Python爬虫之scrapy框架使用详解
文章目录
- Python爬虫之scrapy框架使用详解
-
- 1. scrapy框架命令
- 2. scrapy项目文件结构
-
- 2.1 sample_spider
- 2.2 itmes
- 2.3 middlewares
- 2.4 pipelines
- 2.5 settings
- 2.6 main
Python爬虫之scrapy框架使用详解
1. scrapy框架命令
<<全局命令>>(全局命令可以在任何地方使用)
1. scrapy startproject <project_name> # 创建爬虫项目
2. scrapy genspider [-t template] <name> <domain> # 创建爬虫文件
3. scrapy runspider <spider_file.py> # 直接通过运行.py文件来启动爬虫
4. scrapy shell [url] # 打开scrapy-shell交互器(可以使用Selector进行调试)
5. scrapy fetch <url> # 该命令会通过scrapy-downloader将网页的源代码下载并显示出来
6. settings # 查看项目设置
7. version # 查看版本
8. view # 该命令会将网页document内容下载下来,并且在浏览器显示出来(可以判断是否是Ajax请求)
<<项目命令>>(项目命令只能在项目目录下使用)
1. scrapy crawl <spider> # 启动爬虫程序
2. scrapy list # 显示项目中所有的爬虫
3. check # 用于检查代码是否有错误
4. edit # 编辑
5. parse # 解析调试
6. bench # 速度测试
<<创建示例>>(如果命令显示无效,在命令前面加上“python -m”)
1. scrapy startproject example # 创建名字为example的项目
2. cd example # 切换到该项目
3. scrapy genspider sample_spider www.sample.com # 创建名字为sample_spider的爬虫文件,并且初始域名为www.sample.com
4. scrapy crawl sample # 执行sample爬虫程序
5. scrapy crawl sample -o sample.json # 保存输出结果到json文件(还有csv,xml,pickle,marshal,ftp等格式可以存取)
scrapy crawl sample --nolog # 不打印日志
scrapy crawl sample --headers # 打印响应头信息
scrapy crawl sample --no-redirect # 不做跳转(禁止重定向)
<<shell调试>>
python3 -m scrapy shell
response.selector.xpath('')
response.selector.css('')
2. scrapy项目文件结构
创建一个名叫example的scrapy项目,并且添加一个sample_spider.py
文件结构如下:
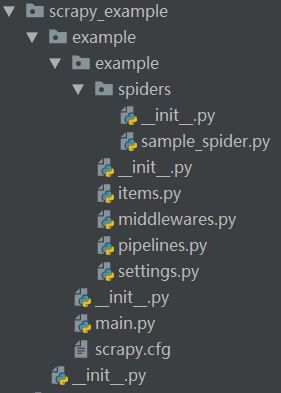
接下来对scrapy项目内的每个文件进行讲解
使用方法都写在程序里面的注释中,请尽情享用,如果您觉得不错可以点个赞哦
2.1 sample_spider
"""Spider类基础属性和方法
属性: 含义:
name 爬虫名称,它必须是唯一的,用来启动爬虫
allowed_domains 允许爬取的域名,是可选配置
start_urls 起始URL列表,当没有重写start_requests()方法时,默认使用这个列表
custom_settings 它是一个字典,专属与本Spider的配置,此设置会覆盖项目全局的设置,必须在初始化前被更新,必须定义成类变量
spider 它是由from_crawler()方法设置的,代表本Spider类对应的Crawler对象,可以获取项目的全局配置信息
settings 它是一个Settings对象,我们可以直接获取项目的全局设置变量
方法: 含义:
start_requests() 生成初始请求,必须返回一个可迭代对象,默认使用start_urls里的URL和GET请求,如需使用POST需要重写此方法
parse() 当Response没有指定回调函数时,该方法会默认被调用,该函数必须要返回一个包含Request或Item的可迭代对象
closed() 当Spider关闭时,该方法会被调用,可以在这里定义释放资源的一些操作或其他收尾操作
Request属性:
meta 可以利用Request请求传入参数,在Response中可以取值,是一个字典类型
cookies 可以传入cookies信息,是一个字典类型
dont_filter 如果使用POST,需要多次提交表单,且URL一样,那么就必须设置为True,防止被当成重复网页过滤掉
"""
# -*- coding: utf-8 -*-
import scrapy
from ..items import ExampleItem
from scrapy.http import Request, FormRequest
from scrapy import Selector
__author__ = 'Evan'
class SampleSpider(scrapy.Spider):
name = 'sample_spider' # 项目名称,具有唯一性不能同名
allowed_domains = ['quotes.toscrape.com'] # 允许的domain range
start_urls = ['http://quotes.toscrape.com/'] # 起始URL
"""更改初始请求,必须返回一个可迭代对象
def start_requests(self):
return [Request(url=self.start_urls[0], callback=self.parse)]
or
yield Request(url=self.start_urls[0], callback=self.parse)
"""
def parse(self, response):
"""
当Response没有指定回调函数时,该方法会默认被调用
:param response: From the start_requests() function
:return: 该函数必须要返回一个包含 Request 或 Item 的可迭代对象
"""
# TODO Request attribute
# print(response.request.url) # 返回Request的URL
# print(response.request.headers) # 返回Request的headers
# print(response.request.headers.getlist('Cookie')) # 返回Request的cookies
# TODO Response attribute
# print(response.text) # 返回Response的HTML
# print(response.body) # 返回Response的二进制格式HTML
# print(response.url) # 返回Response的URL
# print(response.headers) # 返回Response的headers
# print(response.headers.getlist('Set-Cookie')) # 返回Response的cookies
# json.loads(response.text) # 获取AJAX数据,返回一个字典
# TODO 使用Selector选择器
# selector = Selector(response=response) # 选择Response初始化
# selector = Selector(text=div) # 选择HTML文本初始化
# selector.xpath('//a/text()').extract() # 使用xpath选择器解析,返回一个列表
# selector.xpath('//a/text()').re('Name:\s(.*)') # 使用xpath选择器 + 正则表达式解析,返回正则匹配的分组列表
# selector.xpath('//a/text()').re_first('Name:\s(.*)') # 使用xpath选择器 + 正则表达式解析,返回正则匹配的第一个结果
# TODO 从settings.py中获取全局配置信息
# print(self.settings.get('USER_AGENT'))
quotes = response.css('.quote') # 使用css选择器,返回一个SelectorList类型的列表
item = ExampleItem()
for quote in quotes:
# ::text 获取文本
# ::attr(src) 获取src属性的值
item['text'] = quote.css('.text::text').extract_first() # 返回匹配到的第一个结果
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract() # 返回一个包含所有结果的列表
yield item
next_url = response.css('.pager .next a::attr("href")').extract_first() # 返回下一页的URL
url = response.urljoin(next_url) # 拼接成一个绝对的URL
yield Request(url=url, callback=self.parse) # 设置回调函数,循环检索每一页
2.2 itmes
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ExampleItem(scrapy.Item):
"""
定义数据结构
"""
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
2.3 middlewares
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import random
from scrapy import signals
class RandomUserAgentMiddleware(object):
"""
自定义类
"""
def __init__(self):
self.user_agents = [
# Chrome UA
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/73.0.3683.75 Safari/537.36',
# IE UA
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
# Microsoft Edge UA
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'
]
def process_request(self, request, spider):
"""
生成一个随机请求头
:param request:
:param spider:
:return:
"""
request.headers['User-Agent'] = random.choice(self.user_agents)
class ExampleSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spider.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
"""
当 Response 被 Spider MiddleWare 处理时,会调用此方法
:param response:
:param spider:
:return:
"""
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
"""
当 Spider 处理 Response 返回结果时,会调用此方法
:param response:
:param result:
:param spider:
:return:
"""
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
"""
以 Spider 启动的 Request 为参数被调用,执行的过程类似 process_spider_output(),必须返回 Request
:param start_requests:
:param spider:
:return:
"""
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ExampleDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spider.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
"""
在发送请求到 Download 之前调用此方法,可以修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等功能
:param request:
:param spider:
:return: 如果返回的是一个 Request,会把它放到调度队列,等待被调度
"""
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
"""
在发送 Response 响应结果到 Spider 解析之前调用此方法,可以修改响应结果
:param request:
:param response:
:param spider:
:return: 如果返回的是一个 Request,会把它放到调度队列,等待被调度
"""
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
"""
当 Downloader 或 process_request() 方法抛出异常时,会调用此方法
:param request:
:param exception:
:param spider:
:return: 如果返回的是一个 Request,会把它放到调度队列,等待被调度
"""
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
2.4 pipelines
# -*- coding: utf-8 -*-
import pymongo
from scrapy.exceptions import DropItem
class TextPipeline(object):
"""
自定义类
"""
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
"""
必须要实现的方法,Pipeline会默认调用此方法
:param item:
:param spider:
:return: 必须返回 Item 类型的值或者抛出一个 DropItem 异常
"""
if item['text']:
if len(item['text']) > self.limit: # 对超过50个字节长度的字符串进行切割
item['text'] = item['text'][:self.limit].rstrip() + '...'
return item
else:
raise DropItem('Missing Text') # 如果抛出此异常,会丢弃此Item,不再进行处理
class MongoPipeline(object):
"""
自定义类
"""
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.client = None
self.db = None
@classmethod
def from_crawler(cls, crawler):
"""
Pipelines的准备工作,通过crawler可以拿到全局配置的每个配置信息
:param crawler:
:return: 类实例
"""
# 使用类方法,返回带有MONGO_URI和MONGO_DB值的类实例
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'), # MONGO_URI的值从settings.py获取
mongo_db=crawler.settings.get('MONGO_DB') # MONGO_DB的值从settings.py获取
)
def open_spider(self, spider):
"""
当 Spider 开启时,这个方法会被调用
:param spider:
:return:
"""
self.client = pymongo.MongoClient(self.mongo_uri) # 打开Mongodb连接
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
"""
必须要实现的方法,Pipeline会默认调用此方法
:param item:
:param spider:
:return: 必须返回 Item 类型的值或者抛出一个 DropItem 异常
"""
name = item.__class__.__name__ # 创建一个集合,name='ExampleItem'
self.db[name].update_one(item, {
"$set": item}, upsert=True) # 数据去重
return item
def close_spider(self, spider):
"""
当 Spider 关闭时,这个方法会被调用
:param spider:
:return:
"""
self.client.close() # 关闭Mongodb连接
2.5 settings
# -*- coding: utf-8 -*-
# Scrapy settings for example project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'example'
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# TODO 设置默认的用户代理请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36'
# Obey robots.txt rules
# TODO 不请求Robots协议
ROBOTSTXT_OBEY = False
# TODO 设置编码格式
FEED_EXPORT_ENCODING = 'utf-8' # 在json格式下转换中文编码
# FEED_EXPORT_ENCODING = 'gb18030' # 在csv格式下转换中文编码
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# TODO 如果设置为True则可以手动添加Cookies参数到Request请求中
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'example.middlewares.ExampleSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# TODO 使用下载中间件,设置随机请求头
DOWNLOADER_MIDDLEWARES = {
'example.middlewares.RandomUserAgentMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# TODO 使用项目管道,过滤和保存数据(字典的value越小,优先级越高,如下所示:300优先级 > 400优先级)
ITEM_PIPELINES = {
'example.pipelines.TextPipeline': 300,
'example.pipelines.MongoPipeline': 400,
}
# TODO Mongodb配置
MONGO_URI = 'localhost'
MONGO_DB = 'example'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2.6 main
在编写完所有scrapy代码后,创建一个main.py来启动scrapy (直接运行main.py即可)
# -*- coding=utf8 -*-
from scrapy import cmdline
# TODO 执行爬虫指令
cmdline.execute("scrapy crawl sample_spider".split()) # 执行sample_spider爬虫
cmdline.execute("scrapy crawl sample_spider -o sample.json".split()) # 执行爬虫并在当前目录下生成一个sample.json文件(该文件是爬虫结果)