sql 使用一个表的两个字段做条件_写给产品运营等非技术同学的SQL教程

前言
本篇文章的主要目的是帮助初学者快速入门SQL查询,从而解决实际业务中80%的SQL查询问题。早先时候写给产品经理的女朋友用于取数写用户分析报告的,近期抽空补充了一些用例。
本文主要框架如下:
- 上篇:介绍
SQL的语法顺序和执行顺序 - 中篇:介绍条件子句、分组查询和排序的细节
- 下篇:表的连接和其他常用关键字
希望学完这三篇后能助你系统地入门SQL。
快速上手SQL的常用语法
1. 通过单表查询逐步理解SQL语法
学生表student结构:

先看一个查询例子:
查询表中所有学号小于
8的男学生的学号和姓名:
select
sid, sname # 需要查询出来的字段
from student # 从哪张表中取数
where ssex = '男' and sid < 8 # 设置查询的条件, 两个条件用and(和)/or(或)连接暂时我们没有对字段做处理,如果你需要对选择出来的结果进行处理,需要使用函数和order by,再看一个例子:
查询每个男学生的学号、姓名和年龄,并按照学号降序排列
select
sid, sname
, (curdate())-year(sage) as age #当前年份减去出生年份得到年龄
from student
where ssex = '男'
order by sid desc # order by表示按照字段排序, desc表示降序其他常用的函数和where条件:
查询学号非空,姓“张”的学生,按照
sid升序并取前三条
select
sid, sname
from student
where sname like '张%' # 通过like和通配符%进行模糊匹配
and sid is not null # 学号非空
order by sid
limit 3 # 只取前三条2.多表查询
学生表student:
成绩表sc:

通过join连接两张表:
查询赵雷每门课的成绩
select
sname, cid, score
from student
inner join sc
on student.sid = sc.sid # 两张表的连接条件,满足条件的两行会并为一行
where sc.sname = '赵雷'本文用到数据库表
为方便学习,我们继续使用之前用到的学生表student和成绩表sc,为了模拟业务中复杂的查询任务,我们再引入课程表course和教师表teacher。
笔者寄语:熟练使用
SQL的前提一定是先了解你的数据库表,现在花点时间看看这四张表的字段信息(描述每个字段的意义)和数据样例(给出部分真实数据),关于业务中用到的表结构可以找数据小哥拿。
1.字段信息
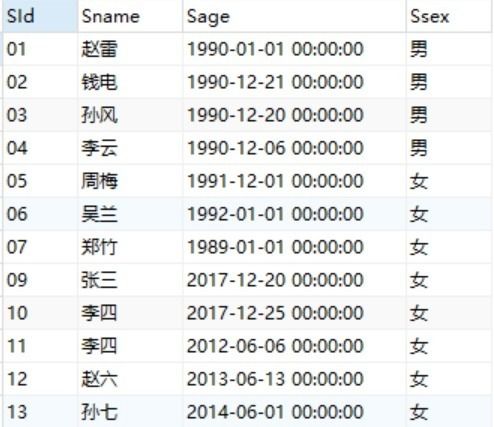
学生表:
Student(SId,Sname,Sage,Ssex)
SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别课程表:
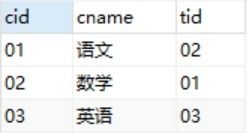
Course(CId,Cname,TId)
CId 课程编号,Cname 课程名称,TId 教师编号教师表:
Teacher(TId,Tname)
TId 教师编号,Tname 教师姓名成绩表:
SC(SId,CId,score)
SId 学生编号,CId 课程编号,score 分数2. 数据样例
学生表:
课程表:
教师表:

成绩表:

SQL的执行顺序与语法顺序
本篇文章关于SQL语法的部分会讲到条件子句(where子句)、分组查询(group by子句和having子句)、结果呈现(order by和limit)和连接查询(left/right/inner join)。
看到这你可能会瞬间头大,但是由于SQL语言是有执行优先级的,这给了我们分块讲解的机会,私以为这也是SQL语言易学的重要原因。
为了解释清楚SQL语言的执行顺序和语法顺序,让我们先看看下面这个Hive单表查询的完整结构:

任何一个单表查询的SQL都可以分解成上述格式,实际上抽象化后的多表连接查询也可以分解成如上格式。从上到下是SQL的语法顺序(即你书写SQL的格式),而SQL真实的执行顺序如下:

笔者寄语:举个简单的例子加深理解,SQL的语法顺序就像小说的插叙,而SQL真正的执行顺序就是小说的时间顺序。
通过一个实例复习SQL的执行顺序
上面的讲解可能让你一知半解,在正式介绍各部分SQL语法前我们先通过一个实例复习上面SQL的执行顺序。
例如,有这么一个业务查询任务:
在限定学生表学号小于等于6的一批学生中,查询每门课的最高成绩(最高成绩低于70分的课程不显示),然后根据课程最高成绩降序排列取前两条记录。查询的SQL如下:
select
cid # 课程号
, max(score) as max_score # 最高分
from sc # 成绩表
where sid <= 6
group by cid
having max(score) >= 70
order by max(score)
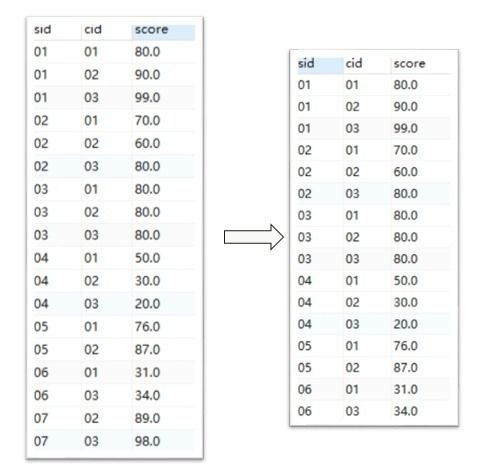
limit 2; # 只展示前两条数据为方便阅读,下面列出被查询的成绩表sc和查询后的结果:

1.条件子句——为被查询的表增加限制条件
where sid <=6限制只查询学号小于等于6的学生成绩
2.分组查询——实现聚合(group by + 聚合函数)限制聚合条件(having)
如果用过数据透视表的话应该比较容易理解分组查询的概念,分组查询一般和聚合函数一起实现,例如查看每个班的平均成绩、查看每个学生的最高成绩或者查看每个班的最低成绩等分组信息。
我们仍然用直观的数据变化来展示分组查询:
group by cid按照课程分组查看每门课的聚合信息max(score)搭配group by子句使用的聚合函数,表示每门课的最高成绩having max(score) >=70对分组后的结果筛选,选取最高成绩>=70的课程

3.字段选择——select
在group by分组后紧跟着我们会选择需要呈现的字段,为了方便讲解,其实分组查询中呈现的图片已经是select的结果了。
4.结果呈现——排序(order by)和限制条数(limit)
order by和limit都是为了修改最终呈现结果。order by首先执行,按照某个字段进行排序(desc 关键字表示降序),这部分和excel的排序很相似。最后我们使用limit来修改结果展示的条数。

介绍各个字句的细节
一、条件子句(where)
- 比较运算符(适用于区间)
比较运算符包括=(等于),>=(大于等于),<=(小于等于),!=(不等于),>(大于),<(小于)。比如查询年龄小于30的学生:
where sage < 30- 确定范围(适用于连续范围)
between … and …为取值限定了一个范围。例如:查询年龄大于等于10小于等于20的学生:
where sage between 10 and 20- 确定集合(适用于离散的少数值)
例如:插入年龄为10,20,30的学生:
where sage in (10,20,30)
# in可以和not一起使用,表示不在这个区间的值
where sage not in (10,20,30)- 字符匹配(模糊查询)
通过like关键字和正则表达式匹配,常用的通配符有%(任意个字符)和_(一个字符)。例如:查询名字sname带“王”的学生:
where sname like “%王%”- 判断是否为空值
通过is null关键字判断值是否为空。例如:查询姓名sname不为空的学生:
where sname is not null- 多个查询条件
用and(两个条件同时满足)和or(两个条件满足一个即可)。例如:查询年龄sage小于20且性别ssex为男的学生:
where sage < 20 and ssex = '男'二、分组查询(group by&聚合函数&having子句)
分组查询实现了类似excel中数据透视表的功能,可以帮助我们对数据进行分层汇总,而我们对分层后的数据进行统计的时候需要用到聚合函数(也就是平均值、求和、最大值和最小值等),最后我们对分层之后的数据筛选的时候需要用到having子句。
where子句是对原始表做筛选的having子句是对分层汇总之后的结果做筛选的
回顾我们上一篇讲过的例子:在限定学生表学号小于等于6的一批学生中,查询每门课的最高成绩(最高成绩低于70分的课程不显示),然后根据课程最高成绩降序排列取前两条记录。
select
cid
,max(score) as max_score
from sc
where sid <= 6
group by cid
having max(score) >= 70
order by max(score)
limit 2;回顾一下执行顺序,首先我们用where子句对原始数据做了学号id需要小于等于6的限制。然后我们用group by和max(score)聚合函数实现了对课程进行分层,求出每门课的最高成绩,为了对聚合之后的结果作限制,我们用having子句只展示最高分数大于等于70的记录。
关于这个例子详细解释可以回顾上篇文章,下面我们详细介绍每个部分的常用语句。
group by
group by不仅可以对一个字段进行分组,还能对多个字段进行分组。这和excel中的数据透视表一致。
- 聚合函数

having子句
和where子句一致,只需注意是对聚合后的结果作限制。
三、字段选择(select)
select比较灵活,我们不单单能选择原始数据表的字段,还能使用函数对字段进行计算,正如我们第一篇提到的,函数并不是重点,当你需要的时候百度或者问技术小哥就知道了。我们这里只简单介绍一下可以对字段进行计算。
例如:查询各学生的年龄(通过公式计算年龄)
select
sid, sname, year(curdate()) - year(sage) as sage
from student;四、结果呈现(order by)
- 和
excel一样,可以用多个字段排序 - 关键字
desc表示降序排列
例如:查询学生id和年龄,并先按照学号sid降序,再按照年龄sage升序排列
select
sid, sage
from student
order by sid desc, sage表的连接和其他常用关键字
一、表的连接
我们前面已经介绍过通过等值连接join实现两个及两个以上表的查询需求,sql表连接包括内连接、外连接和交叉连接,我们通过一个例子简单介绍三种连接的异同。
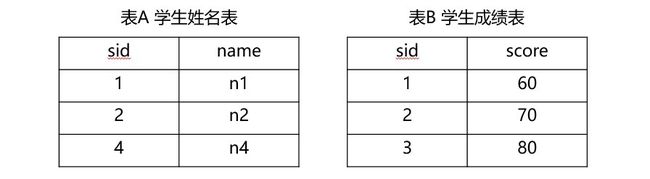
- 待连接的表的信息
现在有一张A表和B表,A表记录学生学号sid和对应的姓名name,B表记录学生学号sid和对应的分数score。
- 内连接
内连接即通过对某个字段进行等值匹配从而将两个表联合起来,比方说我们需要获取两张表中同一个学号对应的姓名和成绩,使用的就是inner join,结果如下:

- 左连接和右连接
一般情况下,“A表左连接B表”的结果与“B表右连接A表”的结果相同,为了保证
SQL代码的易阅读性,一般用左连接即可。
左连接指的是将左表作为基准表,保留表中的所有行,将右表根据某个字段进行等值匹配,如果找不到右表中匹配的行则显示为NULL。结果如下:

当然,还有全连接,在某些用途下也有用处,这里就不展开说了
- 交叉连接
没有连接条件的表连接将产生笛卡尔积,即连接结果行数等于A表行数乘上B表行数,可以理解为两个表的记录两两配对产生的结果。结果如下:

二、其他常用关键字
列举一些在
hive取数时常用的关键字。
case when
根据字段的不同值进行不同的操作,存在大量的变形操作可以实现不同的功能,最简单的情形如下:
# sex字段为1和2,现在要转化为更为直观的文字形式
case sex
when '1' then '男'
when '2' then '女'
else '未知'
end as sexcount+distinct+if实现统计
# 统计成绩单中及格同学的人数(单个学号可能出现多条记录)
count(distinct(if(score >= 60,sid,null)))sum+if实现分组统计(这里sum可以替换为其他聚合函数)
# 获取男性学生的总成绩
sum(if(sex = '男', score, 0))写在最后
整理了一下思维导图

作者:TOMOCAT
- 现在注册滴滴云,得10000元立减红包
- 8月特惠,1C2G1M云服务器 9.9元/月限时抢
- 滴滴云使者专属特惠,云服务器低至68元/年
- 输入大师码【7886】,GPU全线产品9折优惠
