
# 删除无用列,重新命名列名
df_r.drop(['球员','比赛'],axis=1,inplace=True)
df_o.drop(['球员','比赛'],axis=1,inplace=True)
df_r.columns = ['赛季', '结果', '首发', '出场时间', '投篮命中率', '投篮命中', '投篮出手', '三分命中率', '三分命中', '三分出手',
'罚球命中率', '罚球命中', '罚球出手', '篮板', '前场', '后场', '助攻', '抢断', '盖帽', '失误', '犯规',
'得分']
df_o.columns = ['赛季', '结果', '出场时间', '投篮命中率', '投篮命中', '投篮出手', '三分命中率', '三分命中', '三分出手',
'罚球命中率', '罚球命中', '罚球出手', '篮板', '前场', '后场', '助攻', '抢断', '盖帽', '失误', '犯规',
'得分']
df_r.head()
| 赛季 | 结果 | 首发 | 出场时间 | 投篮命中率 | 投篮命中 | 投篮出手 | 三分命中率 | 三分命中 | 三分出手 | ... | 罚球出手 | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15-16 | 1 | 1 | 42 | 0.440 | 22 | 50 | 0.286 | 6 | 21 | ... | 12 | 4 | 0 | 4 | 4 | 1 | 1 | 2 | 1 | 60 |
| 1 | 15-16 | 0 | 1 | 19 | 0.333 | 4 | 12 | 0.333 | 3 | 9 | ... | 2 | 1 | 0 | 1 | 0 | 1 | 0 | 2 | 2 | 13 |
| 2 | 15-16 | 0 | 1 | 27 | 0.455 | 10 | 22 | 0.364 | 4 | 11 | ... | 11 | 2 | 0 | 2 | 1 | 2 | 0 | 4 | 1 | 35 |
| 3 | 15-16 | 0 | 1 | 22 | 0.267 | 4 | 15 | 0.333 | 3 | 9 | ... | 3 | 3 | 0 | 3 | 4 | 1 | 0 | 2 | 0 | 14 |
| 4 | 15-16 | 0 | 1 | 28 | 0.316 | 6 | 19 | 0.167 | 1 | 6 | ... | 4 | 3 | 0 | 3 | 1 | 1 | 0 | 1 | 1 | 17 |
5 rows × 22 columns
4、添加每个赛季的场次
由于原始数据为倒序排列,因此须将比赛按时间发生的顺序重新排列,并将每赛季的比赛添加场次信息
# 倒序,重置索引
df_r.sort_index(ascending=False,inplace=True)
df_o.sort_index(ascending=False,inplace=True)
df_r.reset_index(drop=True,inplace=True)
df_o.reset_index(drop=True,inplace=True)
# 将赛季信息按原来的顺序组成含有唯一值的列表
df_index = list(df_r['赛季'])
t = list(set(df_index))
t.sort(key=df_index.index)
# 生成场次的序列,并添加至原数据
game = []
for session in t:
length = len(df_r[df_r['赛季']==session])
tem = np.array([i+1 for i in range(length)])
game = np.concatenate((game,tem))
df_r['场次'] = pd.DataFrame(game.astype(int))
game = []
for session in t:
length = len(df_o[df_o['赛季']==session])
tem = np.array([i+1 for i in range(length)])
game = np.concatenate((game,tem))
df_o['场次'] = pd.DataFrame(game.astype(int))
df_r[df_r['赛季']=='98-99'].head(10)
# df_o[df_o['赛季']=='98-99'].head(10)
| 赛季 | 结果 | 首发 | 出场时间 | 投篮命中率 | 投篮命中 | 投篮出手 | 三分命中率 | 三分命中 | 三分出手 | ... | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | 场次 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 150 | 98-99 | 1 | 1 | 44 | 0.381 | 8 | 21 | 0.667 | 2 | 3 | ... | 10 | 2 | 8 | 2 | 2 | 3 | 2 | 4 | 25 | 1 |
| 151 | 98-99 | 0 | 1 | 41 | 0.583 | 7 | 12 | 0.000 | 0 | 1 | ... | 12 | 2 | 10 | 3 | 0 | 2 | 5 | 6 | 16 | 2 |
| 152 | 98-99 | 1 | 1 | 41 | 0.421 | 8 | 19 | 0.250 | 1 | 4 | ... | 10 | 2 | 8 | 2 | 2 | 2 | 4 | 5 | 19 | 3 |
| 153 | 98-99 | 1 | 1 | 38 | 0.533 | 8 | 15 | 0.500 | 1 | 2 | ... | 10 | 1 | 9 | 5 | 1 | 0 | 3 | 5 | 21 | 4 |
| 154 | 98-99 | 0 | 1 | 38 | 0.381 | 8 | 21 | 0.000 | 0 | 3 | ... | 10 | 2 | 8 | 2 | 2 | 1 | 1 | 1 | 24 | 5 |
| 155 | 98-99 | 0 | 1 | 35 | 0.500 | 6 | 12 | 0.250 | 1 | 4 | ... | 2 | 0 | 2 | 0 | 2 | 2 | 3 | 5 | 18 | 6 |
| 156 | 98-99 | 1 | 1 | 31 | 0.571 | 8 | 14 | 0.000 | 0 | 1 | ... | 9 | 0 | 9 | 5 | 2 | 2 | 4 | 1 | 16 | 7 |
| 157 | 98-99 | 1 | 1 | 31 | 0.533 | 8 | 15 | NaN | 0 | 0 | ... | 9 | 1 | 8 | 4 | 1 | 0 | 3 | 2 | 23 | 8 |
| 158 | 98-99 | 1 | 1 | 42 | 0.474 | 9 | 19 | NaN | 0 | 0 | ... | 8 | 1 | 7 | 6 | 1 | 1 | 3 | 5 | 21 | 9 |
| 159 | 98-99 | 0 | 1 | 40 | 0.400 | 8 | 20 | 0.167 | 1 | 6 | ... | 13 | 4 | 9 | 2 | 1 | 0 | 4 | 5 | 23 | 10 |
10 rows × 23 columns
df_r.to_csv('kobe_regular_.csv',index=None)
df_o.to_csv('kobe_playoff_.csv',index=None)
三、数据分析
import pandas as pd
# 读取数据
df_r = pd.read_csv('G:/py_data/kobe_data/kobe_regular_.csv')
df_o = pd.read_csv('G:/py_data/kobe_data/kobe_playoff_.csv')
df_r.head()
| 赛季 | 结果 | 首发 | 出场时间 | 投篮命中率 | 投篮命中 | 投篮出手 | 三分命中率 | 三分命中 | 三分出手 | ... | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | 场次 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 96-97 | 1 | 0 | 6 | 0.000 | 0 | 1 | NaN | 0 | 0 | ... | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| 1 | 96-97 | 1 | 0 | 3 | 0.000 | 0 | 1 | NaN | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 2 |
| 2 | 96-97 | 0 | 0 | 7 | 0.667 | 2 | 3 | 0.500 | 1 | 2 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 5 | 3 |
| 3 | 96-97 | 0 | 0 | 17 | 0.375 | 3 | 8 | 0.667 | 2 | 3 | ... | 3 | 0 | 3 | 0 | 0 | 1 | 0 | 3 | 10 | 4 |
| 4 | 96-97 | 1 | 0 | 8 | 0.000 | 0 | 3 | NaN | 0 | 0 | ... | 3 | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 2 | 5 |
5 rows × 23 columns
1、科比职业生涯评价
科比职业生涯绵长,有整整20年,那么在这20年的职业生涯中,哪些赛季是他的生涯巅峰,哪个赛季又开始不负当年勇,他的命中率是否真如人们调侃的那般“铁”,科比输给最多的球队又是哪支呢?接下来我们用数据说话。
import warnings
warnings.filterwarnings('ignore')
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #加载本地字体以显示中文
# 按序排列的赛季序列
df_index = list(df_r['赛季'])
session_list = list(set(df_index))
session_list.sort(key=df_index.index)
# 计算科比的常规赛和季后赛胜率
win_r_rate = len(df_r[df_r['结果']==1])/len(df_r)
win_o_rate = len(df_o[df_o['结果']==1])/len(df_o)
print(win_r_rate,win_o_rate)
0.6210995542347697 0.6136363636363636
# 计算各赛季的胜率
win_r_single_rate = []
for session in session_list:
rate = df_r.groupby(by=['赛季','结果'],sort=False).count().loc[session,1][0]/df_r.groupby(by=['赛季'],sort=False).count().loc[session,:][0]
win_r_single_rate.append(rate)
# win_r_single_rate
win_o_single_rate = []
for session in session_list:
if session in ['04-05','12-13','13-14','14-15','15-16']: #该赛季未进季后赛
win_o_single_rate.append(0)
else:
rate = df_o.groupby(by=['赛季','结果'],sort=False).count().loc[session,1][0]/df_o.groupby(by=['赛季'],sort=False).count().loc[session,:][0]
win_o_single_rate.append(rate)
# win_o_single_rate
# 绘图查看科比职业生涯的胜率变化
fig, ax = plt.subplots(figsize=(10,5))
ax.plot(session_list,win_r_single_rate,'.-',label='常规赛胜率')
ax.plot(session_list,len(session_list)*[win_r_rate],'r',label='生涯胜率_常')
ax.plot(session_list,win_o_single_rate,'.-',label='季后赛胜率')
ax.plot(session_list,len(session_list)*[win_o_rate],label='生涯胜率_后')
ax.set_xlabel('赛季')
ax.set_ylabel('胜率')
plt.legend()

科比的常规赛胜率和季后赛胜率趋势基本保持一致。
以常规赛职业生涯胜率为基准的话,可将科比的职业生涯大致分为4个阶段,见下表。
| 赛季 | 96-04 | 04-07 | 07-12 | 12-16 |
|---|---|---|---|---|
| Kobe | 人生得意 | 短暂低潮 | 王者归来 | 英雄落寞 |
而季后赛的胜率则能明显说明湖人的两次王朝,分别为99-02赛季和08-10赛季(07-08赛季总决赛折戟波斯顿)
# 计算出勤率
import numpy as np
attendance = []
for session in session_list:
if session=='98-99':
rate = df_r.groupby(by=['赛季'],sort=False).count().loc[session,:][0]/50
elif session == '11-12':
rate = df_r.groupby(by=['赛季'],sort=False).count().loc[session,:][0]/66
else:
rate = df_r.groupby(by=['赛季'],sort=False).count().loc[session,:][0]/82
attendance.append(rate)
attendance_mean = np.array(attendance).mean()
# attendance
attendance_mean
0.8488174427198816
fig,ax = plt.subplots(figsize=(10,5))
ax.plot(session_list,attendance,'-o',label='赛季出勤')
ax.plot(session_list,len(session_list)*[attendance_mean],label='生涯出勤',)
[]
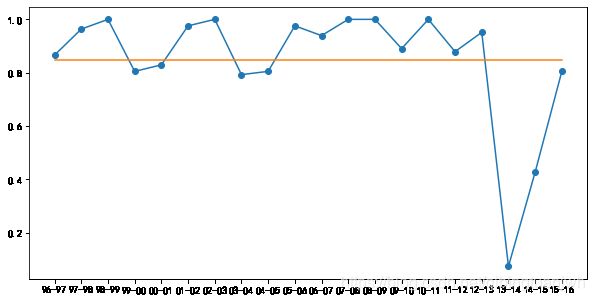
NBA在1967-68赛季最终将一个赛季的常规赛场次定为82场,一直沿袭至今,仅98-99,11-12赛季因劳资纠纷,赛季缩水至分别只有50场和66场比赛。
科比的出勤率在整个职业生涯中一直较高,常规赛平均出勤率高达85%,可能也正是这样的高出勤率最终导致了13-14赛季的大伤,也正是经历了这次大伤,科比再也未能重现荣光。
# 合并常规赛和季后赛的数据,方便可视化展示
df_all = pd.concat([df_r.drop(['首发'],axis=1),df_o],keys=['常规赛','季后赛'])
df_all.index.names = ['类型','x']
df_all = df_all.reset_index(['类型','x']).drop('x',axis=1)
import seaborn as sns
fig,ax = plt.subplots(3,1,figsize=(12,18))
pos = list(range(len(session_list)))
sns.boxplot(x='赛季',y='投篮命中率',hue='类型',data=df_all,ax=ax[0],palette="Set3")
sns.boxplot(x='赛季',y='三分命中率',hue='类型',data=df_all,ax=ax[1],palette="Set3")
sns.boxplot(x='赛季',y='罚球命中率',hue='类型',data=df_all,ax=ax[2],palette="Set3")
plt.show()
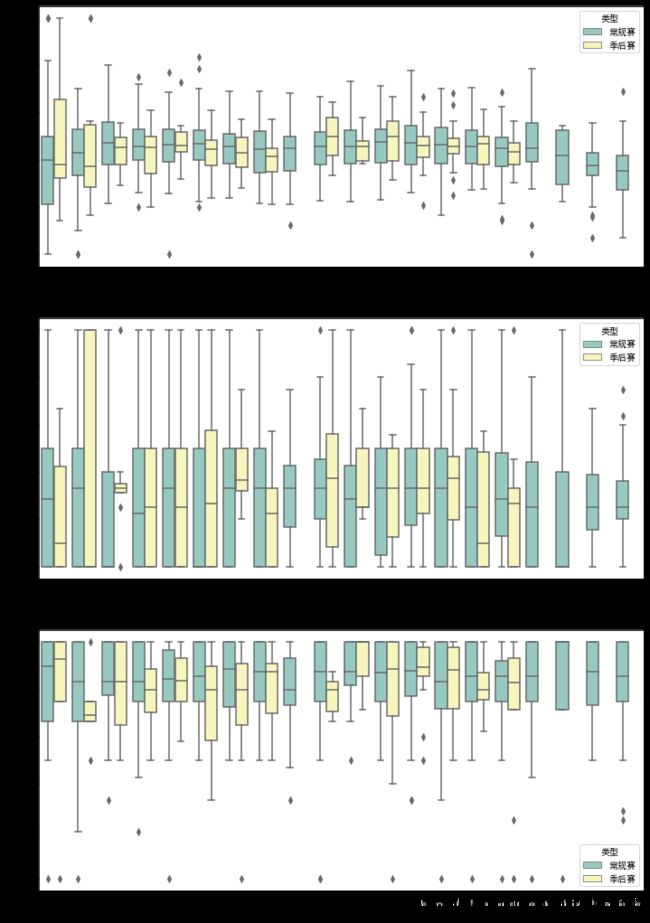
科比常规赛和季后赛命中率基本相差不大,但可以明显看出科比的三分球稳定性较差,这也可能是科比常被球迷调侃“铁”的原因之一吧。
import warnings
warnings.filterwarnings('ignore')
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
# 确定球队的顺序
df_r_score = pd.read_csv('G:/py_data/kobe_data/df_r_score.csv')
order = df_r_score.groupby(by='对手').count()['果'].sort_values(ascending=False).index
df_all.head()
| Unnamed: 0 | all | |
|---|---|---|
| 对手 | ||
| 76人 | 32 | 32 |
| 公牛 | 31 | 31 |
| 凯尔特 | 31 | 31 |
| 勇士 | 67 | 67 |
| 国王 | 64 | 64 |
# 计算对每只球队的胜率
df_win = df_r_score[df_r_score['果']==1].groupby(by='对手').count().drop(['湖人得分','对手得分'],axis=1).drop(['Unnamed: 0'],axis=1).rename(columns={
'果':'win'})
df_all = df_r_score.groupby(by='对手').count().drop(['湖人得分','对手得分'],axis=1).drop(['Unnamed: 0'],axis=1).rename(columns={
'果':'all'})
df_rate = df_win.join([df_all])
df_rate['rate'] = df_rate['win']/df_rate['all']
my_order = list(order)
df_rate.index = pd.CategoricalIndex(df_rate.index,categories=my_order,ordered=True)
pd.CategoricalIndex(df_rate.index,categories=my_order,ordered=True)
df_rate = df_rate.sort_index()
# 可视化展示
fig,ax = plt.subplots(2,1,figsize=(16,12))
sns.countplot(x='对手',data=df_r_score,color='gold',label='lose',order=order,ax=ax[0])
sns.countplot(x='对手',data=df_r_score[df_r_score['果']==1],color='purple',label='win',order=order,ax=ax[0])
ax[0].legend()
sns.barplot(my_order,df_rate['rate'],ax=ax[1],color='purple')

df_rate[df_rate['rate']<0.5]['rate'].sort_values()
对手
鹈鹕 0.333333
马刺 0.409836
雷霆 0.454545
开拓者 0.483871
热火 0.484848
Name: rate, dtype: float64
以上32只队伍中,超音速为雷霆的前身,鹈鹕为黄蜂前身,子弹为奇才前身。
通过上图可以很明显看出,与西部球队的较量多于东部球队,这也是由于nba赛程设定导致的。而科比对阵过最多的球队竟然是同城的快船,洛城的球迷应该很幸福吧。
而在这15只西部球队中,战胜湖人最多的球队分别是马刺、雷霆和开拓者,嗯,就是波波维奇的那个马刺!
2、赛季时间序列模型预测
鉴于科比职业生涯前期较高的出勤率,仅在生涯末期的两个赛季出勤率较低,因此是否可以利用前期数据建立时间预测模型,来预测如果科比没有大伤的情况下,最后三个赛季的表现如何呢?
另外由于98-99和11-12赛季缩水,因此直接丢弃这两个赛季的数据。
games = pd.DataFrame(df_r.groupby(by=['赛季'],sort=False).count().iloc[:,0])
games.columns=['场次']
# games.sort_values('场次',ascending=False)
# 插入数据
import random
miss = df_r.loc[0]
miss['得分'] = np.nan # 需要插入的缺失数据
df_r_insert = df_r.copy()
for session in session_list:
miss['赛季'] = session
k = 82- games.loc[session][0]
insert_index = random.choices(df_r_insert[df_r_insert['赛季']==session].index,k=k)
df_values = np.insert(df_r_insert.values,insert_index,miss,axis=0)
df_r_insert = pd.DataFrame(df_values,columns=df_r_insert.columns)
#df_r_insert.groupby(by=['赛季']).count()[0] #查看是否插入正确
df_r_insert.shape
(1640, 23)
date = pd.date_range('1996','2016',periods=82*20) # 添加时间索引
df_r_insert.set_index(date,inplace=True)
session_drop = ['98-99','11-12','13-14','14-15','15-16'] #需要删除的赛季数据
df_r_drop = df_r_insert[-df_r_insert.赛季.isin(session_drop)]
df_r_drop.shape
(1230, 23)
# 生成标准数据
df_r_drop = df_r_drop.reset_index().rename(columns={
'index':'时间'})
data = df_r_drop[['时间','得分']]
data.columns=['ds','y']
data.head()
| ds | y | |
|---|---|---|
| 0 | 1996-01-01 00:00:00.000000000 | 0 |
| 1 | 1996-01-05 10:58:03.587553408 | 1 |
| 2 | 1996-01-09 21:56:07.175106816 | 5 |
| 3 | 1996-01-14 08:54:10.762660096 | 10 |
| 4 | 1996-01-18 19:52:14.350213504 | 2 |
365/82
4.451219512195122
import fbprophet
from fbprophet.plot import add_changepoints_to_plot
model = fbprophet.Prophet()
model.fit(data)
future = model.make_future_dataframe(periods=82*3,freq='4.45D')
forcast = model.predict(future)
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
from fbprophet.plot import add_changepoints_to_plot
fig = model.plot(forcast)
a = add_changepoints_to_plot(fig.gca(),model,forcast)
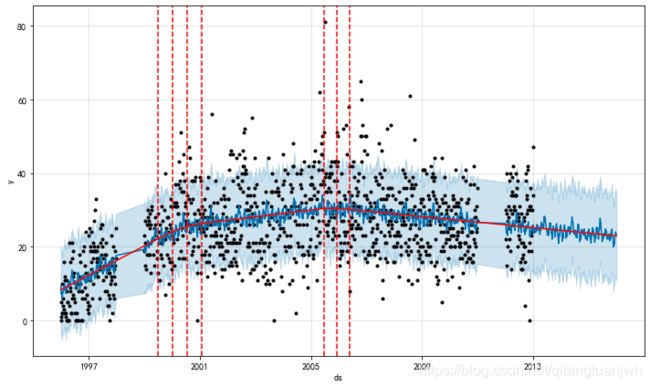
利用prophet对科比得分数据进行拟合预测,发现其职业生涯的两个状态拐点,分别为99-00赛季和05-06赛季,其中99-00赛季开启了科比的第一个三连冠,而05-06赛季则是“鲨鱼”东游后第二个赛季,科比逐渐适应了一个人扛起一支队伍的使命,仅从得分来说,此时已是科比的巅峰(单场得分记录在这一赛季也较多)。
# 对比13-14,14-15,15-16赛季的预测数据与真实数据
score_f = []
str = ['2013','2014','2015','2016']
for i in range(3):
score_f.append(forcast[(forcast['ds']>str[i])&(forcast['ds']<str[i+1])]['yhat'].mean())
score_a = []
periods = ['13-14','14-15','15-16']
for i in range(3):
score_a.append(df_r[df_r['赛季']==periods[i]]['得分'].mean())
print(score_a)
print(score_f)
[13.833333333333334, 22.34285714285714, 17.59090909090909]
[24.85394505977496, 24.066417125054304, 23.376864986074708]
from matplotlib import pyplot as plt
%matplotlib inline
fig,ax = plt.subplots(figsize=(12,6))
ax.plot(periods,score_f,'o-',label='预测')
ax.plot(periods,score_a,'*-',label='实际')
ax.set_xlabel('赛季')
ax.set_ylabel('得分')
plt.legend()
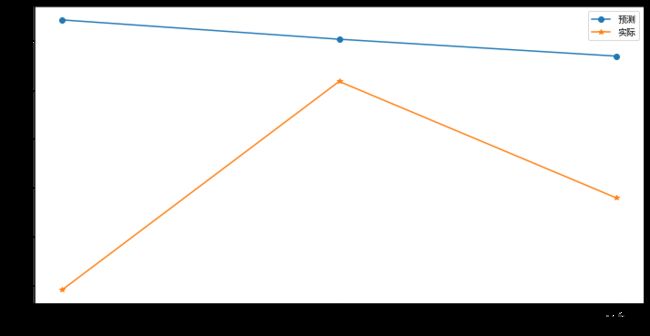
科比在经历了大伤之后,状态下滑,但根据健康时期的数据,我们预测科比最后三个赛季,仍可保持场均24分左右,而实际上科比在14-15赛季在出勤率将近5成的情况下,场均得分为22.3分,15-16赛季则下滑严重,场均得分为17.6分。不禁让人遐想如果没有伤病,科比会不会再征战几个赛季呢?
3、比赛结果预测
由于比赛结果只有两种,因此尝试使用支持向量机进行建模。
输入数据包括篮板、助攻、抢断、盖帽、失误、犯规、得分、出场时间、投篮命中率、三分命中率和罚球命中率,并做归一化处理。
# 归一化
def max_min_scaler(x): return (x-np.min(x))/(np.max(x)-np.min(x))
df_min_max = df_r[['篮板','助攻','抢断','盖帽','失误','犯规','得分','出场时间','投篮命中率','三分命中率','罚球命中率']].apply(max_min_scaler)
target = pd.DataFrame(df_r['结果'])
df_min_max = df_min_max.join(target).dropna() #删除缺失数据
# 数据集分类
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(df_min_max.iloc[:,:-1],df_min_max.iloc[:,-1],test_size=0.3,random_state=10)
# 建立SVM模型
import warnings
warnings.filterwarnings('ignore')
from sklearn.svm import SVC
model_svc = SVC(C=10000)
model_svc.fit(X_train,y_train)
SVC(C=10000, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
from sklearn.metrics import accuracy_score
# 训练集的正确率
y_train_a = model_svc.predict(X_train)
accuracy_score(y_train,y_train_a)
0.7785714285714286
# 测试集的正确率
model_svc.score(X_test,y_test)
0.6833333333333333
# 测试集的预测结果
model_svc.predict(X_test)
array([1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1,
0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0,
0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1,
0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1,
1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1,
1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1,
1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1,
1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1,
1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1,
1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0,
1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1,
1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1,
0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1,
1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1,
1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1,
0, 1, 0, 1, 1, 0, 0, 1], dtype=int64)
利用SVM对数据拟合,预测效果较差,测试集的正确率在60%-70%左右,看来仅用科比的数据来预测球队的胜负还是不太合理,尽管核心球员的确可能影响比赛结果,但篮球是10个人的运动,毕竟科比输的最多的球队可是马刺啊。
四、总结
1、科比的职业生涯大致可以分为四个阶段,而他的巅峰赛季在第三个阶段的05-06赛季。
2、如果科比未在生涯末期经历大伤,他的最后三个赛季的场均得分可达24分(奇妙的数字)左右。
3、利用科比的个人数据来预测比赛结果有待商榷。