bootstrap-fileinput后端接收不到数据_饿了么:基于非阻塞Java的数据库中间件
背景介绍
随着饿了么业务体量成倍的上涨, 那种简单地通过客户端直连数据库的传统模式几乎已经触碰到了性能瓶颈。
此外, 饿了么基于多语言(Java,Python,Go,NodeJS等)开发的现状导致迫切需要一个基于代理模式的数据库中间件(以下简称为DAL)。并以此实现连接复用熔断、限流、配置变更、分库分表等特性。
由于所有SQL请求都会集中发往基于代理模式的DAL集群, 这就使得整个集群需要承载饿了么所有SQL流量并转发到相应的后端数据库。
所以, 如何提升DAL的性能, 提升单节点每秒所承载的SQL请求量和后端代理的数据库数量, 并保持节点的稳定和少抖动, 一直是我们开发团队所关注的。
注:
以下所展示的代码和示意图都是经过一些逻辑简化的, 主要是为了更为清晰地阐明核心思想
它与饿了么线上真实运行系统中的代码有所区别。
方案所期待的目标
- 不会创建过多数量的线程
- 让cpu处于忙碌状态而非等待
- 代码编写方便
- 尽量满足以上条件的Java技术方案
业界方案
提供SDK
业界有一部分的DAL都是基于客户端SDK的方式,需要为每一种编程语言单独开发一套SDK,且要保持彼此功能的兼容性. 对于饿了么这样有4种主流语言的公司来说成本较大.
后端阻塞模式
业界另一种基于代理模式的做法是前端(接收客户请求的一端)异步接受请求,后端(连接数据库的一端)通过jdbc等API同步阻塞连接数据库。这个方案的缺点是在流量逐渐升高或冲击的情况时, 后端容易出现阻塞和线程不够(NoAvailableThreads)的问题.
协程
这里要提一些协程这种技术, 它当初也在我们技术选型的范围之内. 因为它能够实现像多线程编程模型那样地编写阻塞代码,而不会实际创建过多的线程。
像Python,Go等语言已经能够天生支持(或部分支持)协程, 可以使得开发者比较容易地去编写高并发的服务端,无需再把精力花在为了减少线程而做的各种优化(如线程池,异步回调处理,上下文状态保存等)。不过,Java语言原生是没有协程的官方API和库的[^1], 于是我们还调研了支持协程的Java三方库[^2].我们希望这样的库在协程中也能够支持所有原生JDK的阻塞API(如Socket#connect,ServerSocket#accept),即能够支持创建10k+个协程,每个协程创建一个连接并调用阻塞的connect方法。
1IntStream.range(0, 100000).forEach( new Fiber(() -> { 2 System.out.println("This is a fiber not thread"); 3 Fiber.sleep(...); // NOT Thread.sleep() !!! 4 }).start() );以上这个例子我们可以看到,创建了100k个协程, 打印输出,然后sleep() 如果把Fiber换成Thread类,这段代码几乎是无法运行的。
看上去它只需把Thread替换为Fiber, 就可以方便地从线程切换到协程来支持高并发。遗憾的是,这样的协程库,它只能部分支持在协程中调用阻塞API, 因为它有个前置条件:在协程里,所有调用的阻塞API必须换成协程的版本。
仔细再看刚才的例子,我们除了在创建协程时把new Thread()换成了new Fiber(), 还把Thread.sleep()换成了Fiber.sleep()才实现了真正协程的功能。
由于这个限制, 我们不能随心所欲地调用阻塞API,而是必须先找到对应的API的协程版本,并替换之, 所以, 我们需要使用类似于FiberSocket,FiberServerSocket等相应的类。此外,由于无法把三方库(比如JDBC)内部的阻塞API实现替换掉, 所以就产生了另一个问题: 协程库无法支持调用有阻塞API的三方库。
鉴于以上调研, 我们需要考虑在三方库和协程库之间做一定的取舍。
后端NIO的异步模式
业界还有一种是前后端都基于NIO的非阻塞模型,它的优点是前后端都用了异步,可以使得程序处理网络请求的过程中不发生任何的阻塞调用, 那么就可以以很少量的NIO回调线程来处理远大于线程数的请求量, 即使数据库的响应时间非常慢。
它的缺点是代码编写较为复杂,不够直观, 比如, 即使是非常简单的网络API调用如read(), 都需要注册回调函数来对其进行真正的数据处理. 因为read()函数返回时,数据还没有完全read完毕.
说明
异步能够使用少量线程(甚至单线程)的原因是, 调用网络API时(如read,write,close等),当前线程并不会等到API的操作真正完成才返回, 而是仅仅通知操作系统说我要执行网络操作了. 操作系统会自行处理. 等到操作系统真正的操作完成之后才执行回调.
即使这时数据库响应时间很慢, 仍然不会增加线程数.因为这两者已经没有了相关性. 而同步模型会使得大部分网络API阻塞当前线程,且如果数据库响应变慢,中间件性能也会成倍恶化,因为网络API阻塞的时间越长,中间件就会尝试建立更多的线程去调用本来已经很慢的阻塞API,放大了恶化的效果.
最终选型
在饿了么DAL的设计初期, 我们就预期到了未来流量成倍上涨的情况。我们的后端会4000+个数据库实例, 考虑到负载均衡和冗余, 每台DAL节点要能够代理400+个数据库实例, 必须把高性能作为技术选型的首要指标(并接受所带来的复杂性)。此外, 我们要期望选择的技术方案是成熟的,稳定的,业界有用它来做高并发服务端的先例。综上, 最终我们选择了基于Netty实现的前后端异步的编程模型。
Netty简介
Netty是目前Java业界使用比较广泛的异步网络通信库, 它具有以下一些优点:
- Netty基于Java原生的异步模型,封装并优化
- 修复(绕过)JDK中一些Bug
- 提供多种辅助类方便开发
- 编程模型简单且高效, 开发者只需关心具体实现逻辑即可
- 基本不用花精力做Java网络层面的优化
PS:
当然,任何库的优点都是局限于一定使用场景下的。比如当请求量提升5-10倍时,Netty库依然需要人工对其进行一定的调优,这点将在之后的另一篇技术分享中讲解。
Netty特性回顾
事件监听Listener模式
Netty的事件是通过事件监听的方式来进行处理的. 在这种模式下, 当事件被动触发之后, 会调用已经注册的回调函数来进行处理.
1// 连接成功事件 public void 2channelActive(ChannelHandlerContext ctx) throws Exception; 3// 读取事件 (接收数据事件) protected void 4decode(ChannelHandlerContext ctx, I msg, List out) ;5// 异常事件 public void 6exceptionCaught(ChannelHandlerContext ctx, Throwable cause) ;7// 自定义事件 public void 8userEventTriggered(ChannelHandlerContext ctx, Object evt);future模式
Netty的I/O操作则是通过future的方式来对其结果做处理的, 这也是Java非阻塞模型中比较关键, 也容易出错的一部分.
在Netty中,常见的主动式I/O操作,如bind()/connect()/flush()/write()/close(),并不阻塞,也不返回操作的结果, 而是返回一个异步回调的Future. 通过对于这个Future添加监听器, 来实现对这些I/O操作完成后的处理.
1/** * 2Request to connect to the given SocketAddress3 while bind to the localAddress and notify the * 4ChannelFuture once the operation completes, 5either because the operation was successful or because of * an error. */6 ChannelFuture connect(SocketAddress remoteAddress); 7ChannelFuture bind(SocketAddress localAddress); 8ChannelFuture close(); ChannelFuture write(Object msg);问题
但Netty的高性能仅仅是个开始, 异步编程复杂性所带来的问题也随之产生。
刚才已经提到, DAL作为数据库中间件,有前端客户端连接,也有后端数据库的连。为此, 我们启动了两个Netty的EventLoopGroup前后端分别进行处理. 它的架构大致是这样的:
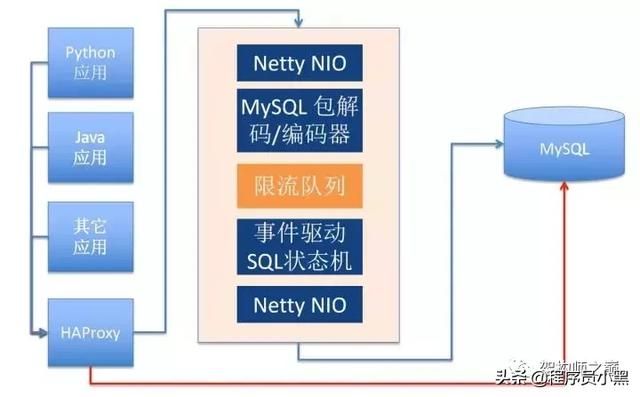
资源泄漏问题
在上线前的阶段, 我们对于DAL做了稳定性测试。
每隔一秒钟KILL所有后端数据库的连接, 来模拟在网络极端的情况下, DAL是否仍然能够稳定无错地运行。结果是, 在12小时的测试后,出现了资源的泄漏,即某些资源没有被正确地释放。而这种情况在没有一秒KILL的时候是不会发生的。
大致代码如下:
一个很简单的连接中断的处理函数quit()和一个消息处理函数handle(),在处理中,首先获取资源,结束后释放资源
1void quit() { if (conn != null) { // 1 2 conn.close(); // 2 3 conn = null; // 3 4 } } void handle() { if (conn != null) { // 4 try { 5 conn.acquireResource(); // 5 6 conn.execute(); // 6 7 } finally { 8 conn.releaseResource(); // 7 9 } 10 } }这样的代码在正常的逻辑里是没有问题的,收到请求后调用handle(),如果客户端发送quit命令,那么终止连接,一切OK。但是在异常情况,比如客户端意外中断连接, 或者后端数据库中断连接的情况下, 就会出现问题。
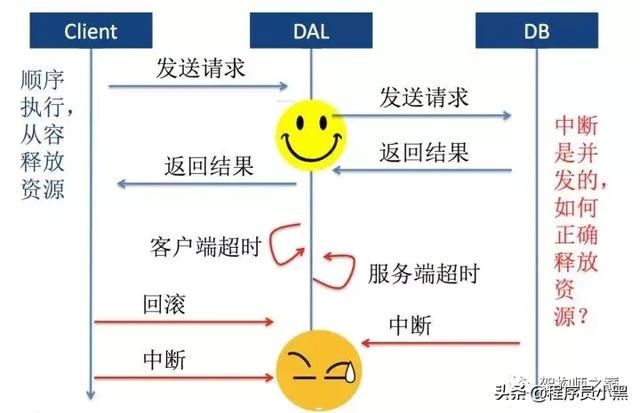
比如出现这种情况:
时间轴 : 此时conn不为null --> 线程B设置conn为null --> conn已经为null了线程A调用handle() : 执行4,5 --> --> 当执行6时,抛出异常,并执行7,但此时作为null的conn无法释放资源,导致资源泄漏线程B调用quit() : --> 接异常中断,执行到1,2,3 -->首先我们想到的解决方案是加锁, 在quit()和handle()方法加上synchronized关键字
这会有另一个问题: 那些没加锁的函数,依旧可能会出现空指针异常,有着资源泄漏的可能性.
或者干脆把所有的方法都加锁, 但这样会对性能造成一定的影响, 且看上去也是比较糟糕的设计。
还有一种方案则是在handle()方法里使用局部变量保存conn, 但它的不足之处在于,其他凡是使用conn的地方,都要使用这种方式,比较麻烦。
最后,我们联想到了Netty3.0升级到4.0时,它对于线程模型的优化[^3], 并把这种优化手段适配到了DAL的代码中。
方案: 串行化单个连接的处理
1// SQLConnectionContext.java 用于处理每个连接的类 static 2ExecutorService[] executors = new ThreadPoolExecutor[MAX_POOL_SIZE]; // 1 // 3IntStream.range(0, MAX_POOL_SIZE).forEach(i -> executors[i] = Executors.newSingleThreadExecutor()); // 2 private ExecutorService es = executors[random()]; // 3 void quit() { 4 Task task = new QuitTask(this); 5 es.submit(task); } void handle() { 6 Task task = HandleTask(this); 7 es.submit(task);8 }首先,我们不直接在Netty线程里执行业务逻辑的代码, 而是为每一个连接单独绑定了一个单线程的线程池, 如上述代码1,2,3所示。
其次我们把所有真正的逻辑处理代码都封装成为一个task, 任何的操作不是直接执行逻辑处理,而是生成一个task并放入这个单线程池。
如下图所示:
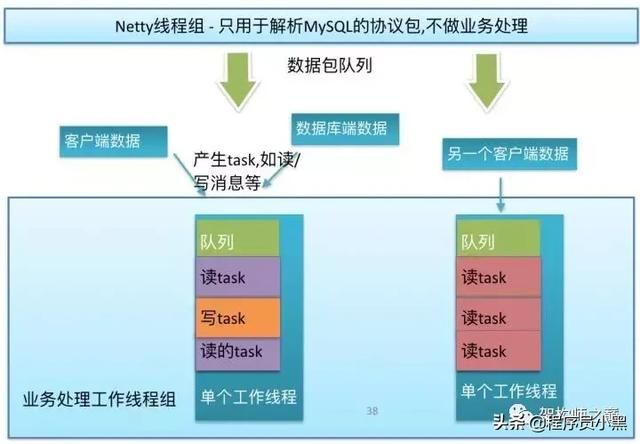
这样的好处在于, 这个连接上的任何业务逻辑, 如连接创建,中断,处理,异常等等, 都是由这个所绑定的单个线程所执行的, 一定是线程安全的。
对于数千个连接的并发请求, 它充分利用了多核多线程的特性来做并行处理对于具体到单个连接的所有事件, 它又是串行化处理的
这样的优化,使得业务逻辑的处理无需再关注多线程的问题, 较为完美地解决了异常中断时的资源泄漏问题。
反思
我们并没有通过更为精准地加锁来修复这个问题, 而是通过修改线程模型的方式直接绕过并去除了这个问题。因为代码里过多的lock/wait/notify不一定代表良好的多线程编程能力, 却可能代表这是不够优雅的设计。
阻塞并发量问题
数据库中间件有一个比较重要的功能是限流, 即: 最多只允许N条SQL同时执行, 比如: 并发量是4,但同时收到10条select sleep(1)的请求, 那么中间件会放行4条请求并转发到数据库, 然后让剩下的6个请求继续等待,直到一秒以后前4条请求执行OK,释放了4个信号量(类似于令牌),余下再继续放行4个请求. 说到限流, 我们首先想到的就是通过Java里自带的信号量来实现资源
1// class Semaphore in JDK 2/** * Acquires a permit from this semaphore, blocking until one is * available, or the thread is interrupted */3 public void acquire() throws InterruptedException;从文档中可以看到, 如果信号量不够,acquire()方法会阻塞当前线程.直到有其他线程release(),由于限流功能是基于数据库实例的, 即每个数据库实例的信号量功能彼此隔离无影响, 所以我们需要为每个实例单独分配一个Semaphore对象。那么限流功能的实现上就会遇到这样一个问题:
需要启动数据库实例数量的线程
刚才提到, 单节点DAL需要能够代理1k+的数据库实例, 所以就需要启动1k+个线程。虽然1k+线程数目在现代动辄几十核的物理机面前算不了什么, 但考虑到之前已经对DAL制定下高性能的目标, 单单为了限流而启动数以千计的线程一定会造成性能的损耗, 且这样简单粗暴的方案看上去也不是一种优雅的设计。此外, 考虑到未来的扩展性,DAL可能会单机代理所有10k+个数据库实例, 这样的情况下, 过多的线程数势必成为系统性能的瓶颈所在。
方案: 异步化信号量
同时是借鉴了NIO中让少数的几个线程单独监听事件的设计思路, 我们设计了一套类似的异步化信号量的方案:
// NIO Thread | | | NIOSelector =====> 事件放入EventLoopWorker线程处理 | | | --------------------------------- | | | | | | | | | Connection1 Connection2 Connection3// 异步化信号量 Thread | | | SemaphoreSelector =====> 事件放入EventLoopWorker线程处理 | | | --------------------------------- | | | | | | | | | | | |Semaphore1 Semaphore2 Semaphore3NIO的原理是用一个NIOSelector监听所有连接的事件, 而我们设计的异步化信号量也类似, 用一个SemaphoreSelector线程来监听所有信号量的事件, 当接收到事件之后, 会放入相应的工作线程里对其进行后续的处理。
于是,我们把原先的代码:
1// Semaphore semaphore = new Semaphore(10); 2try { 3 semaphore.acquire(); 4 doBusiness(); } finally { 5 semaphore.release(); 6}修改为:
1// AsyncSemaphore asyncSemaphore = new AsyncSemaphore(10); 2SemaphoreAcquiredCallback callback = () -> { 3doBusiness() 4}; 5asyncSemaphore.acquire(callbck); // 非阻塞调用 6// 线程在调用acquire()之后马上返回在实现内,我们会把这个SemaphoreAcquiredCallback放入一个队列中, 等待信号量管理器来做调度。这个管理器就是负责真正管理信号量acquire()和release()的逻辑实体。
示意图如下:
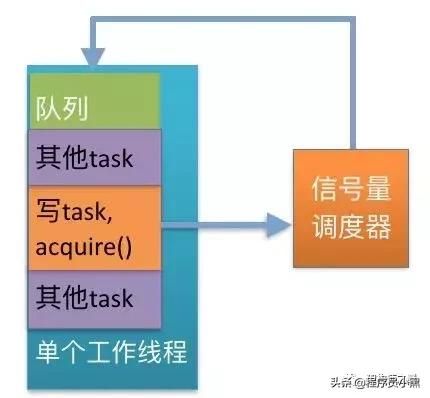
至此,我们通过这个中间的管理器解决了为每个数据库单独创建线程的问题。
反思
我们又一次从成熟技术(NIO)的理念中得到启发来解决当前设计架构上的问题.
其它
除了上述两点以外, 我们还在以下一些功能上实施了异步, 最终使系统真正实现了核心主逻辑上的无阻塞, 提高了性能
- 日志异步
- 心跳异步
- 定时job异步
- 配置变更异步
觉得文章不错的话,就赶紧关注小编吧,小编会每天问你分享有趣的技术文章,