后台组贾浩琛周报(2020.11.23-11.29)
学习内容简要
C语言进度
结构体与指针
浅尝链表
1.在刷题时学到的知识点
1.正则表达式
2.qsort函数
3.scanf函数的相关知识
2.对于上周内容的补充
1.tytpedef语句的相关知识
2.带参数的宏
3.指针与结构体
3.浅尝链表
4.洛谷部分题目题解和代码
一,在刷题时学到的知识点
1.正则表达式
使用正则表达式来匹配一段文本中的特定种类字符,是比较常用的一种方式
1.英文字母:[a-zA-Z]
2.数字:[0-9]
3.由数字、26个英文字母或者下划线组成的字符串^\w+$
4.
[A-Z a-z]+ 匹 配 由 26 个 英 文 字 母 组 成 的 字 符 串 [ A − Z ] + 匹配由26个英文字母组成的字符串 [A-Z]+ 匹配由26个英文字母组成的字符串[A−Z]+匹配由26个英文字母的大写组成的字符串
[a-z]+$匹配由26个英文字母的小写组成的字符串
2.qsort函数
qsort函数(全称quicksort)。它是ANSI C标准中提供的,其声明在stdlib.h文件中,是根据二分法写的,其时间复杂度为n*log(n)
功能: 使用快速排序例程进行排序
头文件:stdlib.h
用法:void qsort(void* base,size_t num,size_t width,int(__cdeclcompare)(const void,const void*));
参数:
1 待排序数组,排序之后的结果仍放在这个数组中
2 数组中待排序元素数量
3 各元素的占用空间大小(单位为字节)
4 指向函数的指针,用于确定排序的顺序(需要用户自定义一个比较函数)
1.qsort要求提供一个自己定义的比较函数。比较函数使得qsort通用性更好,有了比较函数qsort可以实现对数组、字符串、结构体等结构进行升序或降序排序。
2.如比较函数 int cmp(const void *a, const void *b) 中有两个元素作为参数(参数的格式不能变),返回一个int值,比较函数cmp的作用就是给qsort指明元素的大小是怎么比较的。
3.scanf函数
1.功能:接受用户从键盘中键入的数据,并按照格式控制符的要求进行类型转换,再送到地址表列中对应的变量存储单元。
2.一般形式:scanf(“输入格式串”,输入项地址表列);
3.返回类型:scanf函数返回成功读入的数据项数,读入数据时出现错误或者遇到了“文件结束”则返回EOF。
4.输入格式串:
| 格式串 | 含义 |
|---|---|
| %d | int |
| %ld | long int |
| %md | m为指定的输出字段的宽度 |
| %.nd | n为指定的输出实数的小数位 |
| %f | float |
| %lf | double |
| %o | 八进制int |
| %x | 十六进制int |
| %u | unsigned-无符号整型 |
| %lu | long unsigned-无符号整型 |
| %e | 以指数形式输出实数 |
| %g | 根据数值的大小,自动选f格式或e格式输出实数 |
| %c | char-一个字符 |
| %s | string-一个字符串 |
| %p | pointer-指针的值-十六进制整形,相当于0x%x,常用在变量地址的输出 |
| %[scanfset] | 功能见下方 |
5.scanf函数输入详解:
(1)用scanf函数输入字符串,以及scanf和gets函数的区别:
①char string[];scanf(“%s”,string);//输入字符串到字符数组,遇到回车键,Tab,空格输入结束。
②char string[];gets(string);//可以接收空格,tab,遇到回车键结束。
(2)scanfset 有两种形式:
①scanf(“%[bulabula~]”,str);//一种是以非 “^” 字符开头的 scanset , 表示在读入字符串时将匹配所有在 scanfset 中出现的字符,遇到非scanfset 中的字符时输入就结束;
②scanf(“%[^bulabula~]”,str);//另外一种形式是以 “^” 字符开头的scanfset ,表示在读入字符串时将匹配所有不在scanfset 中出现的字符,遇到scanfset 中的字符输入就结束。
比如:scanf(“%[^\n]”,str);//表示遇到回车键时字符串输入结束,可接收空格等特殊字符。
scanf函数在输入过程中如遇格式错误会立即停止输入。
二,对于上周内容的补充
1.对typedef语句内容的补充
typedef struct student STUDENT
可以如下定义
typedef struct student
{
int id;
char name[20];
char score[3];
float aver;
}STUDENT,*STU;
或
typedef struct
{
...
}STUDENT,*STU;
typedef语句和宏的区别
例如:
#define INTEGER int*
typedef int* INTEGER;
INTEGER a,b;
在此例中,宏定义和类型定义有着本质的区别:
宏定义可以理解为“int *a,b;”
类型定义可以理解为“int *a,int *b;”
宏定义句尾没有分号,若有分号,则分号也作为字符串的一部分被替换到程序中;而类型定义后面是有分号的。
2.带参数的宏
(1)像函数的宏
例如#define cube(x) ((x)*(x)*(x))
(2)带参数的宏的原则
1.一切都要带括号
2.整个值要括号
3.参数出现的每个地方都要括号
示例:
错误定义的宏
#define RADTOREG(x) (x*57.29578)
#define RADTOREG(x) (x)*57.25978
正确定义的宏
#define RADTOREG(x) ((x)*57.29578)
宏可以带多个参数,例如:
#define MIN(a,b) ((a)>(b)?(b):(a))
允许宏嵌套
带参数的宏在大型程序代码中使用普遍;可以非常复杂,如“产生”函数(在#和##的帮助下);
部分宏会被inline函数替代
3.指针与结构体
必须先定义结构体类型,再定义指向结构体类型数据的指针变量,在引用指针变量前,必须将已存在的结构体变量的地址赋给它,此时该地址变量的值即为该结构体变量的初始地址。例如
typedef struct student
{
int id;
char name[20];
int score;
}STUDENT,*STU;
STUDENT s,*p=&s;
结构体变量的引用有如下三种方法
1.结构体变量名.成员名
2.(*结构体指针变量名).成员名
3.结构体指针变量名->成员名
这样,可以使用以下三种方法访问结构体成员。在“p=&s;”的情况下它们是等价的
(1) s.name:使用结构体变量s访问结构体成员name
(2) (*p).name:使用结构体变量指针p访问结构体成员name
(3) p->name:使用结构体指针变量p访问结构体成员name
说明
(1)在(*p).name访问中,p两侧应加上小括号,因为.的优先级比的优先级高
(2)->由一个减号和一个大于号构成,含义是“指向结构体的”,称为指向成员运算符或指向分量运算符
指针变量也可以用来指向结构体数组中的元素,改变指针变量的值就可以通过它访问结构体数组中的各元素。
有如下程序示例
#include运行结果

在使用结构体指针时,应注意各种运算符的优先级和结合方向。其中,运算符->,.,(),[]的优先级最高。因此,一下语句的含义是:
(1) p->n++:引用p指向结构体变量中成员n的值,然后n自增。
(2) (p++)->n:引用p指向的结构体变量中成员n的值,然后p自增。
(3) ++p->n:使p指向的结构体变量中成员n的值先自增,再引用n的值。
(4) (++p)->n:使p的值自增,再引用p指向的结构体变量中成员n的值。
用指向结构体的指针做函数参数
三,浅尝链表
1.存储空间的分配和使用
c语言标准函数库提供了四个函数,用来实现内存的动态分配与释放
malloc()
calloc()
realloc()
free()
前三个用于动态存储分配,第四个涉及动态存储释放,最常用的是malloc函数和free函数。
这四个函数的原型说明在stdlib.h头文件和alloc.h头文件中。
(1).函数malloc()–动态分布一段内存空间
malloc()函数的原型是void *malloc(unsigned int size);
其功能是在内存的动态存储区中申请一个长度为size字节的连续存储空。malloc函数会返回一个指针并指向所分配存储空间的起始地址。如果没有足够的内存空间可分配,则会返回空指针NULL。
说明:函数值为指针类型,由于基类型是void,因此如果要把这个指针值赋给其他类型指针变量,应进行相应的强制类型转换。
malloc函数的参数中 经常使用C语言提供的运算符sizeof(),通过它来计算申请空间的大小。不同机器中同一类型所占字节可能不同,所以用sizeof可以使程序适应不同的机器,便于程序的移植。例如:
int *p=(int *)malloc(sizeof(int));
申请一个int型长度的存储空间,并将其分配到的存储空间地址转化为int 类型地址,再赋给所定义的指针变量p,基类型字节数为int型所占的空间为2或4(因机器而异)。再例如:
struct stud *p=(struct stud*)malloc(sizeof(struct stud));
申请可存放struct stud结构体类型数据的空间,并将其地址存入指针p中,当struct stud结构体类型的定义改变时,申请空间的大小也会随之而变,程序的适应性增强。
下面是一个使用malloc函数动态分配空间的示例
#include在该程序中,使用malloc函数分配了内存空间,通过指向该内存空间的指针,使用该空间保存数据,最后显示该数据,表示保存数据成功。程序的运行结果为100。
(2).函数calloc()–动态分配连续内存空间
calloc()函数的原型是void*calloc(unsigned int n,unsigned int size);
其功能是在内存内申请n个长度为size字节的存储空间,并返回该存储空间的起始地址。如果没有足够的内存空间可分配,则函数返回值为空指针NULL。该函数主要用于动态数组申请存储空间,n为元素的个数,size为元素存储长度。例如:
int *p=(int *)calloc(10,sizeof(int));
该语句的含义为申请10个int类型长度的存储空间,并将分配到的存储空间地址转换为int类型地址,并将其首地址赋给所定义的指针变量p。此后就可以将p作为10个元素的整型数组来使用,此数组没有数组名,只能用指针变量p来访问。该语句的功能也可以用malloc()函数来实现:int *p=(int *)malloc(sizeof(int *10));
下面是一个用calloc分配数组内存的例子
#include(3).函数realloc()–改变指针指向空间的大小
realloc函数的原型为void *realloc(void *ptr,size_t size);
其功能是改变ptr指针指向大小为size的空间。设定size的大小可以是任意的,也就是说可以比原来的数值大,也可以比原来的数值小。返回值是一个指向新地址的指针,如果出现错误,则返回NULL。例如,改变一个浮点型空间大小为整型大小,代码如下:
double *p=(double *)malloc(sizeof(double));
int *q=realloc(p,sizeof(int));
其中,p是指向分配的浮点型空间,然后使用realloc函数改变p指向空间的大小,其大小设置为整形,然后将改变后的内存空间的地址返回赋值给q指针。如下代码使用realloc函数重新分配内存。
#include说明
%p格式输出的是指针本身的值,也就是指针指向的地址值。该输出为16进制形式,具体输出值取决于指针指向的实际地址值。
该程序运行结果为

(4).free()–释放存储空间
free()函数原型为void free (void *p)
其功能是将指针变量p指向的存储空间释放,交还给系统。无返回值。
说明:
p只能是程序中此前最后一次调用malloc或者calloc函数所返回的地址。
例如:
int *p,*q=(int *)malloc(10*sizeof(int));
p=q;
q++;
free(p);//将p指向的,此前调用malloc函数申请的存储地址释放
如果改用free(q)则会报错,因为执行q++后,q已经改变。
以下代码为使用free函数释放内存空间的示例
#include运行结果为
![]()
2.链式存储结构----链表
定义:链表是一种采用动态存储分配方式的数据结构。使用动态数组存放数据时可以根据实际元素个数动态调整数组大小,但分配的存储空间必须是连续的,并且在插入或者删除等操作过程中涉及到大量元素的移动。
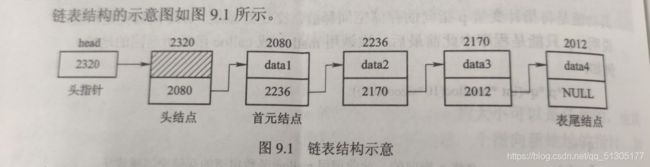
在链表中,有一个头指针变量(图9.1中的head),用这个指针变量保存一个地址。从图中箭头可知,该地址为一个变量的地址,也就是说头指针指向一个变量,这个变量称为元素。在链表中,每个元素包括两部分:数据部分和指针部分。数据部分用来存放元素所包含的数据,指针部分用来指向下一个元素。最后一个元素的指针指向NULL,表示指向的地址为空。
在链表中,第一个节点前虚加一个头节点,头指针指向头节点,头结点的指针指向第一个实际有效节点,该节点称为首元节点。头节点的数据域可以不使用。对带头结点的链表,空表还保留着头节点。带头结点的链表比不带头节点的链表在创建,插入和删除等操作时代码更简洁。
(1).动态链表:链表中节点的分配和回收都是动态的
(2).静态链表:把线性表的元素存放在数组中,且每个元素除了存放数据信息外,还要存放下一个元素的位置,即下一个元素所在的数组单元的下标。静态链表虽然是采用数组实现的,但这些元素在物理上可能是连续存放的,也可能不是连续的,它们之间通过逻辑关系来连接。
静态链表的结构定义如下:
#define Maxsize 10
typedef int Datatype;
typedef struct SNode
{
Datatype data;
int next;//游标cursor
}Snode,StaticList[Maxsize+1];

3.单链表
如果在链表中,每个结点只有一个指针,所有结点都单线连接,除了末尾指结点指针为空外,每个结点都指向下一个结点,一环扣一环形成一条线性链,称此链表为单向线性链表或简称单链表。
单链表的特点:
(1).有一个head指针变量,它存放头结点的地址,称之为头指针
(2).头结点的指针域head->next,存放首元结点的地址
(3).每个结点都包含一个数据域和一个指针域,数据域存放用户需要的实际数据,指针域存放着下一个结点的地址。从头指针head开始,head指向头结点,头结点指向首元节点,首元节点指向第二个结点,…,直到最后一个结点。所有结点都是单线联系环环相扣。
(4).最后一个结点不再指向其他结点,称为“表尾结点”,其指针域为空指针“NULL”,表示链表到此结束。指向表尾结点的指针称为尾指针。
(5).链表各结点之间的顺序关系由指针next来确定,并不要求逻辑上相邻的结点在物理上也相邻,也就是说,链表依靠指针相连并不需要占用一片连续的内存空间。
(6).随着处理数据量的增加,链表可以不受程序中变量定义的限制无限的延长(仅受内存总量的限制)。在插入和删除操作中,只需修改相关结点指针域的链接关系,不需要像数组那样大量地改变数据的实际存储位置。链表的使用,使程序的内存利用率和时间效率大大提高。
(1)单链表的初始化
由于链表的每个结点都包含数据域和指针域,即每个结点都要包含不同类型的数据,所以结点的数据类型必须选用结构体类型。该类型可以包括多个类型成员,必须有一个成员的类型是指向本结构体类型的指针类型。对于这种结构体类型,允许递归定义。
例如,创建一个链表表示一个班级,结点表示学生,它的结点结构体类型定义如下:
typedef struct node
{
char name[20];
int number;
struct node *next;//next的类型是指向本结构体类型的指针类型
}Node,*LinkList;
其中,Node是结构体类型,LinkList是结构体指针类型。LinkList head 相当于Node *head,也相当于struct node *head。
单链表的初始化就是创建一个头结点,头结点的数据域可以不使用,头结点的指针域为空,表示空单链表,如图
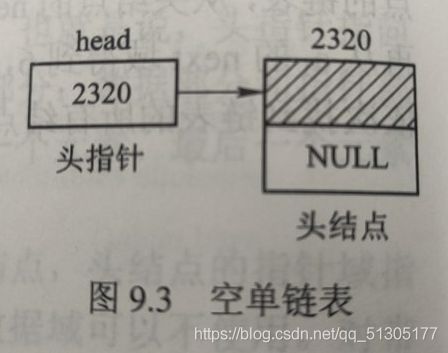
单链表初始化代码如下:
LinkList InitList()
{
LinkList head;//定义头指针变量
head=(Node *)malloc(sizeof(Node));//头指针指向分配的头结点内存空间
head->next=NULL;//头结点的指针域为空
return head;//返回头结点的地址,即头指针
}
(2)单链表的建立
尾插法:在单链表尾部插入新结点建议单链表。从一个空表开始重复度人数据,生成新结点,将读入数据存放到新结点的数据域,然后将新结点插入到当前的表尾,直到读入结束标志为止。增加一个指针来始终指向链表的最后一个结点,以便插入新的结点。数据读入顺序和链表的节点顺序完全一样。
尾插法建立单链表代码如下:
void CreatByRear(LinkList head)
{
Node *r,*s;
char name[20];
int number;
r=head;//r指向头结点
printf("请输入姓名和学号:\n");
while(1)
{
scanf("%s",name);
scanf("%d",number);
if(number==0)
{
break;
}
s=(Node *)malloc(sizeof(Node));//分配结点的内存空间
strcpy(s->name,name);
s->number=number;
r->next=s;//原来的结点指向新结点
r=s;//r指向新结点
}
r->next=NULL;//链表的尾结点指针为空
}
CreatByRear函数的功能是创建链表,在该函数中首先定义需要用的指针变量r和s,r指向当前链表的表尾结点,s指向新创建的结点。
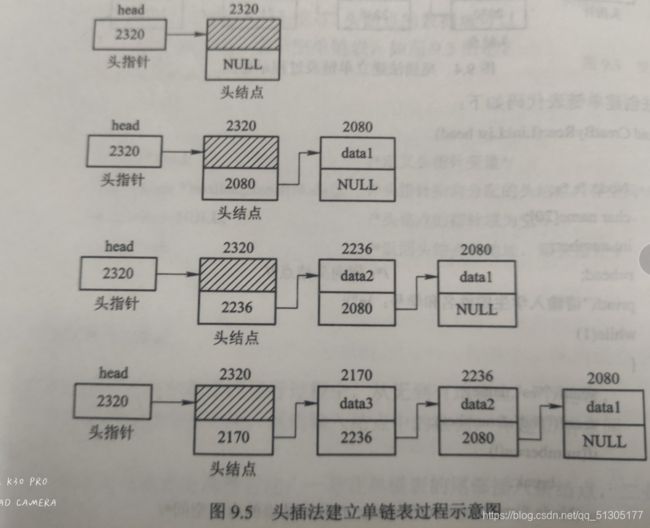
头插法:在单链表头部插入新结点建立单链表。从一个空表开始,重复度人数据,生成新结点,将读入数据存放到新结点的数据域中,然后把新结点插入到当前链表的表头结点之后,直至读入结束标志为止。数据读入顺序和链表的结点顺序相反。