利用 AutoML 进行时间序列预测

文 / Chen Liang 和 Yifeng Lu,Google Research Brain 团队软件工程师
时间序列预测是机器学习 (ML) 重要的研究领域,对于零售、供应链、能源、金融等准确预测至关重要的行业而言更是如此。举例来说,在消费品领域,需求预测的准确率每提高 10-20%,就可以减少 5% 的库存并增加 2-3% 的收入。
目前基于 ML 的预测解决方案通常由专家打造,且需要在模型构建、特征工程和超参数调整等方面投入大量的人力。不过,这类专业知识可能无法大规模应用,这就限制了在时间序列预测挑战中应用 ML 会带来的好处。
为解决这个问题,自动化机器学习 (AutoML) 通过创建 ML 模型过程的自动化实现 ML 的使用范围扩展,并于近期加快了 ML 研究及 ML 在现实问题中的应用。
例如,我们最初将其应用于神经架构搜索,带来了计算机视觉层面的突破,如 NasNet、AmoebaNet 和 EfficientNet,同时还在自然语言处理方面取得了进展,如 Evolved Transformer。最近,我们还对表格式数据应用了 AutoML。
神经架构搜索
https://ai.googleblog.com/2017/05/using-machine-learning-to-explore.html
今天,我们将介绍一种针对时间序列预测的端到端可扩展 AutoML 解决方案,它符合以下三个重要标准:
完全自动化:该解决方案将接受的数据作为输入,并生成可使用的 TensorFlow 模型作为输出,整个过程无需人工干预。
通用:该解决方案适用于大多数时间序列预测任务,并会自动为每项任务找寻最佳的模型配置。
高质量:与那些专为特定任务而人工构建的模型相比,该解决方案生成的模型质量更具竞争力。
TensorFlow
https://tensorflow.google.cn/
我们在参加 M5 预测比赛时证明了这种方法的可行性。与人工构建的模型相比,AutoML 解决方案生成的模型在性能方面更具竞争力,计算成本也适中。
M5 预测比赛
https://mofc.unic.ac.cy/m5-competition/
时间序列预测面临的挑战
时间序列预测为机器学习模型带来了一些挑战。
首先,因为时间序列预测的目标是根据历史数据预测未来,所以通常具有很高的不确定性。与其他机器学习所遇到的问题不同,测试集(如未来的产品销售情况)可能会与从历史数据提取的训练集和验证集的分布有所不同。
其次,现实世界的时间序列数据经常存在数据缺失和间歇性高的问题,(如当大多数时间序列值都为 0 时)。一些时间序列任务可能没有可用的历史数据,并且存在冷启动问题,如预测新产品销售情况。
最后,因为我们的目标是构建完全自动化的通用解决方案,同一解决方案需要应用于不同的数据集,所以可能会在领域(产品销售情况、网络流量等)、粒度(每日、每小时等)、历史长度和特征类型(分类、数字、日期时间等)等方面存在显著差异。
AutoML 解决方案
为应对这些挑战,我们设计了端到端的 TensorFlow 流水线,其中包含专为时间序列预测打造的搜索空间。该流水线基于编码器-解码器架构。编码器将时间序列中的历史信息转换成一组向量,而解码器则会根据这些向量生成对未来的预测。受 SOTA 序列模型(如 Transformer 和 WaveNet)和时间序列预测中最佳做法的启发,我们的搜索空间包括注意力、扩张卷积、决断、跳过连接以及不同的特征变换等组件。生成的 AutoML 解决方案将搜索这些组件和核心超参数的最佳组合。
Transformer/注意力
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.htmlWaveNet/扩张卷积
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
为消除预测未来时间序列的不确定性,可通过搜索发现的顶级模型集合进行最终预测。顶级模型的多样性使得预测在面对不确定性时更加稳健,更不容易过拟合历史数据。为处理时间序列数据缺失问题,我们用可训练的向量填补数据缺口,并教会模型适应缺失的时间步长。为解决间歇性问题,我们不仅会预测未来每个时间步长的值,同时还会预测该时间步长下值不为零的概率,然后将这两步预测结合到一起。最后,我们发现自动搜索可以根据不同的数据集调整架构和超参数选项,从而使得 AutoML 解决方案普遍适用并将建模工作自动化。

在预测比赛中进行基准化分析
为对 AutoML 解决方案进行基准化分析,我们参加了 M 比赛系列中最新举办的 M5 预测比赛。这是预测社区最为重要的比赛之一,有着近 40 年的悠久历史。最近的比赛在 Kaggle 上举办,使用的是来自 Walmart 产品销售情况的数据集。由于数据集来自现实世界,这导致解决该问题颇具挑战。
M5 预测比赛
https://mofc.unic.ac.cy/m5-competition/Kaggle 上
https://www.kaggle.com/c/m5-forecasting-accuracy/overview
我们用完全自动化的解决方案参加了本次比赛。最终排行榜显示,我们在 5558 名参赛者中排名第 138 位(前 2.5%),位列银牌区。参赛者有将近四个月的时间来构建模型。参与这场比赛的许多预测模型都需要几个月的人力工作来构建,但我们的 AutoML 解决方案在很短的时间内就找到了适用模型,并且计算成本适中(2 小时 500 个 CPU),也没有人工干预。
最终排行榜
https://www.kaggle.com/c/m5-forecasting-accuracy/leaderboard
我们还在其他几个 Kaggle 数据集上对 AutoML 预测解决方案进行了基准化分析。结果证实,尽管使用的资源有限,但平均而言,其性能表现要优于 92% 的人工构建模型。
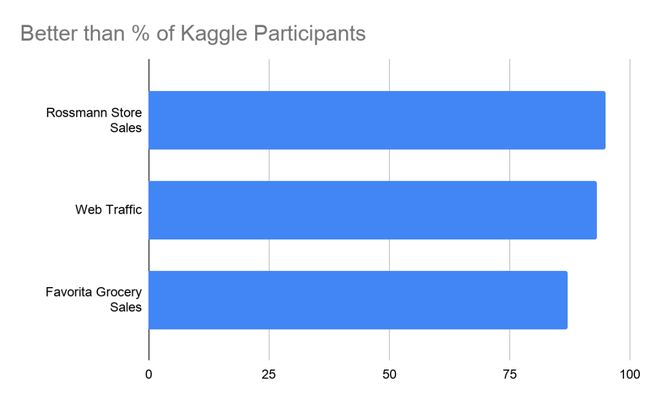
对 M5 以外的其他 Kaggle 数据集(Rossman Store Sales、Web Traffic 和 Favorita Grocery Sales)应用 AutoML 预测解决方案的评估
这项工作证明了针对时间序列预测的端到端 AutoML 解决方案的有效性,我们期待该解决方案能在未来为现实世界应用带来更多影响。
致谢
此项目是 Google Brain 团队成员 Chen Liang、Da Huang、Yifeng Lu 和 Quoc V. Le 共同努力的结果。同时还要感谢 Junwei Yuan、Xingwei Yang、Dawei Jia、Chenyu Zhao、Tin-yun Ho、Meng Wang、Yaguang Li、Nicolas Loeff、Manish Kurse、Kyle Anderson 和 Nishant Patil 的倾力合作。
更多 AI 相关阅读:
大型语言模型中的隐私考量
推出 Pr-VIPE:识别图像和视频中的姿态相似度
基于端到端可迁移深度强化学习的图优化
智能滚动:让转录后的文本编辑、共享和搜索更容易
Vision Transformer:用于大规模图像识别的 Transformer
![]()
