⚡【图像描述】Show and Tell: A Neural Image Caption Generator
更新进度:■■■■■□□□□□□□□□□□□□□□|30%
目录
- ==参考课程==
- ==参考项目==
- ==基本理论==
-
- 1. one-hot编码:
- 2. keras的flow方法:
- 3. 端到端学习
- 4. keras.callbacks 回调函数
- 5. fit_generator
- 6. 自然语言评价标准
- 7. 使用Keras画流程图
- 8. LSTM原理
- 9.yield
- ==程序实现==
-
- 程序流程
- 程序:
-
- 数据预处理(Flickr8k)
-
- 图像预处理:
- caption预处理:
- 创建词汇表:
- 图像特征提取:
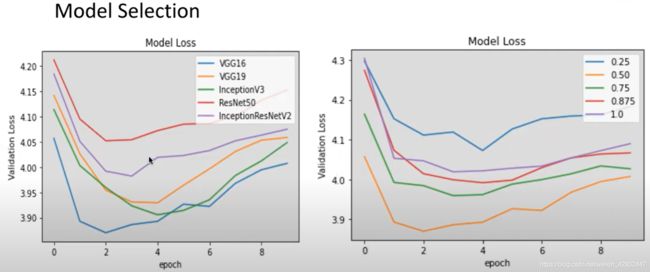
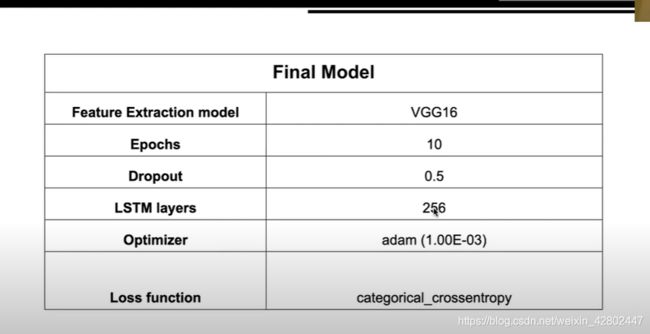
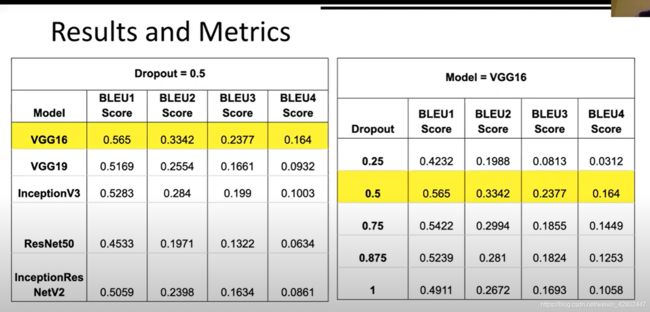
- 模型选择:
参考课程
刚开始接触搜索image caption怎么都找不到资料,后来发现可以搜索image captioning,图像描述,看图说话,照片字幕这一类的词汇也可以找到想要的资料。
到2020年底,目测博客园中写图像描述的博主更多一点。
斯坦福cs231n计算机视觉——RNN , LSTM 资料
CS231n Winter 2016: Lecture 10: Recurrent Neural Networks, Image Captioning
参考项目
完成 coco 数据集上的 image caption 小项目
youtube pytorch image caption
参考项目
Develop an image captioning deep learning model using Flickr 8K data
如何从头开始开发深度学习照片字幕生成器
keras项目
教你用PyTorch实现“看图说话”(附代码,学习资源)
基本理论
1. one-hot编码:
将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,其表示分别是x_1 = (1), x_2 = (2), x_3 = (3)。两个工作之间的距离是,(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2。那么x_1和x_3工作之间就越不相似吗?显然这样的表示,计算出来的特征的距离是不合理。那如果使用one-hot编码,则得到x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1),那么两个工作之间的距离就都是sqrt(2).即每两个工作之间的距离是一样的,显得更合理。
转换成二进制
2. keras的flow方法:
ImageDataGenerator.flow
def flow(self, x,y=None, batch_size=32, shuffle=True,sample_weight=None, seed=None,save_to_dir=None, save_prefix='', save_format='png', subset=None)
x: 输入数据。秩为 4 的 Numpy 矩阵或元组。
如果是元组,第一个元素应该包含图像,第二个元素是另一个 Numpy 数组或一列 Numpy 数组,它们不经过任何修改就传递给输出。可用于将模型杂项数据与图像一起输入。对于灰度数据,图像数组的通道轴的值应该为 1,而对于 RGB 数据,其值应该为 3。
y: 标签。
batch_size: 整数 (默认为 32)。
shuffle: 布尔值 (默认为 True)。
sample_weight: 样本权重。
seed: 整数(默认为 None)。
save_to_dir: None 或 字符串(默认为 None)。这使您可以选择指定要保存的正在生成的增强图片的目录(用于可视化您正在执行的操作)。
save_prefix: 字符串(默认 '')。保存图片的文件名前缀(仅当 save_to_dir 设置时可用)。
save_format: "png", "jpeg" 之一(仅当 save_to_dir 设置时可用)。默认:"png"。
subset: 数据子集 ("training" 或 "validation"),如果 在 ImageDataGenerator 中设置了 validation_split。
返回:
一个生成元组 (x, y) 的 Iterator,其中
x 是图像数据的 Numpy 数组(在单张图像输入时),或 Numpy 数组列表(在额外多个输入时),
y 是对应的标签的 Numpy 数组。
如果 'sample_weight' 不是 None,生成的元组形式为 (x, y, sample_weight)。如果 y 是 None, 只有 Numpy 数组 x 被返回
3. 端到端学习
端到端是由输入端的数据直接得到输出端的结果
4. keras.callbacks 回调函数
CSVLogger (filename, separator=’,’, append=False)
- filename:csv 文件的文件名,例如 ‘run/log.csv’。
- separator:用来隔离 csv 文件中元素的字符串。
- append:True:如果文件存在则增加(可以被用于继续训练)。False:覆盖存在的文件。
- 输出:把训练轮结果数据流到 csv 文件的回调函数
ModelCheckpoint (filepath, monitor=‘val_loss’, verbose=0, save_best_only=False, save_weights_only=False, mode=‘auto’, period=1)
- filepath: 字符串,保存模型的路径。
- monitor: 被监测的数据。
- verbose: 详细信息模式,0 或者 1 。
- save_best_only: 如果 save_best_only=True, 被监测数据的最佳模型就不会被覆盖。
mode: {auto, min, max} 的其中之一。 如果save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。 在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。- save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。
- period: 每个检查点之间的间隔(训练轮数)。
- 输出:在每个训练期之后保存模型。
keras ModelCheckpoint 实现断点续训功能
ReduceLROnPlateau (monitor=‘val_loss’, factor=0.1, patience=10, verbose=0, mode=‘auto’, min_delta=0.0001, cooldown=0, min_lr=0)
- monitor: 被监测的数据。
- factor: 学习速率被降低的因数。新的学习速率 = 学习速率 * 因数
- patience: 没有进步的训练轮数,在这之后训练速率会被降低。
- verbose: 整数。0:安静,1:更新信息。
- mode: {auto, min, max} 其中之一。如果是 min 模式,学习速率会被降低如果被监测的数据已经停止下降; 在 max 模式,学习塑料会被降低如果被监测的数据已经停止上升; 在 auto 模式,方向会被从被监测的数据中自动推断出来。
- min_delta: 对于测量新的最优化的阀值,只关注巨大的改变。
- cooldown: 在学习速率被降低之后,重新恢复正常操作之前等待的训练轮数量。
- min_lr: 学习速率的下边界。
- 输出:当标准评估停止提升时,降低学习速率。
EarlyStopping等都是keras的回调函数,用来观察训练结果。
5. fit_generator
fit_generator ( generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)
- generator:一个生成器,或者一个 Sequence (keras.utils.Sequence) 对象的实例。这是我们实现的重点,后面会着介绍生成器和sequence的两种实现方式。
- steps_per_epoch:这个是我们在每个epoch中需要执行多少次生成器来生产数据,fit_generator函数没有batch_size这个参数,是通过steps_per_epoch来实现的,每次生产的数据就是一个batch,因此steps_per_epoch的值我们通过会设为(样本数/batch_size)。如果我们的generator是sequence类型,那么这个参数是可选的,默认使用len(generator) 。
- epochs:即我们训练的迭代次数。
- verbose:0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行
- callbacks:在训练时调用的一系列回调函数。
- validation_data:和我们的generator类似,只是这个使用于验证的,不参与训练。
-validation_steps:和前面的steps_per_epoch类似。
-class_weight:可选的将类索引(整数)映射到权重(浮点)值的字典,用于加权损失函数(仅在训练期间)。 这可以用来告诉模型「更多地关注」来自代表性不足的类的样本。(感觉这个参数用的比较少)
-max_queue_size:整数。生成器队列的最大尺寸。默认为10.
-workers:整数。使用的最大进程数量,如果使用基于进程的多线程。 如未指定,workers 将默认为 1。如果为 0,将在主线程上执行生成器。
-use_multiprocessing:布尔值。如果 True,则使用基于进程的多线程。默认为False。
-shuffle:是否在每轮迭代之前打乱 batch 的顺序。 只能与Sequence(keras.utils.Sequence) 实例同用。
-initial_epoch: 开始训练的轮次(有助于恢复之前的训练)
model.fit_generator()函数参数
6. 自然语言评价标准
论文以人工审查为主,BLEU标准为辅
实际上在做的事:判断两个句子的相似程度。我想知道一个句子翻译前后的表示是否意思一致,显然没法直接比较,那我就拿这个句子的标准人工翻译与我的机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。因此,BLUE去做判断:一句机器翻译的话与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。(注:BLEU算法是句子之间的比较,不是词组,也不是段落)
自然语言中的评价指标
NIC《Show and Tell: A Neural Image Caption Generator》

7. 使用Keras画流程图
from keras.utils import plot_model
plot_model(NIC_model, to_file='./model.png',show_shapes=True)
8. LSTM原理
【自然语言处理基础知识】LSTM
9.yield
python中yield的用法详解——最简单,最清晰的解释
程序实现
程序流程
- 预处理flickr8k数据
- 提取描述
- train_captions
- dev_captions
- test_captions
- 对描述进行编码(训练集,验证/开发/测试集分别构建)
- 构建词汇表 vocab
- 构建词汇表字典 每个单词对应一个索引 idx_to_word word_to_idx
- 对描述编码 encode_caption
- 对描述解码 decode_caption
- 描述正确性指标
- 预处理flickr图片
- 构建经典的CNN网络
- vgg-16
- vgg-19
- google net inception v3
- resNet
- 构建经典的CNN网络
- 使用构建的网络来预训练图片(都是采用才imagenet上得到的权重)
- 获得和保存图片对应的特征(vgg-16为例是4096维的特征)
-train_features- dev_features
- test_features
- 图片地址(数据集已经下载到本地,也可以是网络url)
- train_urls
- dev_urls
- test_urls
- 获得和保存图片对应的特征(vgg-16为例是4096维的特征)
- 提取描述
- 构建ImageCaptioning模型
- NIC: CNN编码+LSTM解码网络结构
- 正向传播
- 反向传播
- 计算loss,计算正确率
- 采用SGD, ADAM等更新权重参数
- 测试模型
- 对测试集运用训练好的模型
- 评价模型准确度
- 比较几种不同的网络和参数对于模型准确度的影响,并分析原因,反过来验证猜想,如此往复
程序:
数据预处理(Flickr8k)
定义一个预处理的类Preprocess():
- w2v_path:word2vec的存储路径
- sentences:句子
- sen_len:句子的固定长度
- idx2word 是一个列表,比如:self.idx2word[1] = ‘he’
- word2idx 是一个字典,记录单词在 idx2word 中的下标,比如:self.word2idx[‘he’] = 1
- embedding_matrix 是一个列表,记录词嵌入的向量,比如:self.embedding_matrix[1] = ‘he’ vector
对于句子,我们就可以通过 embedding_matrix[word2idx[‘he’] ] 找到 ‘he’ 的词嵌入向量。
Preprocess()的调用如下:
- 训练模型:preprocess = Preprocess(train_x, sen_len, w2v_path=w2v_path)
- 测试模型:preprocess = Preprocess(test_x, sen_len, w2v_path=w2v_path)
另外,这里除了出现在 train_x 和 test_x 中的单词外,还需要两个单词(或者叫特殊符号):
- “”:Padding的缩写,把所有句子都变成一样长度时,需要用""补上空白符
- “”:Unknown的缩写,凡是在 train_x 和 test_x 中没有出现过的单词,都用""来表示
图像预处理:
import os
import pickle
FLICKR8K_BASE = "./Datasets/Flickr8k/" # 本地地址
FLICKR8K_DATASET = os.path.join(FLICKR8K_BASE,"Flicker8k_Dataset") # 数据集图像
FLICKR8K_TEXT = os.path.join(FLICKR8K_BASE, "Flickr8k_text") # 数据集文本信息
flick8k_train_images = os.path.join(FLICKR8K_TEXT, "Flickr_8k.trainImages.txt")
flick8k_test_images = os.path.join(FLICKR8K_TEXT, "Flickr_8k.testImages.txt")
flick8k_dev_images = os.path.join(FLICKR8K_TEXT, "Flickr_8k.devImages.txt")
def get_images_filenames(filename, dataset_folder=FLICKR8K_DATASET) :
images_filenames = []
images_urls = []
with open(filename, 'r') as f :
for i, line in enumerate(f) :
#image_file_name = line.strip().split('\n')
image_file_name = line.strip()
image_url = os.path.join(dataset_folder, image_file_name)
images_filenames.append(image_file_name)
images_urls.append(image_url)
return images_filenames, images_urls
train_images_filenames,train_images_urls = get_images_filenames(flick8k_train_images, 'train')
dev_images_filenames,dev_images_urls = get_images_filenames(flick8k_dev_images,'dev')
test_images_filenames,test_images_urls = get_images_filenames(flick8k_test_images,'test')
caption预处理:
import pickle
import os
from variate import FLICKR8K_DATASET,flick8k_token
# 提取描述,对描述进行编码,创建字典保存为pickle文件
def get_all_captions_dict(filename, dataset_folder=FLICKR8K_DATASET) :
captions_dict = {
}
try :
with open(filename, 'r') as f:
print(filename)
for i, line in enumerate(f):
tmp_list = line.strip().split('\t')
tmp_list[0] = tmp_list[0][:-2]
#images_urls.append( image_url )
if tmp_list[0] in captions_dict:
captions_dict[tmp_list[0]]['captions'].append(tmp_list[1])
else :
captions_dict[tmp_list[0]] = {
}
captions_dict[tmp_list[0]]['captions'] = [tmp_list[1]]
image_url = os.path.join(dataset_folder, tmp_list[0])
captions_dict[tmp_list[0]]['url'] = image_url
except Exception as e:
print('Error: ', e)
return captions_dict
all_captions_dict = get_all_captions_dict(flick8k_token)
#建一个文件夹,.pyc文件会自动保存下来
try:
with open('save/all_captions_dict.pyc', 'wb') as save_all_captions_dict:
pickle.dump(all_captions_dict, save_all_captions_dict)
except Exception as e:
print('Error: ',e)
创建词汇表:
import pickle
from caption_预处理 import all_captions_dict
from piture_预处理 import train_images_filenames, dev_images_filenames, test_images_filenames
def get_captions_words(images_filenames, all_captions_dict, verbose_name='train', up_low=False) :
"""
对于给定的images_filenames数组,获得全部的描述所构成的词汇表
"""
tokens = ['' , '' , '' , '' ] # 为了编码还有解码的方便
total_words = []
total_unique_words = set()
idx_to_word = []
image_types = {
'train', 'dev', 'test'} # warring改了
if verbose_name not in image_types:
return idx_to_word
for image_filename in images_filenames:
image_captions = all_captions_dict[image_filename]['captions']
for image_caption in image_captions:
image_caption_words = image_caption.split()
for caption_word in image_caption_words :
if not up_low:
caption_word = caption_word.lower() # 不要分大小写,一律小写
total_words.append(caption_word)
total_unique_words = set(total_words)
idx_to_word = tokens + list(total_unique_words)
return idx_to_word
train_idx_to_word = get_captions_words(train_images_filenames, all_captions_dict, 'train', up_low=True)
train_word_to_idx = {
v:i for i, v in enumerate(train_idx_to_word) }
#存储三个数据库的词汇表
with open('save/train_idx_to_word.pyc', 'wb') as save_train_idx_to_word:
pickle.dump(train_idx_to_word, save_train_idx_to_word)
with open('save/train_word_to_idx.pyc', 'wb') as f:
pickle.dump(train_word_to_idx, f)
图像特征提取:
模型选择: