感知机算法原理及matlab代码实现-统计学习方法学习笔记
前言
感知机(perceptron)是二分类的线性分类模型,输入实例数据,输出为实例的类别,分别取+1,-1二值。属于判别模型,感知机学习旨在求出将训练数据进行线性划分的分离超平面,其实现原理主要基于误分类的损失函数,利用梯度下降算法对损失函数进行极小化。感知机1957年由Rosenblatt提出,是神经网络与支持向量机的基础。
优点:简单易于实现。不需要太高的数学基础与编程技巧。
缺点:线性模型,不能表达复杂函数。
-
感知机模型
感知机有如下几何解释:线性方程
w * x + b = 0
对于特征空间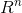 中的一个超平面S,其中w是超平面的发平面,b是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点(特征向量)分别呗分成正,负两类。因此,超平面S被称为分离超平面(separating hyperplane),如图2.1所示
中的一个超平面S,其中w是超平面的发平面,b是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点(特征向量)分别呗分成正,负两类。因此,超平面S被称为分离超平面(separating hyperplane),如图2.1所示

感知机学习,由训练数据集
T={(![]() ),(
),(![]() ),
),![]() ,(
,(![]() )}
)}
其中,![]() ,求得感知机模型即求得模型参数w,b。感知机预测,通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别。
,求得感知机模型即求得模型参数w,b。感知机预测,通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别。
2.感知机学习算法
2.1感知机学习算法的原始形式
感知机学习算法是对以下最优化问题的算法。给定一个训练数据集
T={(![]() ),(
),(![]() ),
),![]() ,(
,(![]() )}
)}
其中,![]() ,求参数w,b使其为以下损失函数极小化问题的解:
,求参数w,b使其为以下损失函数极小化问题的解:
![]()
其中M为误分类点的集合。
关于极小化损失函数为什么这么写,你可以这么考虑,当分类点w*x+b结果与yi结果相同时,即分类正确时对极小化函数是正贡献的,而分类点结果与实际分类,结果不同时,即分类不准确时,对于极小化函数时负贡献的。所以损失函数设计成这样是合理的。
感知机算法是以误分类驱动,具体采用随机梯度下降算法:
以下为算法大概步骤:
1.首先计算损失函数梯度:
![]()
![]()
其中M为误分类点集合。
2.随机选取一个误分类点(xi,yi),对w,b进行更新:
![]()
![]()
式中 (
(![]() )是步长,在统计学习中又称为学习率(learning rate)。 这样,通过迭代可以期待损失函数L(w,b)不断减小,直到0.综上所述可以得到最终的感知机算法:
)是步长,在统计学习中又称为学习率(learning rate)。 这样,通过迭代可以期待损失函数L(w,b)不断减小,直到0.综上所述可以得到最终的感知机算法:
算法(感知机学习算法)
输入:训练集 T={(![]() ),(
),(![]() ),
),![]() ,(
,(![]() )} ,其中
)} ,其中![]() 学习率
学习率![]() ;
;
输出:w,b;感知机模型![]() .
.
(1)选取初值![]() ;
;
(2)在训练集中选取数据![]() ;
;
(3)如果![]() ;
;
![]()
![]()
(4)转至(2),直至训练集中没有误分类点。
这种学习算法直观上可以理解成:一个点被误分类,但是你根据误分类点调整w,b值使得分力超平面向该误分类点的一侧移动,减少了误分类点与超平面间的距离。如此反复直至超平面越过该误分类点使得其被正确分类。
3.matlab代码实现
matlab代码如下:
function [y1,w,b]= Perceptual_machine(x,y,s,x1,w,b)
%%
%x:训练的数据集。
%y:分类的结果;
%s:学习的速率(0对书上例题进行函数调用:
clc,clear
x=[3,3;4,3;1,1];
y=[1 1 -1];
s=1;
x1=[2,2];
w0=0;
b0=0;
Perceptual_machine(x,y,s,s,w0,b0)其中:x为训练集,y为分类结果,s为学习率,x1为待分类数据集,w0,b0为w,b的初始值。观察每次迭代的w与b的结果发现与书中一致。
这里粘贴书中的结果:
